 AIGeo
AIGeo
# AIGeo
“ 一个专注于人工智能和地理信息科学(GIS,也称为地理信息系统)交叉的子领域。”
# 基本概念
# GIS
什么是 GIS? | 地理信息系统制图技术 (esri.com) (opens new window)
GIS是地理信息系统(Geographic Information System)的缩写。它是一种特定的十分重要的空间信息系统。它是在计算机硬、软件系统支持下,对整个或部分地球表层(包括大气层)空间中的有关地理分布数据进行采集、储存、管理、运算、分析、显示和描述的技术系统。
GIS能够在一张地图上显示许多不同类型的数据,如街道、建筑物和植被。这使人们更容易看到、分析和理解模式和关系²。GIS技术通过工具将地理科学用于理解和协作。它可以帮助人们达到共同的目标:从所有类型的数据中获得可执行的情报。
GIS应用领域极其广泛,但是主要分为三大类:地图观,数据库观和空间分析观。
数据是GIS的基础,也就是所说的地理信息。
GIS中使用的数据通常分为两大部分,一部分是地图部分,即显示出来的区域,比如普查数据会有按照普查区划分好的地图呈现,另一部分是数据部分,也叫做Attribute Table。这个表格更像我们所想象的“数据”该有的样子,打开之后像是excel的形式。
GIS中常用的数据分为两类,矢量数据(Vector)和栅格数据(Raster),两种数据在不同的应用场景之中都会有不同的作用。
# 相关工作/参考资料
# On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence(2023)
# Autonomous GIS(2023)
Autonomous GIS: the next-generation AI-powered GIS gladcolor/LLM-Geo (github.com) (opens new window)
【个人理解】
核心功能是数据可视化,区分于[其他数据分析工作](如:Is GPT-4 a Good Data Analyst?),GIS可视化依赖于地图(需要区域位置信息)
在实现中,依赖LLM生成python代码,并执行产生可视化结果。因为需要加载地图数据(如.shp)并在要在地图上进行可视化,使用Geopandas库来处理地图数据(可视化)
例如(取自论文):
问题:“生成一张地图,显示美国北卡罗来纳州(NC)地块层面的人口空间分布,并突出显示有危险废物设施的地块的边界。”
数据:
NC区域边界(ESRI shape file/地图信息)
NC危险废物设施(ESRI shape file/地图信息)
NC地区人口(csv文件)
生成代码:
# Main program
# Step 1: Load data
haz_waste_gdf = load_haz_waste_shp()
nc_tract_gdf = load_nc_tract_shp()
nc_tract_pop_df = load_nc_tract_pop_csv()
# Step 2: Join NC tract data with population data
nc_tract_pop_gdf = join_tract_pop(nc_tract_gdf, nc_tract_pop_df)
# Step 3(这一步可忽略): Calculate total population within tracts containing hazardous waste facilities
total_pop_within_tracts = calculate_pop_within_tracts(haz_waste_gdf, nc_tract_pop_gdf)
print("Total population within tracts containing hazardous waste facilities:", total_pop_within_tracts)
# Step 4: Generate and save map
population_map = generate_map(haz_waste_gdf, nc_tract_pop_gdf)
population_map.get_figure().savefig("population_map.png", dpi=300, bbox_inches="tight")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
可视化结果:
数据1就是这个地区的地图,数据3在地图上的可视化就是’人口空间分布‘,对应到下图中黄色到蓝色的渐变。数据2是危险废物设施,依据地图可获得对应边界,即下图中各个小红圈。
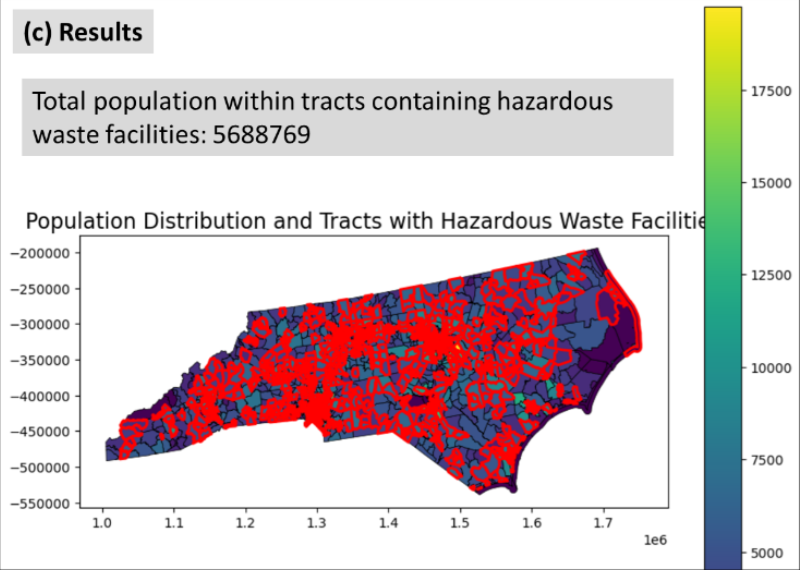
【AutoGIS简单理解就是处理跟地图相关的数据、在地图上做可视化分析】
# 论文概要
大型语言模型(LLM),如ChatGPT,展示了对人类自然语言的深刻理解,并在推理、创造性写作、代码生成、翻译和信息检索等各个领域得到了探索和应用。通过采用LLM作为推理核心,我们引入了自主GIS作为一种人工智能驱动的地理信息系统(GIS),它利用LLM在自然语言理解、推理和编码方面的一般能力,通过自动空间数据收集、分析和可视化来解决空间问题。
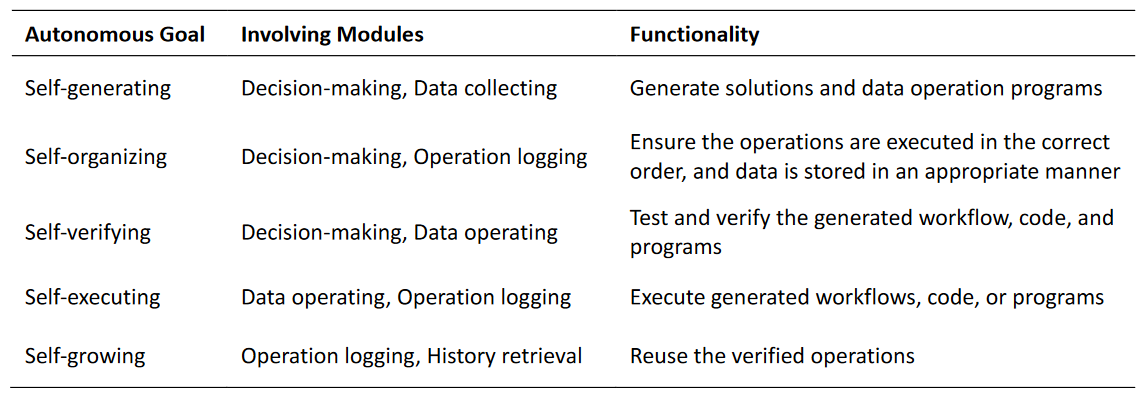
Autonomous GIS需要实现五个自主目标:自我生成、自我组织、自我验证、自我执行和自我成长。
在Python环境中使用GPT-4 API开发了一个名为LLM-Geo的原型系统,通过三个案例研究,展示了Autonomous GIS的外观以及它如何在无需人工干预的情况下实现预期结果。对于所有案例研究,LLM-Geo都能够返回准确的结果,包括汇总的数字、图表和地图,大大减少了手动操作时间。
不足: 尽管LLM-Geo仍处于起步阶段,缺乏日志记录和代码测试等几个重要模块,但它展示了一条通往下一代人工智能驱动的GIS的潜在道路。
# GeoAI发展
近年来,地理信息科学界一直将人工智能纳入地理空间研究和应用,从而产生了GeoAI,这是一个专注于人工智能和地理信息科学交叉的子领域。尽管GeoAI在将人工智能用于空间数据处理和挖掘等各种地理空间应用方面取得了重大进展,但在空间分析和GIS中探索和采用人工通用智能(AGI)(例如,LLM作为AGI的早期阶段)仍处于早期阶段。Mai等人 (opens new window)(2023)探讨了为GeoAI开发类似LLM的基础模型的机遇和挑战。最近,赵(2022)根据地理信息系统与人类、地理信息系统和地点的关系(距离),将地理信息系统分为四类:体现型地理信息系统、解释学地理信息系统,自治地理信息系统以及背景地理信息系统。赵认为,自主地理信息系统“要么是一个独立的代理,要么就是一个地方”,例如无人机、机器人吸尘器和自主车辆,或者是经过训练识别图像中的陆地物体(例如建筑物)的模型。其他尝试包括在QGIS中使用LLM来自动化简单的数据操作(例如,加载)(Kyriakou 2023;Mahmood 2023),或者采用预先训练的模型来分割图像。
# LLM-Geo与Autonomous GIS两个概念区分
LLM-Geo是Autonomous GIS的原型实现
Autonomous GIS应设计为一个以编程和数据为中心的框架,以使用自动编码来解决确定性的地理信息科学问题。
为了证明Autonomous GIS的可行性,作者开发了一个名为LLM-Geo的概念验证原型,它可以以自主的方式进行空间分析。
LLM-Geo从用户接收任务(空间问题/问题),并通过将任务分解为连续的连接数据操作作为有向无环图来生成解决方案图(地理处理工作流)。每个操作都是LLM要实现的功能,LLM在本研究中是GPT-4。接下来,LLM-Geo通过集成所有操作的代码来生成组合程序,并执行组合程序以产生任务的最终结果。
# Autonomous GIS
定义/功能: 自主系统设计用于在没有人为干预的情况下做出决策和执行任务。他们可以适应不断变化的条件,从环境中学习,并根据收集的数据做出明智的决定。通过将LLM(或AGI)作为制定解决空间问题的战略和步骤的决策核心,自主GIS将能够从广泛的现有在线地理空间数据目录中搜索和检索所需的空间数据,或从传感器收集新数据,然后使用现有的空间算法、模型,或工具(或开发新的工具)来处理收集的数据以生成最终结果,例如地图、图表或报告。LLM是自主GIS的“大脑”,如果配备了环境传感器,则是“头”,而可执行程序(例如Python)可以被视为其数字“手”。
自主GIS需要五个关键模块,包括决策(LLM为核心)、数据收集、数据操作、操作日志和历史检索。这些模块使GIS能够实现五个自主目标:自生成、自组织、自验证、自执行和自增长。
确定性核心: 与许多用于非确定性任务的自主代理不同,这些任务没有严格的标准来评估这些答案,例如写诗,GIScience应用需要空间数据的定量计算和分析来提供答案。确定性系统,如GIS,是指在给定足够的初始条件和控制其行为的基本规则信息的情况下,可以精确预测系统未来状态的系统。 在确定性系统中,初始条件和结果之间存在直接关系,没有随机性或不确定性的空间。
从这个意义上说,Autonomous GIS需要一种严格可控和可解释的答案方法,并且这种答案应该是唯一的,并且基于给定的数据在数量上是正确的。因此,我们建议将自主GIS设计为一个以编程为中心的框架,使用自动编码来解决GIS科学的问题。
# LLM-Geo
我们在LLM-Geo中实现了自主GIS的两个关键模块:决策和数据操作,实现了三个自主目标:自生成、自组织和自执行。目前正在开发其他模块。
决策模块采用LLM(本研究中为GPT4)作为核心,或“大脑”,生成逐步解决的工作流程,并开发每个步骤的相关代码,以解决各种空间问题。
数据操作模块是一个Python环境,用于执行生成的代码,如空间数据加载、处理、可视化和保存。
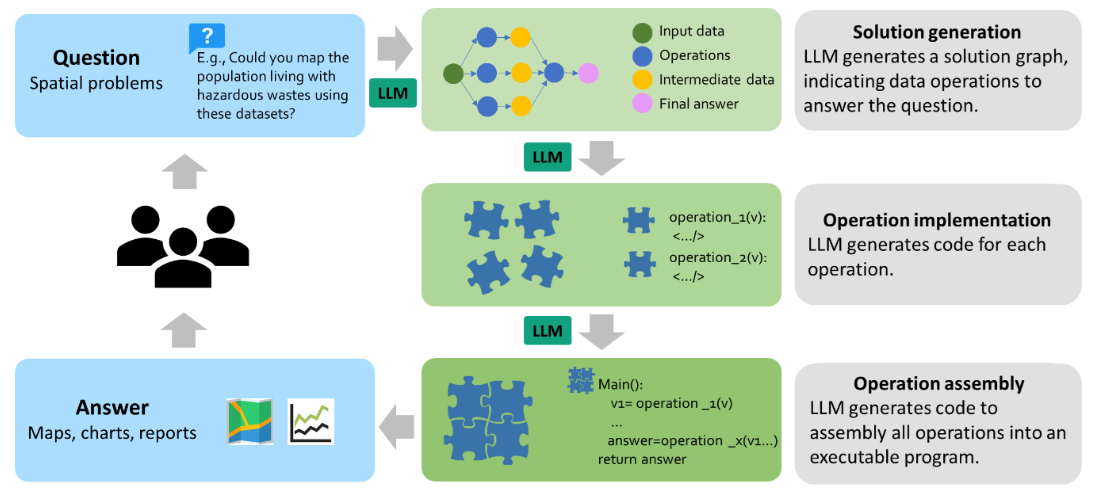
下图显示了LLM-Geo如何回答问题的总体工作流程:
首先由用户输入空间问题以及相关的数据位置,例如在线数据URL、REST(REpresentational State Transfer)服务和API(Application Program Interface)文档。
然后,LLM生成一个类似于地理处理工作流的解决方案图。
基于解决方案图,LLM-Geo向LLM发送每个操作节点的需求,请求代码实现。
LLM-Geo然后收集所有操作代码实现,并要求LLM生成一个基于工作流连接操作的汇编程序。
最后,LLM-Geo执行汇编程序以产生最终答案。
# Solution generation
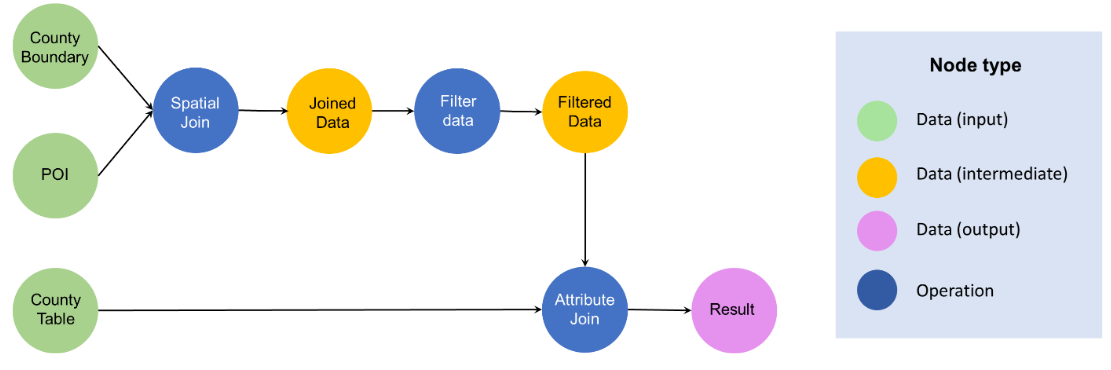
LLM-Geo中的解决方案是指由一系列连接的操作和数据组成的数据处理工作流。执行这些操作以连续处理数据会生成问题的最终结果,例如地图、图表、表格和新的空间数据集。我们使用有向图来表示工作流,并将所有节点分为两类:数据和操作。
数据节点是指操作的输入数据或输出数据,由三种类型组成:输入数据节点、中间数据节点和输出数据节点。输入数据节点告诉系统在哪里通过本地数据路径、URL或RESTAPI加载输入数据以进行编程数据访问。输出节点是任务或问题的最终结果,可以是数字数据、交互式或静态地图、表格/图表、新数据集或其他用户请求的类型。所有其他数据节点都被视为中间数据节点。
操作节点是通过输入和输出操作数据的过程。其输入可以是输入数据节点,也可以是来自祖先操作节点的中间数据节点。它的输出可以是派生操作节点的中间数据节点,也可以是输出节点(最终结果)。有向边表示数据流。
解决方案图中不允许出现断开连接的节点,因为所有数据流都需要在输出节点聚合才能产生最终结果。解决方案图的这些结构约束通过API与用户的问题一起提供给LLM(GPT-4)。由于空间分析本质上是一个由一系列连接的空间数据处理任务组成的地理处理工作流程,因此解决方案图确保数据在处理步骤中无缝流动,最终汇聚到最终结果。
实验表明,操作节点的粒度是由LLM根据问题的复杂性和支持的最大令牌长度动态确定的。由于令牌长度的限制,LLM可能难以将复杂的任务分解为详细的图,从而导致具有较低粒度和较少节点的解决方案图。由于当前所有LLM都有令牌限制(包括GPT-4等最先进的模型),因此这种实际约束需要对复杂任务采用递归方法。这种方法可以将操作节点进一步分解为包含更细粒度操作的子解决方案图,直到粒度达到用于精确代码生成和可重用性的适当级别。
解决方案图的提示:
提示(注意:蓝色文本中指示的空间问题是用户唯一需要的输入,其他文本在LLM-Geo中预定义)
">Your role: A professional Geo-information scientist and developer good at Python. Task: Generate a graph (data structure) only, whose nodes are (1) a series of consecutive steps and (2) data to solve this question:
1) Find out the total population that lives within a tract that contain hazardous waste facilities. The study area is North Carolina, US.
2) Generate a map to show the spatial distribution of population at the tract level and highlight the borders of tracts that have hazardous waste facilities.
Data locations (each data is a node):
1. NC hazardous waste facility ESRI shape file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/Hazardous_Waste_Sites.zip.
2. NC tract boundary shapefile location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/tract_shp_37.zip. The tract id column is 'Tract'.
3. NC tract population CSV file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/NC_tract_population.csv. The population is stored in 'TotalPopulation' column. The tract ID column is 'GEOID'.
Your reply needs to meet these requirements:
1. Think step by step.
2. Steps and data (both input and output) form a graph stored in NetworkX. Disconnected components are NOT allowed.
3. Each step is a data process operation: the input can be data paths or variables, and the output can be data paths or variables.
4. There are two types of nodes: a) operation node, and b) data node (both input and output data). These nodes are also input nodes for the next operation node.
5. The input of each operation is the output of the previous operations, except the those need to load data from a path or need to collect data.
6. You need to carefully name the output data node.
7. The data and operation form a graph.
8. The first operations are data loading or collection, and the output of the last operation is the final answer to the task. Operation nodes need to connect via output data nodes, DO NOT connect the operation node directly.
9. The node attributes include: 1) node_type (data or operation), 2) data_path (data node only, set to "" if not given , and description. .g., {‘name’: “Count boundar ”, “data_t pe”: “data”, “data_path”:” :\Test\count .shp”, “description”: “Count boundar for the stud area”}.
10. The connection between a node and an operation node is an edge.
11. Add all nodes and edges, including node attributes to a NetworkX instance, DO NOT change the attribute names.
12. DO NOT generate code to implement the steps.
13. Join the attribute to the vector layer via a common attribute if necessary.
14. Put your reply into a Python code block, NO explanation or conversation outside the code block (enclosed by ```python and ```).
15. Note that GraphML writer does not support class dict or list as data values.
16. You need spatial data (e.g., vector or raster) to make a map.
17. Do not put the GraphML writing process as a step in the graph.
18. Save the network into GraphML format, save it at: E:\Research\LLMGeo\Resident_at_risk_counting\Resident_at_risk_c ounting.graphml
Reply example:
# in-context learning
import networkx as nx
G = nx.DiGraph()
# Add nodes and edges for the graph
# 1 Load hazardous waste site shapefile
G.add_node("haz_waste_shp_url", node_type="data", path="https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/Hazardous_Waste_Sites.zip", description="Hazardous waste facility shapefile URL")
G.add_node("load_haz_waste_shp", node_type="operation", description="Load hazardous waste facility shapefile")
G.add_edge("haz_waste_shp_url", "load_haz_waste_shp")
G.add_node("haz_waste_gdf", node_type="data", description="Hazardous waste facility GeoDataFrame")
G.add_edge("load_haz_waste_shp", "haz_waste_gdf")
2
3
4
5
6
7
8
9
10
# Operation implementation
生成的解决方案图用作指定空间问题的“数据处理计划”,其中输入数据、输出数据和数据操作是预定义的。在操作实现阶段,每个操作都将按照解决方案图中的操作定义实现为可执行代码片段。我们在LLM-Geo中使用Python运行时作为数据操作模块,因此操作实现是通过LLM生成Python代码。LLM-Geo使用一种算法在节点之间创建接口,以确保操作节点和数据节点连接到其相邻节点。例如,LLM-Geo的当前版本为每个操作生成一个Python函数;函数定义和返回数据(即函数名称和函数输入/输出变量)在解决方案图中预定义。此策略用于减少代码生成的不确定性。
根据我们的实验,GPT-4需要足够的信息和额外的指导来生成可靠的代码。在这种情况下,可能需要与当前操作节点之前的解决方案图路径相关的所有信息。例如,祖先节点可能会创建一个新的列或文件,LLM在为当前操作节点生成函数代码时必须知道并使用该列和文件的名称。此外,还需要有关子节点的信息来指导代码生成过程。因此,LLM-Geo将祖先节点中生成的代码和后代节点的信息提供给LLM,以请求每个操作节点的代码实现。除了节点信息,还需要额外的指导。例如,我们发现GPT-4对一些空间数据操作的先决条件有模糊的记忆,例如用于表连接的相同列数据类型和用于覆盖分析的相同映射投影。
GPT-4已经学会使用GeoPandas,这是一个用于空间数据处理的流行Python库;然而,它似乎没有意识到这个库不支持对offly的重新投影。在这种情况下,LLM需要额外的指导来为操作节点生成正确的代码实现。
提供了操作的提示和LLM返回代码的示例:
提示为一个操作生成函数(请注意,此提示由LLM-Geo根据问题和预定义的指导自动生成):
Your role: A professional Geo-information scientist and developer good at Python. operation_task: You need to generate a Python function to do: Join tract GeoDataFrame with population DataFrame
This function is one step to solve the question: 1) Find out the total population that lives within a tract that contains hazardous waste facilities. The study area is North Carolina, US.
2) Generate a map to show the spatial distribution of population at the tract level and highlight the borders of tracts that have hazardous waste facilities.
Data locations: 1. NC hazardous waste facility ESRI shape file location: https://github.com/gladcolor/LLM- Geo/raw/master/overlay_analysis/Hazardous_Waste_Sites.zip.
2. NC tract boundary shapefile location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/tract_shp_37.zip. The tract id column is 'Tract'.
3. NC tract population CSV file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/NC_tract_population.csv. The population is stored in 'TotalPopulation' column. The tract ID column is 'GEOID'.
Reply example:
def Load_csv(tract_population_csv_url="https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/NC_tract_population.csv"):
# Description: Load a CSV file from a given URL
# tract_population_csv_url: Tract population CSV file URL
tract_population_df = pd.read_csv(tract_population_csv_url)
return tract_population_df
2
3
4
5
Your reply needs to meet these requirements:
1. The function description is: Join tract GeoDataFrame with population DataFrame
2. The function definition is: join_tract_pop(nc_tract_gdf=nc_tract_gdf, nc_tract_pop_df=nc_tract_pop_df)
3. The function return line is: return nc_tract_pop_gdf
......
The descendant function definitions for the question are (node_name is function name):
{'node_name': 'calculate_pop_within_tracts',
'description': 'Calculate total population within tracts containing hazardous waste facilities',
'function_definition': 'calculate_pop_within_tracts(haz_waste_gdf=haz_waste_gdf, nc_tract_pop_gdf=nc_tract_pop_gdf)',
'return_line': 'return total_pop_within_tracts'}
{'node_name': 'generate_map',
'description': 'Generate the map showing spatial distribution of population and highlighting borders of tracts with hazardous waste facilities',
'function_definition': 'generate_map(haz_waste_gdf=haz_waste_gdf, nc_tract_pop_gdf=nc_tract_pop_gdf)',
'return_line': 'return population_map'}
# Operation assembly
在为所有操作节点生成代码(函数)后,LLM-Geo收集代码并将其与解决方案图和预定义指南一起提交给LLM,以创建任务的最终程序。基于该指导,LLM使用解决方案图来确定最终程序中操作节点的执行顺序。生成中间变量以存储操作节点的输出数据,然后将这些数据馈送到后续操作节点。最后,LLM-Geo执行汇编程序,生成空间问题的最终结果。
包括一个汇编程序的提示:
Your role: A professional Geo-information scientist and developer good at Python.
Your task is: use the given Python functions, return a complete Python program to solve the question:
1) Find out the total population that lives within a tract that contains hazardous waste facilities. The study area is North Carolina, US.
2) Generate a map to show the spatial distribution of population at the tract level and highlight the borders of tracts that have hazardous waste facilities.
Requirement:
1. You can think step by step.
2. Each function is one step to solve the question.
3. The output of the final function is the question to the question.
4. Put your reply in a code block (enclosed by ```python and ```), NO explanation or conversation outside the code block.
5. Save final maps, if any.
6. The program is executable.
Data location:
1. NC hazardous waste facility ESRI shape file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/Hazardous_Waste_Sites.zip.
2. NC tract boundary shapefile location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/tract_shp_37.zip. The tract id column is 'Tract'.
3. NC tract population CSV file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/NC_tract_population.csv. The population is stored in 'TotalPopulation' column. The tract ID column is 'GEOID'.
Code:
Operation code generation输出
# 概括
基于GPT-4 API的LLM-Geo的整个实现结构和工作流程详细如下所示,与前面框架区别是加入了提示输入:

# 案例介绍
Case 1: Counting population living near hazardous wastes.
这个空间问题是找出生活在危险废物中的人口并绘制其分布图。研究区域为美国北卡罗来纳州。我们将任务(问题)输入LLM-Geo,如框所示。
Task:
1) Find out the total population that lives within a Census tract that contain hazardous waste facilities. The study area is North Carolina, US.
2) Generate a map to show the spatial distribution of population at the tract level and highlight the borders of tracts that have hazardous waste facilities.
Data locations:
1. NC hazardous waste facility ESRI shape file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/Hazardous_Waste_Sites.zip
2. NC tract boundary shapefile location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/tract_shp_37.zip. The tract ID column is 'Tract'
3. NC tract population CSV file location: https://github.com/gladcolor/LLMGeo/raw/master/overlay_analysis/NC_tract_population.csv. The population is stored in 'TotalPopulation' column. The tract ID column is 'GEOID'
这个问题要求LLM-Geo找出生活在危险废物中的总人口,并生成一张人口分布图,其中包含足够的分析细节,包括数据位置和使用的列名。请注意,矢量层(危险设施和地块边界)不在同一地图投影中,地块ID数据类型为边界层中的文本,但Pandas读取人口CSV文件时为整数。GPT-4有模糊的内存来预处理这些不一致,因此LLM-Geo需要在提示中用额外的指导来提醒GPT-4:“在进行空间分析时,将所涉及的层转换为相同的映射投影。在连接表时,将涉及的列转换为不带前导零的字符串类型。”
下图显示了LLM-Geo在本案例研究中的输出,包括详细说明数据处理步骤的解决方案图、最终组装Python程序、,以及该问题的最终结果:居住在含有危险废物设施的地区内的总人口(5688769人),以及一张显示人口普查地区一级人口空间分布的地图,并突出显示有危险废物设施地区的边界。我们的人工核实证实了数字和地图的准确性。使用LLM-Geo生成的工作代码,用户可以根据需要轻松调整和重新运行代码,以自定义地图可视化样式。
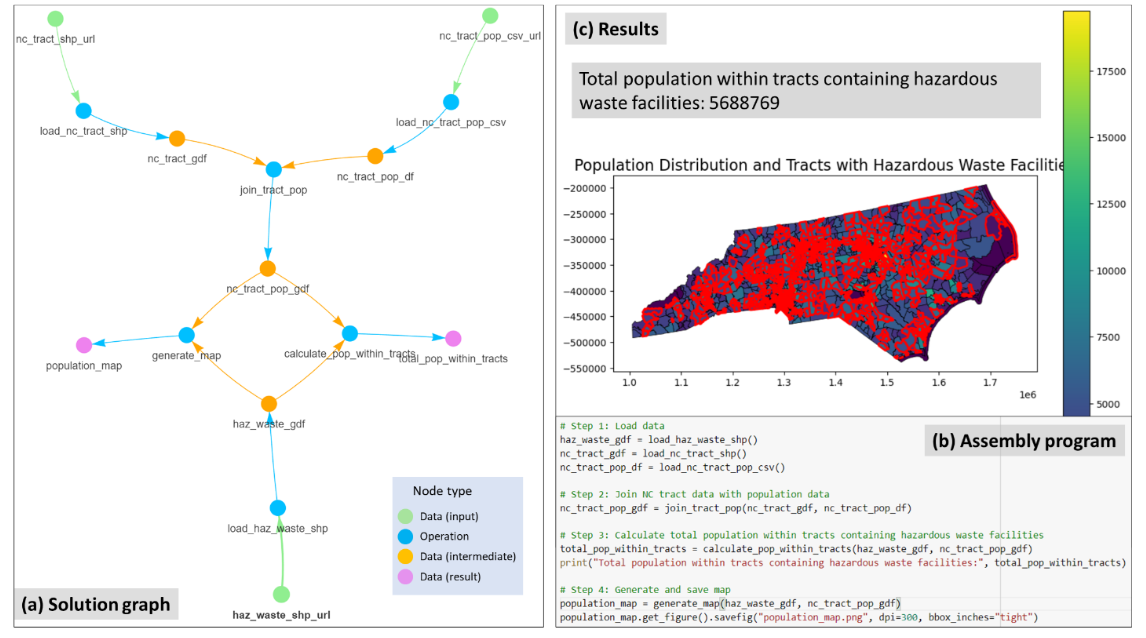
# 讨论和经验教训
# Autonomous GIS的形式
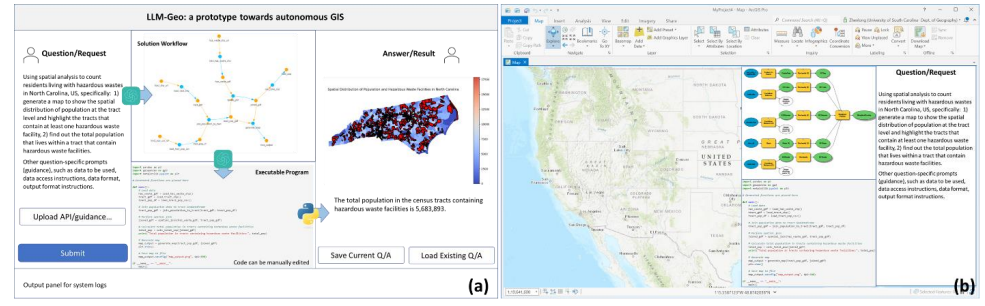
(a)可以作为一个独立的应用程序(本地或基于云的)发挥作用,充当GIS分析师,接受用户的问题并给出答案。这种应用程序的一个潜在图形用户界面(GUI)如下图(a)所示,用户在其中输入空间问题的描述,单击Submit按钮,然后直接在应用程序中接收结果。应用程序还应该能够显示生成的解决方案图(地理处理工作流)和可执行代码,这些代码产生最终结果,用于监控、调试和自定义目的。通过积累和重用生成的代码和工作流,特别是为许多用户服务的云版本,自主GIS的能力可以快速增长。
(b)集成在现有GIS软件(例如ArcGIS Pro),作为传统GIS软件的Copilot,使用自然语言与用户交流,自动化空间数据处理和分析任务。
例如,地图视图旁边的自主GIS面板可以集成到ArcGIS和QGIS中,显示聊天框、生成的解决方案图和代码,如下图(b)所示。结果将显示在内置的地图视图中。用户可以通过编辑解决方案图或操作参数来修改工作流。如果操作是由生成的代码实现的,用户可以通过单击解决方案图节点来定位和编辑代码。总体而言,解决方案图类似于ArcGIS的模块生成器或QGIS中的模型设计器。
基于现有GIS平台实现Autonomous GIS可能是目前最实用、最高效的方法,因为成熟的GIS平台(如ArcGIS)已经有了丰富的操作(如ArcGIS工具箱中的工具),以及LLM可以快速学习和使用的成熟文档来生成解决方案图。更广泛地说,自主地理信息系统可以作为一个“插件”与需要地理空间数据操作的应用程序集成,例如新冠肺炎或其他疾病的公共卫生监测仪表板。这样一个支持GIS的自主仪表板将能够使用自然语言与用户互动,根据用户的具体需求和偏好生成定制的地图、图表、报告和新的数据集。这种级别的交互和定制允许用户在各种应用程序中使用地理空间数据时获得更个性化和高效的体验。
# Autonomous GIS与AI助手区别
市场上有各种由LLM支持的人工智能助手。它们利用LLM生成代码和注释来提高程序员的生产力。微软Office系列的Copilot能够自动完成报告编写和幻灯片创建等办公任务。
Autonomous GIS与这些人工智能助手的区别在于输入、最终产品以及生成结果的确定性和以数据为中心的工作流程。人工智能助手通常接收文本并为用户生成基于文本的内容,如段落或代码。相比之下,地理信息系统分析的输入是空间数据,对其进行进一步处理,以得出定量结果(如地图、图表),从而支持决策。
# 分而治之
当面对复杂的任务时,人类解决问题的策略通常采用分而治之的策略。通过在LLM-Geo的设计中采用这种方法,旨在通过将复杂问题分解为LLM可以处理的更小、更易于管理的子问题(即操作)来解决空间分析任务。 它系统地解决这些子问题(即为每个子问题开发一个函数),并最终组合这些函数(即组装一个程序)以产生最终结果。这种分而治之的方法已被用于其他数字自主代理,如AutoGPT和AgentGPT。我们计划进一步探讨这种方法的可行性,处理比迄今为止所展示的任务更复杂的任务。此外,分而治之策略有助于生成经过验证的操作节点(例如,代码片段)。这些经过验证的子解决方案(操作)成为自主GIS的宝贵资产。
# GIS和LLM中对足够信息的需求
如前所述,GIS本质上是确定性的,只要对其启动条件和控制其运行的规则有足够的了解,就可以精确预测其未来状态。在这些确定性系统中,结果与它们的初始条件有着内在的联系,没有留下随机性或不确定性的空间。在确定性系统中,充足的信息至关重要,因为它有助于准确预测和理解系统的行为。 对于GIS来说,空间分析通常面临数据可用性、管辖范围边界和地图大小等限制。此外,数据元数据或细节,如层投影、字段名称和数据类型,对于后续的空间编程至关重要。就像人类分析师一样,自主GIS需要意识到这些约束和信息,才能成功完成给定的任务。
例如,在没有列名的先验知识的情况下无法执行属性联接操作,或者在没有关于层投影的信息的情况下进行叠加分析。因此,我们认为,提供足够的信息是自主GIS准确推理、任务规划和行动执行的必要和充分条件。提供此类信息的可能方法包括数据采样、网络搜索、自我反思和手动提供。
# 回忆LLM的朦胧记忆
LLM可以通过合并附加信息来校正先前的错误输出。他们理解完成任务所需的步骤,但往往忽略了空间分析中的实际约束,例如重叠分析中匹配地图投影的必要性,以及两个属性表的公共连接列的精确数据类型匹配。LLM中的这种“模糊”记忆可能是有限的GIS培训材料造成的。为了增强LLM对这些模糊记忆的回忆,从而提高其成功推理和编码的能力,在任务描述中嵌入必要的提醒至关重要。尽管不同LLM和训练数据集之间这种模糊的空间分析记忆可能存在差异,但制定一个相对通用的提醒列表以帮助自主GIS产生准确的结果是可行的。该列表的功能类似于GIS用户的检查表。
例如,在空间分析任务中,GIS用户必须确保公共连接列具有相同的数据类型(字符串或int)和前导零位数。经验丰富的GIS用户通常会提前验证这些先决条件,而新手可能会忽略这些步骤,直到他们遇到错误或查阅检查表。本指南或检查表的具体内容因用户而异(例如,经验丰富的GIS用户的具体内容更短),自主GIS的具体内容也因所用LLM的复杂程度而异。
# 限制和未来工作
虽然LLM-Geo验证了自主GIS的概念,但它仍处于起步阶段,存在许多局限性,例如无法调试生成的或处理光栅数据。LLM中推理能力的出现将GIScience社区带到了一个新时代的黎明,但仍有大量的机会需要探索和挑战需要解决。我们已经确定了几个潜在的进一步研究和开发途径,以解决LLM-Geo的现有限制,并为未来全面运行的自主GIS奠定基础。
LLM-Geo的适应性有待提高
需要一个内存系统
GIS社区维护的分类指南
试错,一种更稳健的解决问题的方法
在线地理空间数据发现和过滤
回答‘为什么’问题
构建大型空间模型(LSM)
LLM接受了大量文本语料库的培训,已经发展了语言技能、知识和推理能力,但由于这些语料库中缺乏空间样本,他们的空间意识仍然有限。地理信息科学中的许多资源,如丰富的历史遥感图像、全球矢量数据、基础设施和属性的详细记录,以及大量其他地理空间大数据源,尚未完全纳入大型模型的训练中。 考虑在所有可用的空间数据上训练的大型空间模型(LSM)的潜力,反映了在广泛的文本语料库上训练LLM的方式。这样的模型可能对地球表面有详细的了解,准确地描述任何位置,并理解生态系统和地球圈的动力学。这不仅丰富了未来人工通用智能的空间意识,还可以改变地理信息科学领域,使自主地理信息系统能够回答“为什么”的问题。我们主张进一步研究和努力训练能够更准确地代表地球表面和人类社会的大型空间模型。
# GPT4GEO(2023)
GPT4GEO: How a Language Model Sees the World's Geography
# ArcGIS
# QGIS
https://github.com/qgis/QGIS