 人体姿态估计
人体姿态估计
# 人体姿态估计综述
# 介绍
人体姿态估计(HPE)是计算机视觉领域中一项基础性和挑战性的任务。它旨在从图像或视频中预测人体姿势信息,如人体关节的空间位置和/或身体形状参数。HPE已被广泛用于许多计算机视觉任务,如人的重新识别、人的解析、行为识别和人机交互等。
在视频中,如果我们不仅需要获得所有帧中每个人的姿态,还想确定哪些姿态来自同一个人,那么这项任务也被称为姿态跟踪。
# 分类
根据输出结果的空间维度,主流HPE任务可分为两类:2D人体姿态估计和3D人体姿态估计。2D人体姿态估计也称为2D关键点检测,旨在从图像中定位人体解剖关键点(身体关节)的2D坐标。此外,给定视频序列,2D姿态估计可以利用时间信息来增强视频系统中的关键点预测。与仅预测身体关节的2D位置不同,3D姿态估计进一步预测深度信息以获得更精确的空间表示。在该过程中,可以利用2D姿态估计作为3D姿态估计的中间表示。近年来,对理解人类的详细姿势信息的需求推动了3D姿势估计不仅预测3D位置,而且预测详细的3D形状和身体纹理。
根据图像中的人数,人体姿态估计可分为单人人体姿态估计方法、 多人人体姿态估计方法。
多人人体姿态估计划分为:自顶向下的方法与自底向上的方法
根据方法和输出的基本原理,又可分为基于回归的方法与基于热图的方法、基于人体模型的方法与无模型方法、多阶段方法与端到端方法。
# 先进模型
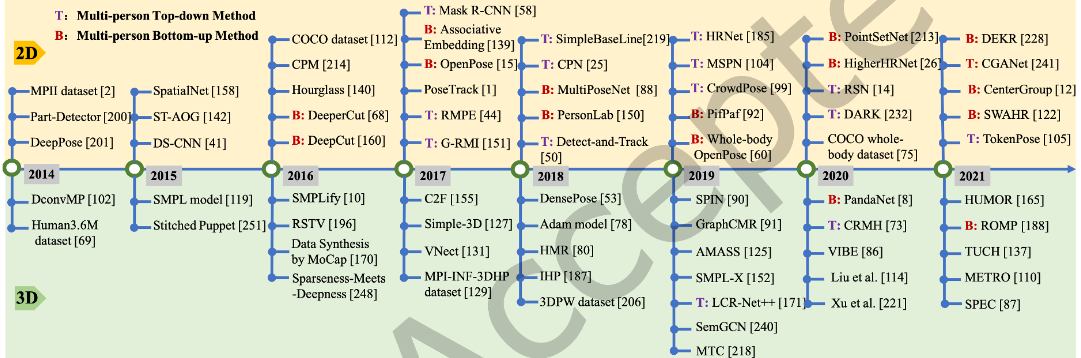
人体姿态估计发展时间线,其中显示了2014至2021期间的里程碑、想法或数据集突破,以及2D和3D位姿估计的最先进方法。
# MHPE框架
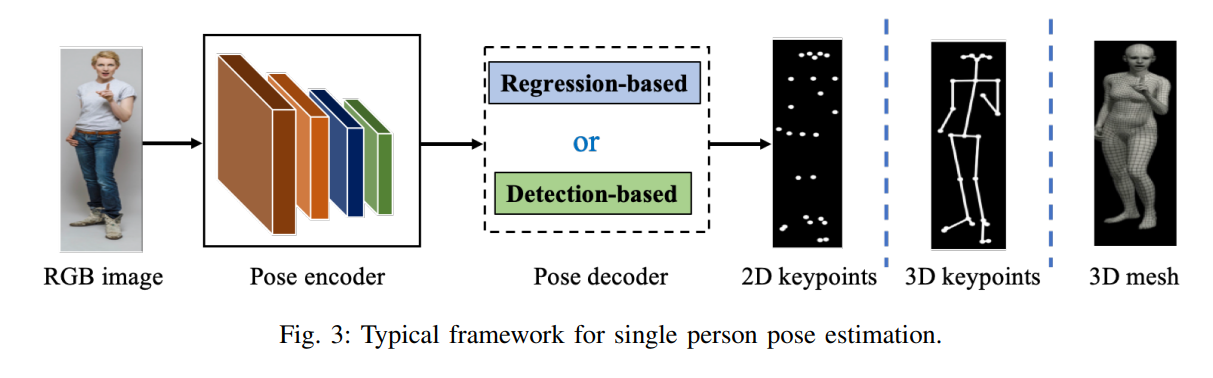
大多数流行的单人姿态估计网络可被视为由姿态编码器(也称为特征提取器)和姿态解码器组成。前者的目标是通过从高分辨率到低分辨率的过程来提取高层特征。后者以基于检测或基于回归的方式估计目标输出、2D/3D关键点位置或3D网格。
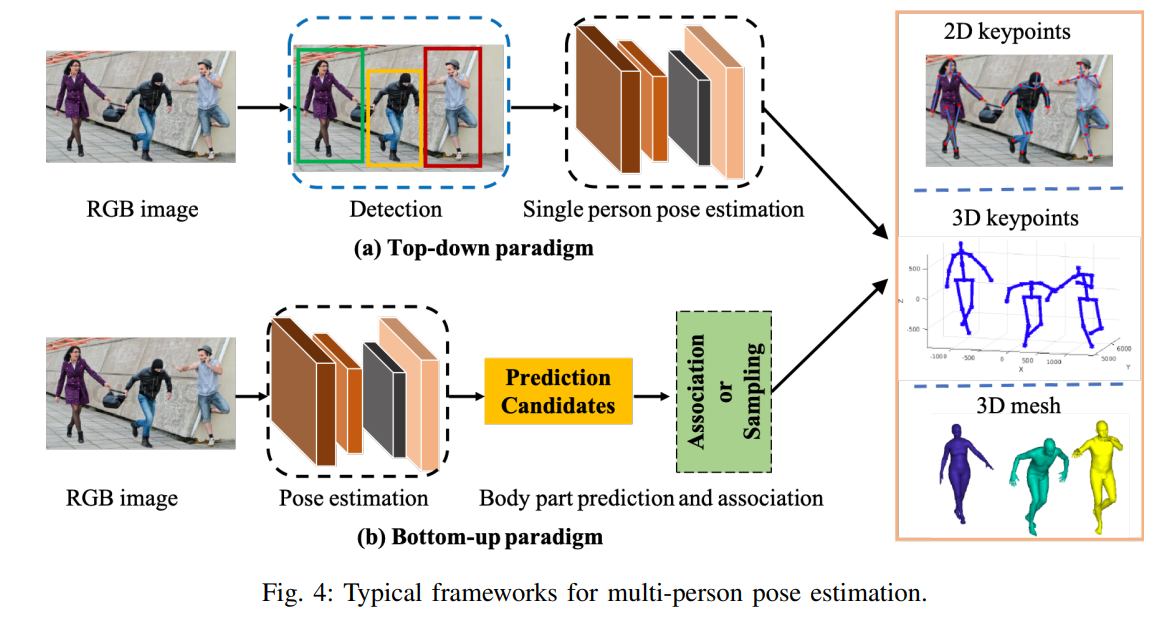
对于多人场景,为了估计每个人的2D或3D姿态,现有作品采用自上而下或自下而上的模式。自上而下的框架首先检测人物区域,然后从中提取边界框级别的特征。这些特征用于估计每个人的姿态结果。相比之下,自下而上的范式首先检测所有目标输出,即人体骨骼点位置,然后通过分组将它们分配给不同的人。这两种模式也依赖于基于姿态编码器和解码的架构,网络输入要么是检测到的边界框,要么是整个图像。
# 人体建模
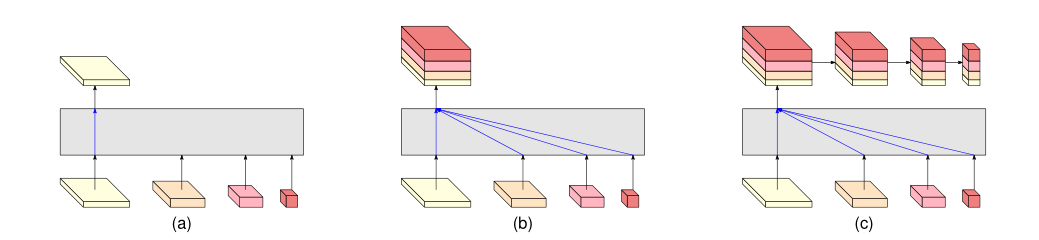
人体建模是HPE的一个重要方面,用于表示从输入数据中提取的关键点和特征。例如,大多数HPE方法使用𝑁 -joints为刚性运动学模型。人体是具有关节和四肢的复杂实体,包含人体运动学结构和体形信息。在许多方法中,基于模型的方法用于推断和渲染2D/3D人体姿态。人体建模通常有三种类型的模型:kinematic model (used for 2D/3D HPE), planar model(used for 2D HPE) and volumetric model (used for 3D HPE)
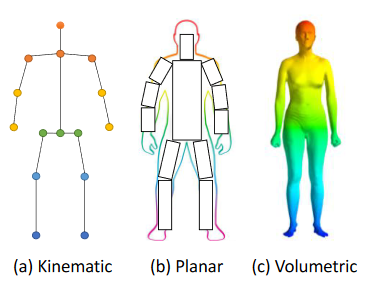
Kinematic model:运动学模型使用一组关节位置和肢体方向来表示人体结构(见图a)。图形结构模型(PSM)是一种广泛使用的图形模型,也称为树结构模型。这种灵活直观的人体模型已成功应用于2D HPE和3D HPE。尽管运动学模型具有灵活的图形表示的优点,但它在表示纹理和形状信息方面受到限制。
Planar model:除了用于捕捉不同身体部位之间关系的运动学模型之外,平面模型还用于表示人体的形状和外观,如图(b)所示。在平面模型中,身体部位通常由近似人体轮廓的矩形表示。一个例子是纸板模型,它由代表人四肢的身体部分矩形形状组成。另一个例子是Active Shape Model(ASM),该模型广泛用于使用主成分分析捕获整个人体图和轮廓变形。
volumetric model:随着对3D人体重建的兴趣的增加,已经针对各种人体形状提出了许多体积人体模型(图(c))。SMPL(Skinned Multi-Person Linear)模型是3D HPE中广泛使用的模型,可以用表现出软组织动力学的自然姿态相关变形建模。为了了解人们如何随姿势变形,SMPL中使用模板网格对姿势的不同对象进行了1786次高分辨率3D扫描,以优化混合权重、姿态相关混合形状、平均模板形状和从顶点到关节位置的回归。还有其他流行的体积模型,如DYNA, Stitched Puppet model, Frankenstein & Adam, and GHUM & GHUML(ite) 。
SMPL是一种骨架驱动的人体模型。SMPL分离人体的形状和姿态,并将3D网格编码为低维参数。它建立了一个有效映射
。从形状β和姿态θ到带有6890个顶点的三角网格,其中Φ表示人体的统计先验。形状参数
是10种基本形状的线性组合权重。姿态参数
表示轴角度表示中23个关节的相对三维旋转。然后基于线性回归
,通过J=M(β,θ;Φ)R,从人体网格的6890个顶点中推导预选的身体关节$J∈R^{3×24} $。该回归器的线性组合运算保证关节位置相对于形状β和姿态θ参数是可微的。
# 挑战和对策探讨
如何设计有效的姿态编码器和姿态解码器架构是人体姿态估计中常见和流行的话题。
与分类、检测和语义分割不同,人体姿态估计需要处理身体部位之间的细微差异,尤其是在不可避免的截断、拥挤和遮挡情况下。为了实现这一点,社区已经探索和设计了身体结构模型、多尺度特征融合、多级管道、从粗到精的细化、多任务学习等。
此外,对于单目图像的三维姿态估计,研究人员必须处理由于野生三维训练数据不足而导致的不可避免的挑战。由于设备的限制,常用的三维姿态数据集通常在受限的实验环境中捕获。例如,最广泛使用的3D姿势数据集Human3.6M仅包含7人进行的15项室内活动。因此,人体姿势、形状和场景的多样性极为有限。仅在这些数据集上训练的模型容易在野外图像上失败。为了解决这个问题,许多方法将2D姿态作为中间表示或额外监督,并从野生2D姿态信息中学习。然而,在该过程中存在固有的模糊性,即,单个2D姿态可能对应于多个3D姿态,反之亦然。为了解决固有的模糊性,方法应考虑如何充分利用人体的结构先验、运动连续性和多视图一致性。
对于单目RGB图像和视频的3D HPE,主要挑战是深度模糊。在多视图设置中,视点关联是需要解决的关键问题。一些工程使用了深度传感器、惯性测量单元(IMU)和射频设备等传感器,但这些方法通常不具成本效益,需要专用硬件。
# 论文集合
- zczcwh/DL-HPE (github.com) (opens new window)
- wangzheallen/awesome-human-pose-estimation: Human Pose Estimation Related Publication (github.com) (opens new window)
# 解读
- 基于深度学习的单目2D/3D姿态估计综述(2021) - 知乎 (zhihu.com) (opens new window)
- 重新思考人体姿态估计 Rethinking Human Pose Estimation - 知乎 (zhihu.com) (opens new window)
# 综述工作
# Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective(2022 ACM Computing Surveys)
整理&翻译
# 单目2D人体姿态估计
具有代表性基于深度学习的2D人体姿态估计方法
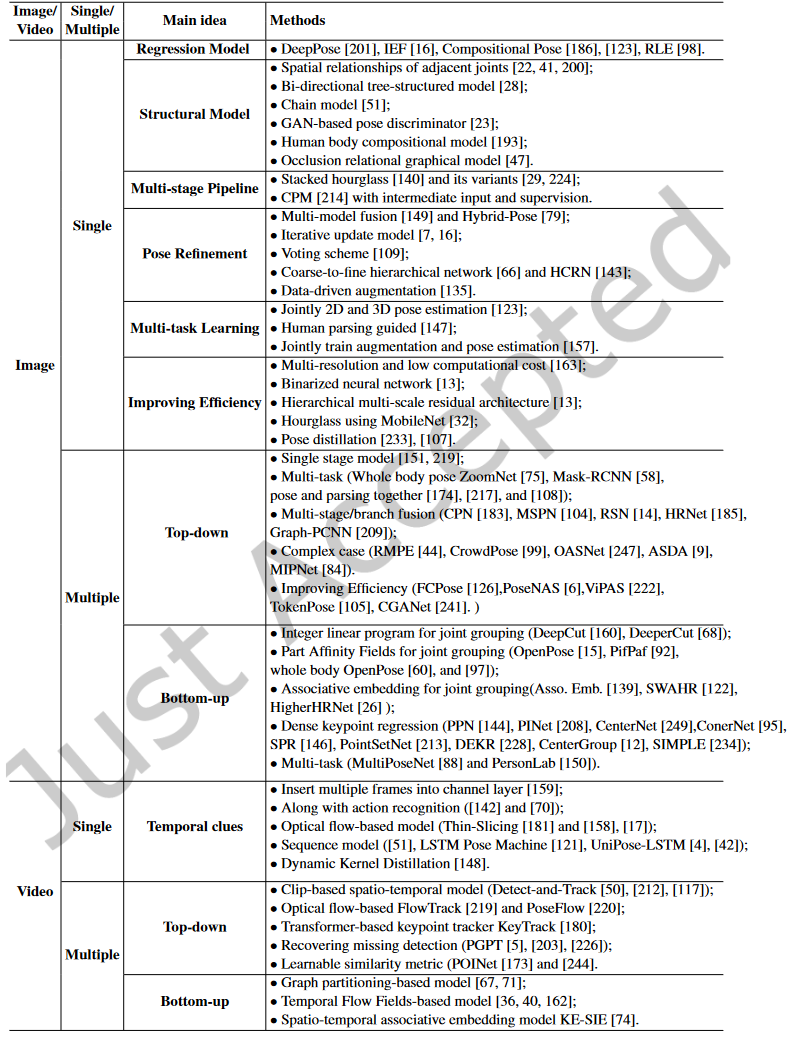
典型的单人姿势估计方法的框架可以被表示为由姿势编码器和姿势解码器组成。姿态编码器是提取高级特征的骨干,而姿势解码器以基于回归的方式或基于检测的方式产生关键点的2D位置。大多数位姿编码器基于图像分类网络,如ResNet,在大型数据集(如ImageNet)上具有预训练模型。相反,一些工作设计了任务特定的姿势编码器。例如,堆叠沙漏网络利用跳跃连接层以相同分辨率连接镜像特征。此外,PoseNAS利用神经架构搜索(NAS)方法来查找任务驱动的可搜索特征提取器块。最近的大部分工作都集中在姿势解码器的设计上,它越来越注重探索上下文信息和身体结构的固有特征。
# 基于RGB图片
# Regression Model
DeepPose,这是最早的基于深度卷积神经网络(DCNNs)的人体姿态估计方法之一,将关键点估计公式化为一个回归问题。
DeepPose: Human pose estimation via deep neural networks(2014 CVPR)
IEF:迭代误差反馈(Iterative Error Feedback)网络利用了自校正回归模型。这是一种自上而下的反馈,以逐步改变初始关键点预测。
Human Pose Estimation with Iterative Error Feedback(2016 CVPR)
CHP提出了合成姿态回归,即身体结构感知。
Compositional human pose regression(2017 ICCV)
最近的工作探索了残差对数似然估计(RLE),以捕获姿态回归的输出分布的变化,而不是未参考的基础分布。
Human Pose Regression With Residual Log-Likelihood Estimation(2021 ICCV)
由于大多数基于回归的方法直接将图像映射到身体关节的坐标,因此它们可能会陷入非线性问题,并在复杂姿势下失败。相反,基于检测的姿势解码器生成关键点的热图,这在现有方法中已广泛使用。
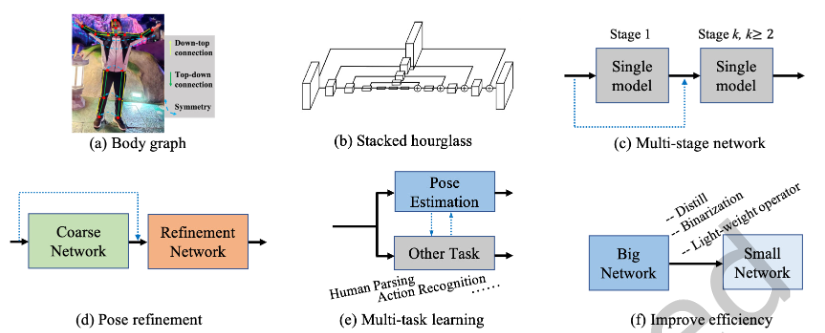
# Structural Body Model
(上图a)除了基于DCNN的全身特征表示外,还探索了图形模型,以描述具有空间关系的结构和局部部位。
[200] 通过一种混合DCNN架构提出了卷积网络部分检测器。他们将身体部位的空间位置分布描述为类似马尔可夫随机场的模型,这有助于消除解剖学上不正确的姿态预测。
Joint training of a convolutional network and a graphical model for human pose estimation(2014 NeurIPS)
[22] 使用DCNN学习身体部位存在的条件概率及其在图像块中的空间关系。
Articulated pose estimation by a graphical model with image dependent pairwise relations(2014 NeurIPS)
[28] 首先在特征层面上研究部位之间的关系。提出的端到端学习框架通过可学习的几何变换核和双向树结构模型来获取人体关节之间的结构信息。
Structured feature learning for pose estimation(2016 CVPR)
[51] 提出了一个链式序列到序列模型,除了依赖于关于关节条件分布的任何假设之外,以基于之前预测的所有身体部位顺序预测每个身体部位。
Chained predictions using convolutional neural networks(2016 ECCV)
[23] 中的工作提出了一种结构感知网络,隐式利用人体的几何约束先验。它通过条件生成对抗网络(GANs)设计鉴别器来区分真实姿态和虚假姿态。
Adversarial posenet: A structure-aware convolutional network for human pose estimation(2017 ICCV)
[193] 提出了深入学习的组成模型(DLCM),进一步了解人体的组成性。该模型在多个语义层次上具有自下而上/自上而下的推理阶段。在自下而上阶段,较高级别的部分由其子级递归估计,而在自上而下阶段,较低级别的部分由其父级递归细化。
Deeply learned compositional models for human pose estimation(2018 ECCV)
[192] 建议学习相关部件的特定功能。此外,与手动定义的身结构关系不同,他们提出了一种数据驱动的方法,根据共享的信息量对相关部位进行分组。
Does learning specific features for related parts help human pose estimation(2019 CVPR)
[47]ORGM提出了一种遮挡关系图形模型来同时表示自遮挡和对象-人遮挡,该模型对人体部位和对象之间的交互进行了区分编码,用于处理遮挡问题。
Orgm: Occlusion relational graphical model for human pose estimation(2017 TIP)
# Multi-stage Pipeline
已经证明多阶段管道和多层次特征融合(上图c)对于捕捉人体细节非常有用。
[140]stacked hourglass network是代表性工作之一(上图b)。每个沙漏网络由自下而上处理(从高分辨率到低分辨率)和自上而下处理(从低分辨率到高分辨率)之间的对称分布组成。它使用带有跳跃层的单一管道,以在每个分辨率下保留空间信息。结合中间监控,整个网络连续地将多个沙漏模块堆叠在一起。
Stacked hourglass networks for human pose estimation(2016 ECCV)
[224] 提出将设计的金字塔残差模块插入沙漏网络, 该网络可以处理人体各部位之间的比例变化。
Learning feature pyramids for human pose estimation(2017 ICCV)
[29] 中的工作设计了沙漏剩余单元(HRU),以增加堆叠沙漏网络的接收场。同时,利用多上下文注意机制实现了从局部区域到全局语义一致空间的不同粒度表示。
Multi-context attention for human pose estimation(2017 CVPR)
[82] 为了利用结构信息和多分辨率特征,提出的方法利用了叠加沙漏框架上的多尺度监督、多尺度回归和结构感知损失。
Multi-scale structureaware network for human pose estimation(2018 ECCV)
[214]CPM使用中间输入和监督来学习隐式空间模型,而无需显式图形模型。它的顺序多级卷积结构日益完善对关键点位置的预测。
Convolutional pose machines(2016 CVPR)
# Pose Refinement
对网络输出进行细化可以提高最终的姿态估计性能。(上图d)显示了普通粗精加工管道的框架。
[149] 建立了一个多源深度模型,从不同的信息源中提取非线性表示,包括视觉外观评分、外观混合类型和变形。所有信息源的表示被融合去进行姿态估计。可以将其视为姿态估计结果的后处理。
Multi-source deep learning for human pose estimation(2014 CVPR)
[16] 中的工作使用了一个迭代更新模块来逐步改进姿态估计。
Human pose estimation with iterative error feedback(2016 CVPR)
[7] 引入了一种递归卷积神经网络,以迭代提高性能。
Recurrent human pose estimation(2017 FG)
[109] 提出了一种最佳姿态配置投票方案,其中图像中的每个像素都投票选择每个关键点的最佳位置。
Human pose estimation using deep consensus voting(2016 ECCV)
[66] 提出了一个由多个分支组成的精细层次网络。通过对多分辨率特征图的多级监控,多个分支被统一起来预测最终的关键点。
A coarse-fine network for keypoint localization(2017 ICCV)
[143]HCRN是一个层次化的上下文细化网络,在该网络中,不同复杂性的关键点在不同的层上进行处理。
Hierarchical contextual refinement networks for human pose estimation(2019 TIP)
[79] 混合姿态采用了两个分支的堆叠沙漏网络——用于姿态细化的细化网络(RNet)和用于姿态校正的校正网络(CNet)。RNet水平细化每个沙漏阶段的关键点位置。CNet以混合方式指导细化和融合热图。
Hybrid refinementcorrection heatmaps for human pose estimation(2020 TMM)
[135] 中的工作不同于为前端粗网络添加额外网络以进行端到端训练,它们采用了类似的细化策略,将RGB图像和粗略预测的关键点都作为输入。然后,细化网络通过联合推理输入输出空间,直接预测细化后的姿态。这种独立的细化网络采用数据驱动的增广训练,可以应用于任何现有的方法。
Learning to refine human pose estimation(2018 CVPRW)
Posefix: Model-agnostic general human pose refinement network(2019 CVPR)
# Multi-task Learning
(上图e)通过利用相关任务的补充信息,多任务学习可以为姿态估计提供额外的线索。
[123] 提出了一个多任务框架,用于从视频序列中联合进行2D/3D姿态估计和人体行为识别。
2d/3d pose estimation and action recognition using multitask deep learning(2018 CVPR)
[147] 中的方法使用人体部位解析学习者来利用部位分割信息,并提供补充特征来辅助姿态估计。
Human pose estimation with parsing induced learner(2018 CVPR)
[157] 中利用了对抗性数据扩充,以解决网络训练期间随机数据扩充的局限性。它还设计了一种奖惩策略,用于联合训练增强网络和目标(姿态估计)网络。
Jointly optimize data augmentation and network training: Adversarial data augmentation in human pose estimation(2018 CVPR)
# Improving Efficiency
随着模型性能的发展,如何提高模型的速度也引起了人们的广泛关注。(上图f)显示了提高模型效率的常用框架,包括使用轻量级算子、网络二值化、模型蒸馏等。
[163] 提出了一种低计算的多分辨率轻量级网络,探索了较低的计算要求。
An efficient convolutional network for human pose estimation(2016 BMVC)
[13] 中二值化神经网络首次被用来设计计算资源有限的轻量级网络。具体来说,基于对各种设计选择的详尽评估,提出了一种分层、并行和多尺度的剩余体系结构。
Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources(2017 ICCV)
[32] 中的方法研究了MobileNet和沙漏网络的结合,以设计一种轻量级的体系结构。
Adapting mobilenets for mobile based upper body pose estimation(2018 AVSS)
[233] 中的工作提出了一个快速姿态提取(FPD)模型,该模型基于知识蒸馏的思想训练一个高速姿态网络。
Fast human pose estimation(2019 CVPR)
OKDHP[107] 方法与两阶段姿态蒸馏框架不同,以一阶段方式研究在线知识蒸馏框架,以保证蒸馏效率。
Online Knowledge Distillation for Efficient Pose Estimation(2021 ICCV)
# Top-down
这种方法首先检测并裁剪图像中的每个人。然后,给定一个只包含一个人的裁剪图像块,他们使用单人姿态估计模型,然后进行后处理,如姿态非最大抑制(NMS),以预测每个人的最终关键点输出。理论上,前面中介绍的单人方法可以在裁剪图像块后应用。然而,与单人场景相比,多人场景需要处理截断、环境遮挡、人物遮挡和小目标。因此,有代表性的自上而下的方法不仅注重挖掘CNN的潜力,探索丰富的上下文信息融合或交换来设计网络,还注重复杂场景。🤔
Single stage model
(?Two Stage Pipeline)
[151] 提出了第一个基于深度学习的两阶段自上而下的管道,名为G-RMI,他们使用Faster RCNN检测器来检测每个人,然后利用完全卷积的ResNet来联合预测关键点的密集热图和偏移。他们还引入了基于关键点的NMS,而不是盒子级NMS,以提高关键点的可信度。
Towards accurate multi-person pose estimation in the wild(2017 CVPR)
[219] Simple BaseLine提供了一个简单有效的模型,该模型由一个ResNet主干和三个反卷积层组成,以提高空间分辨率。它表明,一个设计良好的简单自上而下的模型可以取得令人惊讶的效果。
Simple baselines for human pose estimation and tracking(2018 ECCV)
Multi-task
多任务学习:通过在姿态估计相关任务之间共享特征,多任务学习可以为姿态估计提供更好的特征表示。
[58]MaskRCNN可以检测人员边界框,然后裁剪相应提议的特征图,以预测人类关键点。
Mask r-cnn(2017 ICCV)
[75]ZoomNet将人体姿态估计器、手/脸检测器和手/脸姿态估计器统一到一个网络中。该网络首先定位身体关键点,然后放大手/脸区域,以预测具有更高分辨率的关键点。它可以处理人体不同部位之间的尺度差异。
Whole-body human pose estimation in the wild(2020 ECCV)
鉴于人类关键点和人类语义部分是相互关联和互补的,设许多工作计了多任务网络来联合预测关键点并分割语义部分。
Multi-task human analysis in still images: 2d/3d pose, depth map, and multi-part segmentation(2019 FG)
Joint multi-person pose estimation and semantic part segmentation(2017 CVPR)
Look into person: Joint body parsing pose estimation network and a new benchmark(2018 TPAMI)
Multi-stage/branch fusion
为了突破单一模型的瓶颈,提出了多阶段或多分支融合策略。
[25] 中的工作提出了级联金字塔网络(CPN),该网络由全局网络和细化网络组成,以逐步细化关键点预测。它还提出了一种在线硬关键点挖掘(OHKM)方法来处理硬关键点。
Cascaded pyramid network for multi-person pose estimation(2018 CVPR)
[183] 中的工作通过引入通道洗牌模块和空间通道注意剩余瓶颈(channel shuffle module and the spatial channel-wise attention residual bottleneck)改进了CPN,以增强原始模型。
Multi-person pose estimation with enhanced channel-wise and spatial information(2019 CVPR)
[104]MSPN将CPN扩展到多阶段管道中。它以CPN的全局网络为每个单级模块,通过跨级特征聚合融合不同阶段的特征,并通过从粗到细的损失函数对整个网络进行监控。
Rethinking on multi-stage networks for human pose estimation(2019 arXiv)
[185]HRNet指出高分辨率表示对于硬键点检测很重要。HRNet在整个网络中保持高分辨率的表示,并逐渐添加高分辨率到低分辨率的子网络,形成多分辨率特征。它已经成为姿态估计和许多其他计算机视觉任务的可靠且优越的模型。
Deep high-resolution representation learning for human pose estimation(2019 CVPR)
[209]Graph-PCNN考虑关键点的关系和细化粗略的预测,通过模型不可知的两阶段框架提出了图形姿态细化模块。
Graph-pcnn: Two stage human pose estimation with graph pose refinement(2020 ECCV)
[14] 利用了一个带有残差阶梯网络(RSN)模块的多级管道来聚合内部级别的功能。利用从RSN中获得的精细局部表示,提出了一种姿态优化机器(PRM)模块,以进一步平衡局部/全局表示并优化输出关键点。
Learning delicate local representations for multiperson pose estimation(2020 ECCV)
Complex case
在现实应用中,拥挤、遮挡和截断场景是不可避免的。针对这些问题一些相关工作被提出。
[144]RMPE为了消除不准确的人检测的影响,设计了对称的空间变换网络来检测每个人,设计了参数化姿态NMS来过滤冗余姿态,并设计了姿态引导的人类建议生成器来增强多人姿态估计的网络容量。
RMPE: Regional multi-person pose estimation(2017 ICCV)
[99] 为了解决拥挤场景中的问题,首先在每个裁剪的边界框中获得联合候选,然后在图模型中解决联合关联问题。(收集了一个名为CrowdPose的拥挤人体姿势估计数据集,并定义了拥挤指数来衡量图像的拥挤程度。)
Crowdpose: Efficient crowded scenes pose estimation and a new benchmark(2019 CVPR)
[247]OASNet利用Siamese网络的注意机制来消除遮挡感知歧义,并重建无遮挡特征。
Occlusion-aware siamese network for human pose estimation(2020 ECCV)
[9] 为了扩大挑战性案例的训练集,提出通过梳理分割的身体部位来模拟挑战性案例来增强图像。生成网络用于动态调整增广参数,生成最混乱的训练样本。
Adversarial semantic data augmentation for human pose estimation(2020 ECCV)
MIPNet[84] 重新考虑了自顶向下的人体姿态估计器的关键假设,即输入边界框中只有一个人。MIPNet允许在边界框内预测多个姿势实例,这对于处理拥挤场景中的失踪人员非常有效。
Multi-Instance Pose Networks: Rethinking Top-Down Pose Estimation(2021 ICCV)
Improving Efficiency
随着多人姿态估计应用需求的快速发展,小型快速网络越来越受到关注。
FCPose[126] 提出了一种动态实例感知框架,该框架消除了ROI和关键点分组后处理,从而无论图像中的人数如何,都能获得快速和恒定的推理时间。
FCPose: Fully Convolutional Multi-Person Pose Estimation With Dynamic Instance-Aware Convolutions(2021 CVPR)
CGANet[241] 提出了在全局上下文信息的指导下聚合多级盒特征的ROIGuider,并且提出的主干TNet能够以高效的方式实现多尺度特征融合。
Context-Guided Adaptive Network for Efficient Human Pose Estimation(2021 AAAI)
PoseNAS[6] 是一种基于神经结构搜索(NAS) 的方法,它直接搜索具有堆叠可搜索单元的面向数据的姿态网络,这可以为姿态特定任务提供最佳特征提取器和特征融合模块。(NAS平衡精度与效率)
Pose-native Network Architecture Search for Multi-person Human Pose Estimation(2020 ACM MM)
ViPNAS[222] 通过仔细设计具有五个不同维度的搜索空间来搜索空间网络,包括网络深度、宽度、内核大小、组数和关注度。通过搜索视频中的时间特征融合和自动计算分配,将其进一步应用于视频姿态估计。
ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search(2021 CVPR)
TokenPose[105] 为了明确了解关键点之间的约束关系,提出了一种基于令牌表示的Transformer架构。每个关键点被显式地嵌入为令牌,以同时学习图像中的约束关系和外观线索。TokenPose表明,基于Transformer的模型与最先进的基于CNN的模型相当,同时更轻。
Neural Architecture Search for Joint Human Parsing and Pose Estimation(2021 ICCV)
# Bottom-up
与依赖人体检测器的自上而下方法不同,自下而上方法直接预测图像中的所有关键点,然后将关键点候选分组到每个人中。除了为了更准确地检测关键点而进行的网络设计之外,如何对关键点之间的连接信息进行编码是将关键点分组给不同的人的核心。表中按照关键点分配策略划分:
Integer linear program for joint grouping
DeepCut[160] 通过Faster RCNN预测所有关键点,并将关键点分配问题表述为整数线性规划(ILP)。
Deepcut: Joint subset partition and labeling for multi person pose estimation(2016 CVPR)
DeeperCut[167] 通过引入更强的部位检测器来改进DeepCut。此外,它还提出了一个图像条件成对项,探索关键点的几何和外观约束。然而,ILP仍然是一个耗时的NP难问题。
Deepercut: A deeper, stronger, and faster multi-person pose estimation model(2016 ECCV)
Part Affinity Fields for joint grouping
OpenPose[15] 提出通过部分亲和场 (PAF)联合学习关键点位置及其关联。 PAF通过一组2D向量场对肢体的位置和方向进行编码。PAF的方向从肢体的一部分指向另一部分。然后,多人关联执行二部匹配,以使用PAF关联关键点候选。通过两个分支和多级架构,OpenPose实现了与图像中的人数无关的实时性能。
Realtime multi-person 2d pose estimation using part affinity fields(2017 CVPR)
PifPaf Net[92] 中,提出了一个局部强度场(PIF)来定位身体部位,然后是PAF来关联这些身体部位。PIF和PAF是联合产生的,同时利用拉普拉斯损失来处理低分辨率和遮挡场景。
Pifpaf: Composite fields for human pose estimation(2019 CVPR)
[60] 提出了第一种用于全身多人姿态估计的单网络方法,该方法可以同时定位图像中的身体、面部、手和脚关键点。
Single-network whole-body pose estimation(2019 ICCV)
[97] 中的工作设计了一个身体部位感知的PAF来编码关键点之间的连接,并通过注意机制和焦点L2丢失改进了堆叠沙漏网络。
Simple pose: Rethinking and improving a bottom-up approach for multi-person pose estimation(2020 AAAI)
Associative embedding for joint grouping
Associative Embedding是一种检测和分组方法,它检测关键点并将其分组为具有嵌入特征或标签的人。
[139] 提出生成关键点热图及其嵌入标签,用于多人姿态估计。对于身体的每个关节,网络产生检测热图,同时预测Associative Embedding标签。它们对每个关节进行顶部检测,并将其与共享相同嵌入标签的其他检测进行匹配,以生成最终的一组单独姿态预测。
Associative embedding: End-to-end learning for joint detection and grouping(2017 NeurIPS)
HigherHRNet[26] 也使用了关联嵌入,它从高分辨率特征金字塔中学习尺度感知表示。HigherHRNet利用HRNet中的聚合特征,以及通过转置卷积向上采样的高分辨率特征,很好地处理了尺度变化,并实现了自下而上姿态估计的新技术状态。
Higherhrnet: Scale-aware representation learning for bottomup human pose estimation(2020 CVPR)
[122] 为了应对人类尺度变化和标记模糊,提出了尺度和权重自适应热图回归(SWAHR),以自适应调整热图中每个关键点的标准偏差,并平衡前背景样本。
Rethinking the Heatmap Regression for Bottom-Up Human Pose Estimation(2021 CVPR)
Dense Keypoint Regression
另一种自下而上的范式是直接回归属于同一个人的关键点位置。
[144] 提出了一种姿态分割网络(PPN),它对所有候选关键点使用质心嵌入。
Pose partition networks for multi-person pose estimation(2018 ECCV)
[146] 介绍了结构化姿态表示(SPR)。它利用根关节来指示不同的人,并将关键点的位置编码为对应根的位移。
Single-stage multiperson pose machines(2019 CVPR)
逐像素关键点回归方法,如CenterNet[249]、ConerNet[95]和PointSetNet[213],密集预测表明同一个人关键点位置的姿势候选。
Tracking Objects as Points(2020 ECCV)
CornerNet: Detecting Objects as Paired Keypoints(2018 ECCV)
Point-set anchors for object detection, instance segmentation and pose estimation(2020 ECCV)
DEKR[228] 专注于学习精确关键点区域的表示,并使用多分支结构进行单独回归:每个分支学习具有专用自适应卷积的表示并回归一个关键点。
Bottom-Up Human Pose Estimation via Disentangled Keypoint Regression(2021 CVPR)
CenterGroup[12] 是一个基于注意力的框架,它使用Transformer为所有关键点和中心获取上下文感知嵌入。通过将多头注意力应用于组关节及其对应的人,CenterGroup是一个端到端的推理速度优越的管道。
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation(2021 ICCV)
SIMPLE[234] 为了更好地平衡精度和效率,模仿高性能自上而下管道中的姿态知识,并将人体检测和姿势估计作为一个统一的点学习框架,相互补充。
SIMPLE: SIngle-network with Mimicking and Point Learning for Bottom-up Human Pose Estimation(2021 AAAI)
Pose-level Inference Network(PINet)[208] 不是预测单个关键点,而是直接从可见身体部位推断出人的完整姿态。这是一种姿态级回归策略,不需要边界框检测和关键点分组。
Robust Pose Estimation in Crowded Scenes with Direct Pose-Level Inference(2021 NeurIPS)
Multi-task
MultiPoseNet[88] 还提出了一个多任务模型,可以联合处理人物检测、关键点检测和人物分割。MultiPoseNe提出了一种姿态残差网络(PRN),通过测量预测的关键点和检测到的人物边界框的位置相似性来分配它们。
Multiposenet: Fast multiperson pose estimation using pose residual network(2018 ECCV)
PersonLab[150] 也是一个多任务网络,它可以联合预测关键点热图和人物分割图。在PersonLab中,短程偏移和中程成对偏移用于对人类关键点进行分组。同时,利用长距离偏移量和人体姿态检测来区分人体分割模板。
Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model(2018 ECCV)
# 基于视频(估计/跟踪)
不同于基于图像的姿态估计,视频姿态估计必须考虑帧间的时间关系,以消除运动模糊和几何不一致性。因此,直接将现有的基于图像的姿态估计方法应用于视频可能会产生次优结果。在这一部分中,我们可以根据视频中的单人/多人姿态估计方法如何利用时空信息进行分类。
# Temporal clues
对于视频中的单人姿态估计,大多数工作探索跨帧传播时间线索,以细化单帧姿态结果。
Insert multiple frames into channel layer
[159] 作为视频中基于深度学习的姿态估计的首批工作之一,通过将多个帧插入数据颜色通道来利用时间信息,以替换基于图像的网络中输入的三通道RGB图像。
Deep convolutional neural networks for efficient pose estimation in gesture videos(2014 ACCV)
接下来的工作从四个主要类别,即用于相互学习的行为识别任务、基于光流的时间传播模型、序列模型和蒸馏模型,进一步探讨了时间传播。
Pose Estimation with Action Recognition
[142] 提出了一种spatial-temporal And-Or Graph(ST-AOG)模型,将视频姿态估计与行为识别相结合。通过添加基于光流和外观特征的额外活动识别分支,这两项任务可以相互受益。
Joint action recognition and pose estimation from video(2015 CVPR)
[70] 中的工作表明,可以通过使用行为条件下的图形结构模型结合活动优先级来实现行为预测,而不是额外的行为识别分支。
Pose for action - action for pose(2017 FG)
Optical Flow-based Feature Propagation
[158] 提出了一种时空网络,它通过光流将相邻帧的热图临时扭曲到当前帧。之后,他们还利用一个参数池层将对齐的热图组合成一个池信任热图。
Flowing convnets for human pose estimation in videos(2015 ICCV)
[17] 中的工作提出了一种个性化的ConvNet姿态估计器,它可以通过空间图像匹配和光流传播在整个视频中传播高质量的自动姿态注释。传播的新注释用于微调通用ConvNet姿态估计器。
Personalizing human video pose estimation(2016 CVPR)
Thin-Slicing[181] 提出通过计算相邻帧之间的密集光流来传播关键点。它们执行基于流的扭曲层,将之前的热图与当前帧对齐,然后是时空推断层。时空传播利用具有空间和时间关系的姿态配置图的迭代消息传递。
Thin-slicing network: A deep structured model for pose estimation in videos(2017 CVPR)
Sequence Model-based Feature Propagation
Chained Model[51] 采用序列到序列的递归模型来解决视频中的结构化姿态预测问题。在递归模型中,每个身体关键点的预测依赖于所有之前预测的关键点。
Chained predictions using convolutional neural networks(2016 ECCV)
LSTM Pose Machine [121] 探索了通过记忆增强的LSTM框架捕捉视频中的时间依赖性。给定一帧,the Encoder-RNN-Decoder pipelines首先通过编码器学习高级图像表示,然后通过RNN单元传播时间信息并产生隐藏状态。他们最终通过解码器预测当前帧的关键点,解码器将隐藏状态作为输入。
LSTM pose machines(2018 CVPR)
UniPose-LSTM[4] 采用了类似的概念,它利用LSTM模块传播UniPose网络中多分辨率Atrus空间池架构生成的先前热图。
Unipose: Unified human pose estimation in single images and videos(2020 CVPR)
Motion Adaptive Pose Net[42] 结合了运动补偿的ConvLSTM,以传播空间对齐的特征。它利用压缩流有效地解码视频中的姿态序列。
Motion Adaptive Pose Estimation From Compressed Videos(2021 ICCV)
Distillation Model
[109] 与需要大网络的光流或顺序RNN不同,引入了一个动态核蒸馏(DKD)模型,以一次性前馈方式传递姿态知识。具体来说,小型网络DKD通过鉴别器利用一种临时对抗性训练策略来生成临时一致的姿态核,并预测视频中的关键点。
Dynamic kernel distillation for efficient pose estimation in videos(2019 ICCV)
视频中的多人姿态估计需要在多人遮挡、运动模糊、姿态和外观变化的情况下识别和定位关键点。为了利用时间线索,多人姿态估计通常与关节跟踪相关联。
# Top-down
自上而下的方法遵循检测跟踪范式。它们首先检测每个帧中的人物和关键点,然后在帧之间传播边界框或关键点。
Clip-based spatio-temporal model
3D Mask R-CNN在Detect and Track[50] 中提出,利用全3D卷积网络来检测视频剪辑中每个人的关键点。然后使用关键点跟踪器通过比较检测到的边界框的距离来链接预测。
Detectand-track: Efficient pose estimation in videos(2018 CVPR)
[212] 中进一步利用了基于剪辑的跟踪器,该跟踪器通过精心设计的3D卷积层扩展了HRNet,以了解关键点之间的时间对应关系。接下来,设计了一个时空合并过程,通过时空平滑来估计最佳关键点输出。
Combining detection and tracking for human pose estimation in videos(2020 CVPR)
DCPose[117] 为了解决运动模糊、视频散焦或姿态遮挡问题,提出了一种多帧人体姿态估计框架,该框架利用三个模块分别对关键点时空上下文进行编码、计算双向加权姿态残差和细化姿态估计。
Deep Dual Consecutive Network for Human Pose Estimation(2021 CVPR)
Optical flow-based FlowTrack
[219] 中的工作独立地建立在单帧检测的基础上,并利用基于光流的时间姿态相似性来关联不同帧中的关键点。
Simple baselines for human pose estimation and tracking(2018 ECCV)
PoseFlow [220]
Pose flow: Efficient online pose tracking(2018 BMVC)
Transformer-based keypoint tracker KeyTrack
KeyTrack[180] 提出了一种基于Transformer的跟踪器,它只依赖于15个关键点。基于变压器的网络利用二元分类来预测一个姿态是否在时间上跟随另一个姿态。
15 keypoints is all you need(2020 CVPR)
Recovering missing detection
PGPT[5] 为了应对单个帧中的缺失检测,提出将基于图像的检测器与在线人员位置预测器相结合,以补偿缺失的边界框。同时,PGPT引入了一个层次化的姿态引导图卷积网络,该网络利用人的结构关系来增强人的表示和数据关联。
Poseguided tracking-by-detection: Robust multi-person pose tracking(2020 TMM)
[203] 中的工作提出了自监督关键点对应,它不仅可以恢复丢失的姿态检测,还可以跨帧关联检测到的和恢复的姿态。
Self-supervised keypoint correspondences for multi-person pose estimation and tracking in videos(2020 ECCV)
Learnable similarity metric
POINet[173] 为了实现高效的数据关联,探索了一种姿态引导的ovonic insight网络,以在统一的端到端网络中学习特征提取、相似性度量和身份分配。
POINet: pose-guided ovonic insight network for multi-person pose tracking(2019 ACM MM)
[224] 是可学习相似性度量的另一项工作,时间关键点匹配和关键点细化分别用于关键点关联和姿态校正。它们都是可学习的,并被整合到姿态估计网络中。
Temporal keypoint matching and refinement network for pose estimation and tracking(2020 ECCV)
# Bottom-up
这类方法通常使用单帧姿态估计来预测每帧中的所有关键点,然后以时空优化的方式跨帧分配关键点。
这种方法通常使用单帧姿态估计来预测每个帧中的所有关键点,然后以时空优化方式跨帧分配关键点。例如,[1,67,71]中基于图划分的方法扩展了图像级自下而上多人姿态估计[15,160]。然后,他们构建了一个时空图,该图在空间和时间上连接关键点候选者,可以将其表述为线性规划问题。然而,时空图划分通常导致大量计算和非在线解。不同的是,PoseFlow[220]利用姿势流测量不同帧中的姿势距离来跟踪同一个人。受OpenPose[15]中空间部分亲和场的启发,[36、40、162]中的工作利用时间流场来指示关键点在帧间的传播方向。在基于图像的自底向上关键点关联策略中使用的关联嵌入[139]也在[74]中进行了扩展,以构建时空嵌入。它将关键点与嵌入特征相关联,以实现时间一致性
Graph partitioning-based model
[1]、[67]、[71] 中基于图分割的方法首先扩展了图像级自底向上的多人姿态估计。然后,他们建立了一个时空图,将关键点候选点在空间和时间上连接起来,可以将其表述为一个线性规划问题
Posetrack: Joint multi-person pose estimation and tracking(2017 CVPR)
Arttrack: Articulated multi-person tracking in the wild(2017 CVPR)
Posetrack: A benchmark for human pose estimation and tracking(2018 CVPR)
图的时空划分通常会导致大量计算和非在线求解。
Temporal Flow Fields-based model
[36]、[40]、[162] 中的作品利用时间流场来指示不同帧中关键点的传播方向。
Jointflow: Temporal flow fields for multi person pose tracking(2018 BMVC)
Learning to detect and track visible and occluded body joints in a virtual world(2018 ECCV)
Pose estimator and tracker using temporal flow maps for limbs(2019 IJCNN)
Efficient online multiperson 2d pose tracking with recurrent spatio-temporal affinity fields(2019 CVPR)
Spatio-temporal associative embedding model
[74] 在基于图像的自底向上关键点关联策略中使用的Associative embedding中也进行了扩展,以构建时空嵌入。它将关键点与嵌入特征相关联,以实现时间一致性。
Multi-person articulated tracking with spatial and temporal embeddings(2019 CVPR)
# 单目3D人体姿态估计
基于代表性深度学习的单目3D姿态估计方法
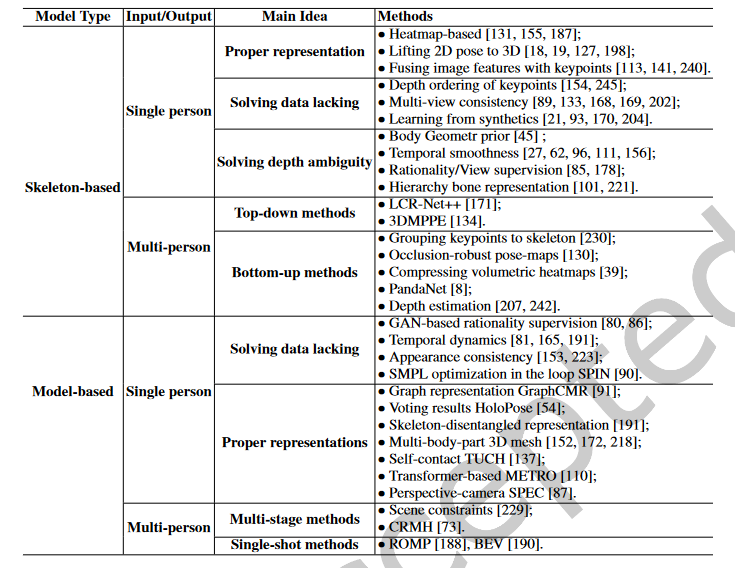
根据输出表示,单目3D姿态估计可分为基于骨架的3D姿态估计和基于模型的3D姿态估算。基于骨架的三维姿态估计直接估计人体关节的三维坐标,而基于模型的方法采用统计三维模型,如SMPL,作为在人体之前引入强几何体的中间表示。
与2D姿态估计相比,从单目2D图像估计3D姿态更具挑战性。除了2D部分的所有挑战外,单目3D姿态估计还受到缺乏野外3D数据和固有深度模糊的影响。
主要挑战之一是缺乏足够的具有精确3D注释的野外数据。精确捕捉3D姿态注释既困难又昂贵,尤其是在室外条件下。大多数现有的3D姿态数据集通常偏向于具有有限动作的特定环境(例如,室内)。例如,Human3.6M仅包含11名演员,在一个房间内执行15项活动。相反,2D姿势数据易于收集,其中包含更丰富的姿势和环境。因此,2D姿态数据集经常用于训练以提高泛化。此外,许多方法提出了无监督或弱监督框架,以减轻对数据集的依赖。
此外,单目输入在描述深度信息时是模糊的。由于多个3D姿态可以映射到相同的2D观测,因此很难确定精确的3D姿态。特别是对于多阶段方法,这种模糊性加剧。许多方法试图通过使用各种先验信息来解决这个问题,例如几何先验知识、统计模型和时间平滑度。在本节中,根据姿态表示的方式,我们将代表性的3D姿势估计方法分为1)基于骨架的范式和2)基于模型的范式。在每个范例中,根据解决不同挑战的动机总结了各种方法,包括开发适当的表示、解决野外3D数据的缺乏、缓解固有的深度模糊以及处理多人场景中的人-人遮挡。
# Skeleton-based 3D Pose Estimation
# Proper Representation
如下图,根据该表示,单人3D姿势估计的主流方法通常采用三种框架:1) volumetric heatmap,2) lifting 2D pose to 3D pose, and 3) fusing image features with the 2D pose.
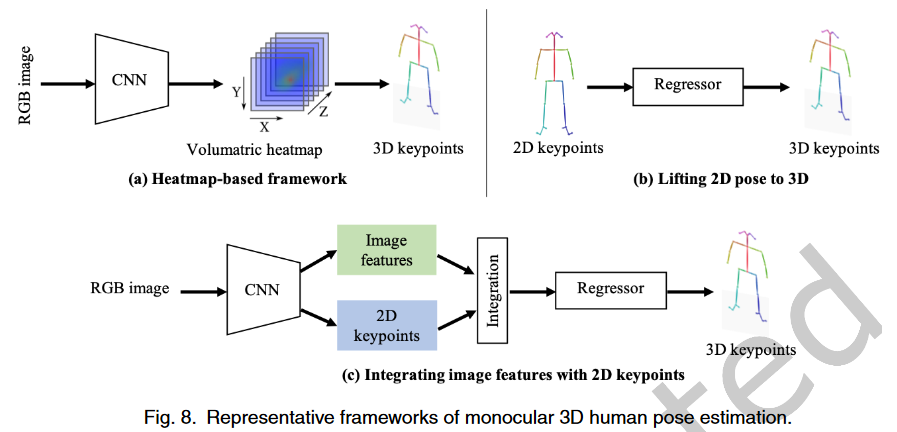
Direct regression:直接预测每个关键点的3D位置的基于回归的方法[102]
3d human pose estimation from monocular images with deep convolutional neural network(2014 ACCV)
Volumetric heatmap:与直接预测每个关键点的3D位置的基于回归的方法不同,基于热图的方法将每个3D关键点表示为热图中的3D高斯分布。通过在后处理期间获取局部最大值,可以从估计的体积热图中解析出3D关键点坐标。如图(a)所示,基于热图的方法被设计为通过端到端框架从单目图像直接估计体积热图。
遵循这个管道,Coarse-to-Fine(C2F)[155] 网络被提出来叠加沙漏网络,并逐步扩展预测热图的体积方向以获得精细结果。
Coarse-to-fine volumetric prediction for single-image 3D human pose(2017 CVPR)
VNet[131] 是一种实时单目3D姿态估计方法。它使相干运动学骨架适合后处理,以基于相干运动学骨架产生时间稳定的姿态结果。
Vnect: Real-time 3d human pose estimation with a single RGB camera(2017 ACM TOG)
Integral Human Pose(IHP)[187] 为了简化后处理,提出了一种积分运算,在推理过程中以可微分的方式将热图直接转换为关键点坐标。它在基于热图的方法和基于回归的方法之间架起了一座桥梁。
Integral human pose regression(2018 ECCV)
Lifting 2D pose to 3D pose:为了受益于稳健的2D姿态估计方法,如图(b)所示,许多方法侧重于将2D姿态提升到3D。整个流程可分为两部分:1)从单目图像估计2D姿态,2)将估计的2D姿态提升到3D。提升模型的结构通常很简单,二维姿态估计方法可以保证泛化。
[127]提出了Simple-3D,这是一种众所周知的简单基线方法,用于从2D姿态估计每个关键点的深度。它只包含两个完全连接的块,同时在相关基准上实现了良好的性能。
A simple yet effective baseline for 3d human pose estimation(2017 CVPR)
[18]通过姿态匹配解决了2D到3D关键点提升问题。为了丰富匹配库,他们通过使用随机相机将3D姿势投影回2D图像平面来生成大量2D-3D姿态对。然后他们得到一个大的2D-3D姿态对库。给定2D图像,他们只需要预测2D姿态并从库中搜索最相似的2D-3D姿态对。选择成对的3D姿态作为3D姿态估计结果。
3D human pose estimation = 2D pose estimation+ matching(2017 CVPR)
[198]开发了一个多级卷积网络,以递归优化估计的3D姿态。他们使用估计的3D姿态的反投影来细化中间2D姿态,这逐渐提高了2D和3D姿态估计的精度。
Lifting from the deep: Convolutional 3d pose estimation from a single image(2017 CVPR)
[19]利用2D姿态输入和估计3D姿态的2D投影之间的双周期一致性,以无监督的方式学习2D到3D提升函数。它们在循环中随机变换提升的3D姿态,以避免收敛到具有恒定深度的局部最小值。
Explaining Neural Networks Semantically and Quantitatively(2019 ICCV)
Fusing image features with keypoints:鲁棒2D姿态估计只能提供关于人体的有限信息。如果我们仅将2D姿态作为输入,则深度模糊会加剧。而图像特征提供了更多的上下文信息,这有助于确定准确的3D姿态。因此,许多方法试图结合两种管道的优点。该架构如图(c)所示。
[141]建议将关键点的局部图像纹理特征集成到全局2D骨架中。然后,开发了一个LSTM网络的两级层次结构,以逐步建模全局和局部特征。
Monocular 3D human pose estimation by predicting depth on joints(2017 ICCV)
SemGCN[240]和[113]都提取了关节级图像特征,并将其与关键点坐标整合,以形成多个图形节点。GCN或LSTM用于借助图像特征探索关键点节点之间的关系。
Semantic graph convolutional networks for 3D human pose regression(2019 CVPR)
Feature boosting network for 3D pose estimation(2019 TPAMI)
# Solving the Data Lacking Problem
大多数3D姿势数据集捕捉室内环境中少数演员的非常有限的活动。与二维姿态数据集相比,三维姿态数据集在姿态和环境的多样性方面较差。为了解决这个问题,许多方法试图以无监督或弱监督的方式训练模型。例如,一些方法建议使用较弱但廉价的标签进行监督。
Depth ordering of keypoints:
[154]利用关键点之间的弱序深度关系进行监督。实验表明,与使用地面真实三维位姿注释的直接监控相比,顺序监控也可以实现相当的性能。
Ordinal depth supervision for 3d human pose estimation(2018 CVPR)
Hemlets Pose[245] 通过热图三重态损耗将相邻关键点的显式深度排序编码为地面真值。
HEMlets pose: Learning part-centric heatmap triplets for accurate 3d human pose estimation(2019 ICCV)
Multi-view consistency:除了主体结构先验外,一些方法使用多视图一致性进行监督。请注意,这些方法仍然将单目图像作为输入,同时仅利用多视图一致性进行训练。(推理时单视图输入,仅训练时多视图)
然而,仅考虑多视图一致性将导致退化解。模型可能陷入局部最小值,并为不同输入产生类似的零位姿。为了解决这个问题,[169]建议使用少量的标记数据来避免局部最小值并纠正预测。
Learning Monocular 3D Human Pose Estimation From Multi-View Images(2018 CVPR)
[168]建议使用顺序图像为身体表征学习提供先验时间一致性。
Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation(2018 ECCV)
EpipolarPose[89] 利用多视图2D姿态通过epipolar几何体生成3D姿态注释。这样,整个框架可以以自监督的方式进行训练。
Self-Supervised Learning of 3D Human Pose Using Multi-View Geometry(2019 CVPR)
[202]通过一种新的基于对准的目标函数解决退化陷阱,而无需外部摄像机校准。他们使用未标记的多视图图像和2D姿态数据集训练模型。2D姿态仅用于训练2D姿态主干。利用多视点图像进行相应的3D姿态估计。多视图3D姿态结果被归一化,然后使用Procrustes分析进行一致性对齐。在此过程中,三维姿态将变换为相同的比例以进行刚性对齐。
Weakly-Supervised 3D Human Pose Learning via Multi-View Images in the Wild(2020 CVPR)
[133]提出以半监督方式学习视图不变姿态嵌入。通过使左骨盆骨平行于XZ平面,训练模型以估计视图不变的3D姿态。基于时间关系的硬负挖掘用于在不同视图中获得一致的姿态嵌入。
Multiview-Consistent Semi-Supervised Learning for 3D Human Pose Estimation(2020 CVPR)
Learning from synthetic:此外,其他方法建议从合成数据中学习。通常,有两种数据合成管道:1)2D图像拼接管道和2)3D模型渲染管道。总的来说,2D图像拼接管道有可能生成更真实的人物图像,而3D模型投影管道可以获得更全面的3D注释。
对于第一个框架,[170]试图生成来自3D运动捕捉(MoCap)数据集的3D姿态的2D图像。他们首先选择2D姿态与投影3D姿态的一部分匹配的图像块。在运动学约束下,局部图像块被缝合以形成3D姿态的完整2D图像。
Mocap-guided data augmentation for 3d pose estimation in the wild(2016 NeurIPS)
[21]和[204]遵循3D模式渲染管道。他们使用SCAPE或SMPL 3D人体模型,将纹理统计人体模型投影到野生背景图像中的2D上,用于数据生成。通过这种方式,野生图像中2D人物的完整3D注释可用。注释不仅包含3D身体姿势、形状和纹理,还包含相机和灯光参数。
Synthesizing training images for boosting human 3d pose estimation(2016 3DV)
Learning from Synthetic Humans(2017 CVPR)
PGP-human[93]使用3D到2D投影构建了一个自我监督的训练管道。PGP human利用从野生视频中采样的图像对,其中包含在不同背景下执行不同动作的同一个人。该模型通过混合从图像对中提取的特征来训练,以分离外观和姿势信息,用于图像重新合成。
Self-Supervised 3D Human Pose Estimation Via Part Guided Novel Image Synthesis(2020 CVPR)
# Solving the Inherent Depth Ambiguity
由于深度上固有的模糊性,单个2D姿态可能对应于多个3D姿态,特别是在将2D姿态提升到3D的流水线中。因此,采用各种先验约束来确定特定姿态。许多方法使用时间一致性和动力学来解决单个2D姿态的模糊性。
Body Geometr prior
RSTV[196]将视频序列中裁剪的单人图像块作为输入,并估计中心帧中的3D姿态。
Direct prediction of 3d body poses from motion compensated sequences(2016 CVPR)
Fang等人[45]通过双向RNN的层次结构将身体先验(包括运动学、对称性和驱动关节协调)明确纳入模型。以这种方式,监督3D姿态预测以遵循身体的先验约束和时间动力学。
Learning pose grammar to encode human body configuration for 3d pose estimation(2018 AAAI)
Temporal smoothness
[111]、[62]和[96]开发了由LSTM单元组成的序列到序列网络,以从2D位姿序列估计3D位姿序列。通过探索运动序列中的运动动力学,可以更好地确定每个帧的特定姿态。
Recurrent 3d pose sequence machines(2017 CVPR)
Exploiting temporal information for 3d human pose estimation(2018 ECCV)
Propagating lstm: 3d pose estimation based on joint interdependency(2018 ECCV)
为了提高计算效率,VideoPose3D[156]和OANet[27]在2D姿态序列上采用时间卷积来保证时间一致性。全卷积结构实现了高效的并行计算。不同的是,OANet使用圆柱体人体模型来生成遮挡标签,这有助于模型学习身体部位之间的碰撞。
3d human pose estimation in video with temporal convolutions and semi-supervised training(2019 CVPR)
Occlusion-Aware Networks for 3D Human Pose Estimation in Video(2019 ICCV)
Rationality/View supervision
[178]以生成对抗的方式解决了歧义。他们训练条件VAE网络,以证明基于2D姿态生成的3D姿态样本的合理性。
Monocular 3d human pose estimation by generation and ordinal ranking(2019 ICCV)
ActiveMoCap[85]试图估计用于选择模糊度较低的最佳输出的不同预测的不确定性。它有助于模型学习3D姿态估计的最佳视点。
ActiveMoCap: Optimized Viewpoint Selection for Active Human Motion Capture(2020 CVPR)
Hierarchy bone representation:除了时间一致性,其他一些方法试图通过开发更接近身体结构的表示来解决歧义。
[221]和[101]采用分层骨骼表示法。在该分层骨骼表示中,相邻关节的几何相关性被显式建模,其主要关注于监控骨骼长度和关节方向。得益于分层骨骼表示,3D身体骨架是可分离的,可以很容易地混合以合成新骨架。因此,[101]提出通过混合不同骨架图像来丰富训练数据的姿态空间。使用扩展数据进行训练有助于改进模型泛化。
Deep Kinematics Analysis for Monocular 3D Human Pose Estimation(2020 CVPR)
Cascaded Deep Monocular 3D Human Pose Estimation With Evolutionary Training Data(2020 CVPR)
多人:根据处理流程,现有的多人三维姿态估计方法可以大致分为两类:1)自顶向下的方法和2)自底向上的方法。自顶向下的方法首先检测人,然后分别估计每个人的3D姿态。而自下而上的方法首先检测关键点,然后将它们分组以形成每个人的3D姿态。
# Top-down Methods
LCR Net++[171]构建在通用的两阶段基于锚的检测框架之上。他们首先从锚提议中收集姿态候选,然后通过得分排名确定最终输出。
LCR-Net++: Multi-person 2d and 3d pose detection in natural images(2019 TPAMI)
[134]中的工作也建立在基于锚的检测框架上。它们根据检测到的人体区域的特征及其边界框位置,使用单独的分支来估计3D绝对根定位和根相对姿态估计。
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image(2019 ICCV)
# Bottom-up Methods
[230]提出了一种自下而上的多阶段框架,用于单目多人3D姿态估计。它首先从单个图像估计体积热图以确定3D关键点位置。然后预测检测到的关键点之间的所有可能连接的置信度得分以形成肢体。最后,他们执行骨架分组以将肢体分配给不同的人。
Deep network for the integrated 3d sensing of multiple people in natural images(2018 NeurIPS)
为了处理多人场景中的遮挡问题,[130]开发了一种遮挡鲁棒姿态图(ORPM),以将冗余遮挡信息包含在部分亲和度图中。此外,他们提出了第一个多人3D姿态数据集MuCo3DHP,这大大促进了该领域的发展。
Single-shot multi-person 3D pose estimation from monocular RGB(2018 3DV)
[39]建议以编码器-解码器的方式估计体积热图,并从中回归多人3D姿势。通过用于压缩体积热图的地面实况关键点热图的编码特征来监督中间编码特征。
Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation(2020 CVPR)
PandaNet[8]是用于多人3D姿态估计的基于锚的单镜头模型。它直接预测每个锚位置的2D/3D姿态。
PandaNet: Anchor-Based Single-Shot Multi-Person 3D Pose Estimation(2020 CVPR)
Depth estimation
SMAP[242]估计多个图,表示每个位置的体根深度和部分相对深度。为了对热图上的关键点进行分组,他们使用估计的深度来确定关联。
SMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation(2020 ECCV)
HMOR[207]对多人交互关系进行建模,以获得更好的性能。它通过实例级、部件级和联合级分层估计多人顺序关系。
HMOR: Hierarchical multi-person ordinal relations for monocular multi-person 3d pose estimation(2020 ECCV)
# Model-based 3D Pose Estimation
基于模型的单幅图像三维姿态估计引起了广泛关注,因为它可以提供超出关键点位置的额外身体形状信息。为了降低网格回归的复杂性并关注三维姿态估计,最近的方法采用统计三维人体模型(如SMPL)作为表示,这可以带来强几何先验。以这种方式,他们将3D姿态估计公式化为估计SMPL姿态和形状参数。如下图所示,一般框架是从单个人2D RGB图像直接估计相机和SMPL参数。我们可以从SMPL参数导出3D人体网格,并从网格中回归3D关键点。对于单人方法,我们根据其动机介绍它们:1)解决3D数据短缺问题,2)促进基于模型的3D姿态估计的更恰当表示。对于多人方法,我们将其分为1)多阶段方法和2)单镜头方法
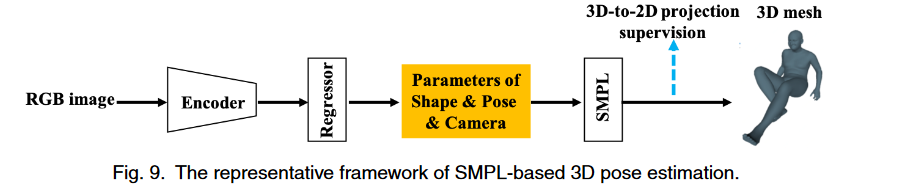
# Solving the Data Lacking
由于数据不足,我们应该使用所有可用的2D/3D姿势数据集来更好地学习。为了实现这一点,现有的方法开发了各种损失函数来监督估计的身体网格的不同方面。
GAN-based rationality supervision
Human Mesh Recovery(HMR)[80]利用了从2D姿态和3D运动捕捉(MoCap)数据集中的未配对数据学习的方法。然而,缺乏深度监督将导致不合理的3D姿态和形状。相反,他们使用MoCap数据以生成对抗的方式监督估计参数的合理性。开发了一个鉴别器来确定估计的SMPL姿态和形状参数是否合理。
End-to-end Recovery of Human Shape and Pose(2018 CVPR)
Temporal dynamics
为了从时间动力学中学习,训练3D人体动力学模型[81]以估计当前、过去和未来帧的3D姿态。为了将静态图像转换为运动序列,学习幻觉器来估计过去和未来运动的特征以进行合成。
Learning 3D Human Dynamics from Video(2019 CVPR)
[86]开发了一个名为VIBE的时间网络。在HMR之后,他们使用运动鉴别器以生成对抗的方式监督预测运动序列的合理性。具体而言,通过选通递归单元(GRU),描述运动序列的SMPL参数在每个时间步长被映射到潜在表示。
VIBE: Video Inference for Human Body Pose and Shape Estimation(2020 CVPR)
HuMoR[165]采用条件变分自动编码器来建立时间先验,以优化输入运动的动态性和鲁棒性。
HuMoR: 3D Human Motion Model for Robust Pose Estimation(2021 ICCV)
Appearance consistency
TexturePose[153]还利用多个视点或相邻视频帧中同一个人的外观一致性进行监控。身体纹理从2D图像映射到UV贴图,UV贴图在语义上对齐多视图或顺序纹理。只有每个人的多个UV贴图中的可见部分才受到纹理一致性的监督。
TexturePose: Supervising Human Mesh Estimation with Texture Consistency(2019 ICCV)
其他方法来制定更详细的监督
HoloPose[54]提出了一个多任务网络,用于估计DensePose[53]、2D和3D关键点,以及基于零件的3D重建。提出了一种迭代细化方法,以改进基于模型的2D/3D关键点的3D估计与DensePose之间的对齐。
HoloPose: Holistic 3D Human Reconstruction In-The-Wild(2019 CVPR)
Human Mesh Deformation(HMD)[250]利用附加信息,包括身体关键点、轮廓和每像素着色,来细化估计的3D网格。通过分层网格投影和变形细化,身体网格与输入2D图像中的人很好地对齐。
Detailed human shape estimation from a single image by hierarchical mesh deformation(2019 CVPR)
SMPLify[10]通过将3D人体网格拟合到预测的2D关键点并最小化重新投影误差,迭代地细化3D人体网格。
Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image(2016 ECCV)
SPIN[90]结合了基于回归和基于优化的方法的优点。他们利用SMPLify来细化训练循环中的估计结果,以提供额外的3D监控。
Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop(2019 ICCV)
# Model Representations
GraphCMR[91]利用基于图的表示法对SMPL体网格进行回归。它们将SMPL模板网格的每个顶点作为图卷积网络的节点。每个节点附加图像特征向量以估计对应顶点的3D坐标。则可以从这些顶点估计SMPL参数。
Convolutional Mesh Regression for Single-Image Human Shape Reconstruction(2019 CVPR)
I2L MeshNet[136]提出了一种image-to-lixel(线+像素)预测网络,该网络预测1D热图上的每像素似然,以回归每个网格顶点坐标。
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image(2020 ECCV)
基于DensePose,DenseRaC[223]使用估计的IUV图作为估计SMPL参数的中间表示。使用差分渲染器将估计的身体网格渲染回IUV图,并与输入进行比较以进行监督。
DenseRaC: Joint 3D Pose and Shape Estimation by Dense Render-and-Compare(2019 ICCV)
Sun等人[191]利用双线性变换开发了一种骨架解纠缠表示法,以解决2D姿态和其他细节的特征耦合问题。他们使用基于Transformer的网络来学习时间平滑度,其中开发了无监督对抗训练策略,通过对混洗帧进行排序来学习运动动力学。
Human Mesh Recovery from Monocular Images via a Skeleton-disentangled Representation(2019 ICCV)
METRO[110]采用基于Transformer的网络来根据图像特征估计3D身体网格。通过将CNN特征附加到模板网格的关节和顶点,采用基于Transformer的模型来回归3D坐标作为输出。
End-to-End Human Pose and Mesh Reconstruction with Transformers(2021 CVPR)
一些工作探索了全身三维网格恢复的表示,包括面部和手:SMPL+H[172]将3D手模型集成到SMPL身体模型中,以联合恢复身体和手的3D网格。Xiang等人[218]提出了MTC方法,使用单独的CNN网络来估计身体、手和脸,然后将Adam[78]模型联合拟合到所有身体部位的输出。SMPL-X[152]将火焰头模型[103]与SMPL+H相结合,并通过将模型拟合到3D扫描数据来学习与姿势相关的混合形状。SMPLify-X[152]被提出通过将SMPL-X迭代拟合到面部、手和身体的2D关键点来恢复人体全身3D网格。与以往需要分别从每个身体部位提取特征的方法不同,Sun等人[189]提出了一种分解框架及其基于合成的学习管道,以一次性同时估计多个身体部位的网格。
其他工作开始探索明确的高级表示,以模拟图像中的一些复杂角色,如身体自我接触[137]、相机姿态[87]和地面约束[166]。TUCH[137]明确建模并学习身体自我接触。他们观察到,自接触的顶点在欧几里得距离上接近,而在测地距离上彼此远离。基于这一观察,设计了一种专用的基于优化的方法,以避免相互渗透,同时鼓励接触。SPEC[87]估计了部分透视相机参数,以便于更精确的3D网格恢复。了解摄像机姿态有助于克服透视投影带来的失真。Rempe等人[166]建议检测脚与地面的接触,以优化3D身体运动序列,从而减少脚打滑和脚与地面之间的穿透。
On Self-Contact and Human Pose(2021 CVPR)
SPEC: Seeing People in the Wild with an Estimated Camera(2021 ICCV)
Contact and Human Dynamics from Monocular Video(2020 ECCV)
# Multi-person 3D Mesh Recovery
虽然单目3D人体姿态和形状估计在单人场景中已经取得了很大进展,但处理具有截断、环境遮挡和人-人遮挡的多人场景是至关重要的。现有的多阶段方法为单人管道配备2D人物检测器以处理多人场景。与仅估计数十个身体关节的2D/3D关键点估计不同,最近的工作还试图探索3D网格恢复的特殊性。
[229]建议在多人场景中使用自然场景约束。为了获得初始的三维人体网格,它们将SMPL模型拟合到三维姿态,并根据图像估计其语义分割。为了排除体积占用的情况,他们在目标函数中加入了碰撞约束。同时,估计地平面以模拟该平面与所有人类对象之间的相互作用。
Monocular 3d pose and shape estimation of multiple people in natural scenes-the importance of multiple scene constraints(2018 CVPR)
[73]建议使用coherent reconstruction of multiple humans(CRMH)进行多人3D网格恢复。他们基于Faster-RCNN构建了他们的方法,其中RoI对齐特征用于预测SMPL参数。具体而言,他们开发了一种可微分插值损失,以避免身体网格之间的碰撞。
Coherent Reconstruction of Multiple Humans From a Single Image(2020 CVPR)
[188]提出了一种用于多人网格恢复的实时单阶段方法ROMP。在ROMP中,人的2D身体中心位置和3D网格分别表示为2D热图和网格参数图。这种基于中心的显式表示保证了像素级特征编码。为了处理严重重叠的拥挤情况,它们通过推开碰撞的身体中心来增强表示的不模糊性。
Monocular, One-stage, Regression of Multiple 3D People(2021 ICCV)
基于ROMP的简明单阶段架构,[190]进一步开发了BEV,以从单目图像中回归人与人之间的相对位置,尤其是深度。他们开发了一种鸟瞰图表示法,以明确地推理深度。他们还发展出一种微弱的年龄意识丧失,以利用从婴儿到成人的3D身体形状空间。他们还创建了一个相对人类的数据集,以有效地了解野生图像中的相对深度和年龄。
Putting People in their Place: Monocular Regression of 3D People in Depth(2022 CVPR)
# Deep Learning-Based Human Pose Estimation: A Survey(2021 arXiv)
# 介绍
HPE分为两大类:2D HPE和3D HPE。
根据人数,2D HPE方法分为单人和多人设置。对于单人方法,有两类基于深度学习的方法:回归方法和基于热图的方法。对于多人方法,也有两种方法:自顶向下方法和自下而上方法。
3D HPE方法根据输入源类型进行分类:单目RGB图像和视频(或其他传感器(如惯性测量单元传感器。这些方法中的大多数使用单目RGB图像和视频,并进一步分为单视图单人;多人单视图;以及多视图方法。多视图设置主要用于多人姿态估计。因此,该类别中未指定单人或多人。
# 2D人体姿态估计
# 3D人体姿态估计
# 介绍
3D HPE旨在预测人体关节在三维空间中的位置,由于其能够提供与人体相关的广泛的三维结构信息,近年来引起了人们的极大兴趣。它可以应用于各种应用(例如,3D电影和动画行业、虚拟现实和运动分析)。尽管2D HPE已经取得了显著的改进,但3D HPE仍然是一项具有挑战性的任务。现有的大多数工作都是针对单目图像或者视频的三维HPE,这是一个不适定和逆问题由于3D到2D的投影导致的其中一维丢失。
当多个视图可用或部署了IMU和激光雷达等其他传感器时,使用信息融合技术,3D HPE可能是一个适定问题。另一个限制是深度学习模型需要大量数据,并且对数据收集环境敏感。与2D HPE数据集不同,可以轻松获得精确的2D姿势注释,收集精确的3D姿态注释非常耗时,手动标记不实用。此外,数据集通常是在室内环境中通过选定的日常活动收集的。最近的工作揭示了通过跨数据集推理使用有偏数据集训练的模型的泛化性较差。
3D HPE from monocular RGB images and videos
# 单视图单人
# 基本架构
(a)直接估计方法直接从2D图像估计3D人体姿态。
(b)2D到3D提升方法利用预测的2D人体姿势(中间表示)进行3D姿势估计。
受2D HPE最近成功的推动,从中间估计的2D人体姿势推断3D人体姿势的2D到3D提升方法已成为流行的3D HPE解决方案。在第一阶段,采用现成的2D HPE模型来估计2D姿态。然后使用2D到3D提升来获得第二阶段中的3D姿态,得益于最先进的2D姿态检测器的出色性能,2D到3D提升方法通常优于直接估计方法。
(c) 人体网格恢复方法结合参数化身体模型来恢复高质量的3D人体网格(human mesh)。由3D姿态和形状网络推断出的3D姿态和外形参数被馈送到模型回归器中以重构3D人体网格。然后通过回归头获得3D骨骼点坐标。(引入人体结构先验知识,一定程度上防止预测不合理的骨骼)
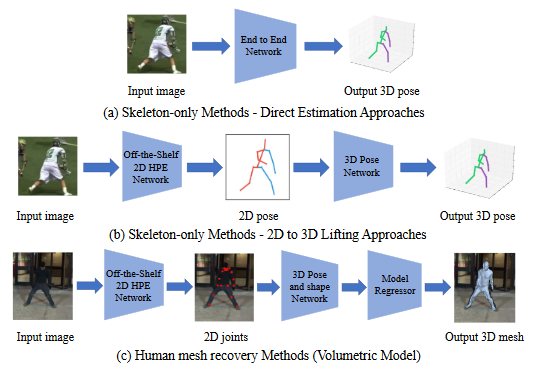
# Skeleton-only
Direct estimation
2D to 3D lifting
GCN(2D to 3D lifting)
The kinematic model(人体先验知识)
弱监督/自监督
基于视频
Transformer架构
# Human Mesh Recovery (HMR)
Volumetric models(SMPL)
Transformer
extended SMPL-based models
other models
# 单视图多人
# 基本架构
(a) 自顶向下方法首先通过人体检测网络检测单个人区域。对于每个单个人区域,可以通过3D姿态网络估计单个3D姿态。然后将所有3D姿势与世界坐标对齐。
(b) 自下而上的方法首先估计所有身体关节和深度图,然后根据根深度和部分相对深度将身体部分与每个人关联。
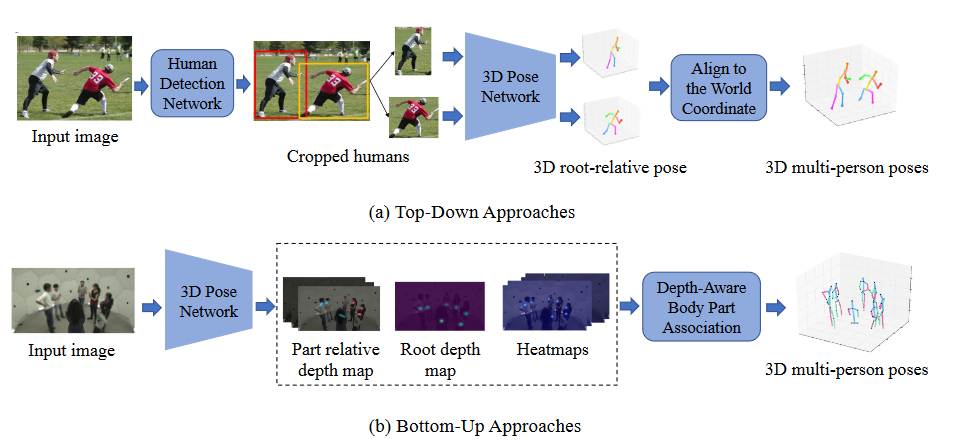
# Top-down
# Bottom-up
# Comparison of top-down and bottom-up approaches
自上而下的方法通常依靠最先进的人员检测方法和单人HPE方法来实现有希望的结果。但是计算复杂度和推理时间可能随着人类数量的增加而变得过度,特别是在拥挤的场景中。此外,由于自顶向下的方法首先检测每个人的边界框,因此场景中的全局信息可能会被忽略。裁剪区域的估计深度可能与实际深度排序不一致,并且预测的人体可能被放置在重叠位置。
相反,自下而上的方法具有线性计算和时间复杂度。然而,如果目标是恢复三维人体网格,则自下而上方法重建人体网格并不简单。对于自顶向下的方法,在检测到每个人之后,通过结合3D单人人体网格恢复方法,可以容易地恢复每个人的人体网格。而对于自下而上的方法,需要额外的模型回归器模块来基于最终的3D姿态重建人体网格。
# 多视图
对于单视图设置中的3D HPE,部分遮挡是一个具有挑战性的问题。克服该问题的自然解决方案是从多个视图估计3D人体姿态,因为一个视图中的遮挡部分可能在其他视图中可见。为了从多个视图重建3D姿态,需要解决不同摄像机之间的对应位置的关联。我们不在该类别中指定单人或多人,因为多视图设置主要用于多人姿态估计。
# 2D人体姿态估计
# 基于RGB图像
# 单人
# Deeppose(2014 CVPR)
Deeppose: Human pose estimation via deep neural networks
# Stacked Hourglass Networks(2016 ECCV)
Stacked hourglass networks for human pose estimation
# CPM(2016 CVPR)
Convolutional pose machines
出发点: Pose Machines构建了一个用于学习丰富隐空间模型的序列化预测框架。本文将卷积神经网络合并到姿态机框架中来学习图像特征和基于图像的空间模型,该系统化的设计用于姿态识别任务。
- 使用级联(sequential)卷积结构学习隐式空间模型,它以之前阶段输出的belief maps为输入,一级级地生成越来越准确的骨架估计,而不需要显式地进行图形化模型推理。
- 网络mutil-stage。提出了一个自然的目标函数来加强中间阶段的监督,从而补充了反向传播的梯度,解决了训练中经常出现的梯度消失难题,调节了学习过程。
模型
Pose Machines如插图(a)和(b)所示。使用boosted随机森林来做分类器;每个阶段的图像特征固定,即 x'=x;跨阶段捕获上下文信息的函数也固定。
CPM网络如插图(c)和(d)所示。将PM中的特征提取和上下文信息提取用CNN来实现了,以heatmap的形式表示预测结果(能够保留空间信息),在全卷积的结构下使用中间监督进行端到端的训练和测试,极大提高了关键点检测的准确率。
下面的插图(e)中,我们展示了图像(以左膝为中心)上的有效感受野,其中较大的感受野使模型能够捕捉长距离的空间依赖性,例如头部和膝盖之间的空间依赖性。
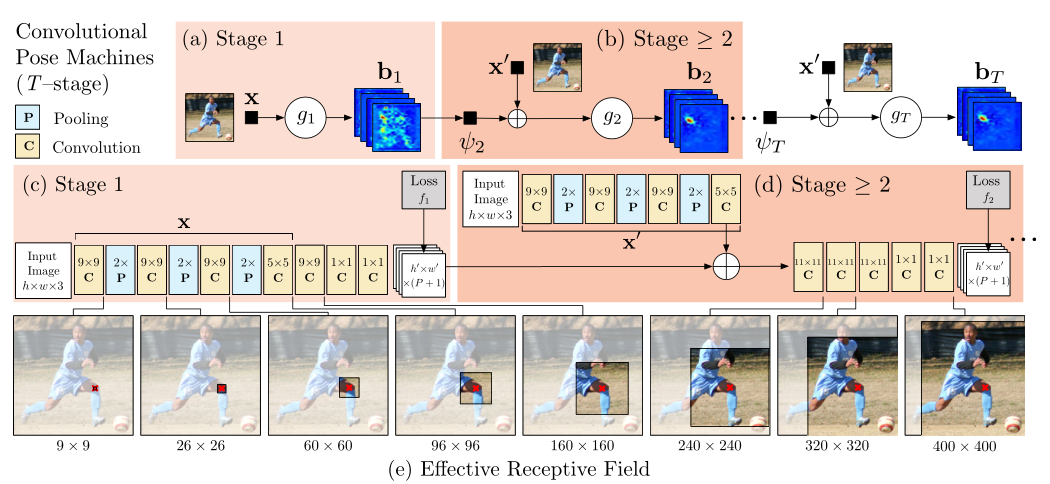
stage1: 输入是原图,经过卷积网络提取图像卷积特征X,后接两个1×1卷积输出heatmaps(shape为h'×w'×(P+1)),P+1通道表示heatmaps上每个像素位置是P个关键点(关节)+1个背景的得分socre。
stage2:
出发点:
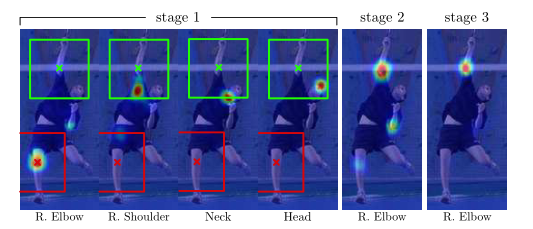
来自易于检测零件的信念图的空间上下文可以为定位难以检测的零件提供强有力的线索。肩部、颈部和头部的空间背景有助于在后续阶段消除右肘信念图上的错误(红色)和正确(绿色)估计。
利用“各个关键点以一致的几何配置出现”这一事实,后续阶段的预测器可以使用图像上位置z周围区域的带噪heatmaps生成空间上下文信息来提高预测结果。
第二阶段网络输出层的感受野必须足够大,以保证网络具有学习各个关键点间复杂和长距离关系的潜力。大的感受野可以通过池化操作得到(但要牺牲精度),也可以通过增大卷积核的尺寸来实现(会增加参数数量),也可以通过增加卷积层层数实现(训练的时候可能会遇到梯度消失的风险)。
输入包含三部分,(1)原图(2)stage1输出的heatmap(3)每个目标的中心约束map(见下图中的small center map); 输出的是P+1通道的heatmaps。
后面stage同stage2...
可以认为后一阶段输出的heatmap是对上一阶段heatmap的refine,且每一阶段的输出heatmap都对应有GT来计算损失函数,完成中间监督。
详细模型结构
(参考https://zhuanlan.zhihu.com/p/102468356)
stage1和stage2都输入了原图,stage3开始不再输入原图进行图像特征的计算,而是直接对stage2的中间卷积特征进行再卷积来计算图像特征,实际实现的结构示意图如下图所示:
其中stage2之后输入的small center map是使用图像中各个目标中心位置(关键点的x,y坐标中min与max平均)处高斯分布生成的,用于约束各个目标的位置。(只使用在训练阶段)
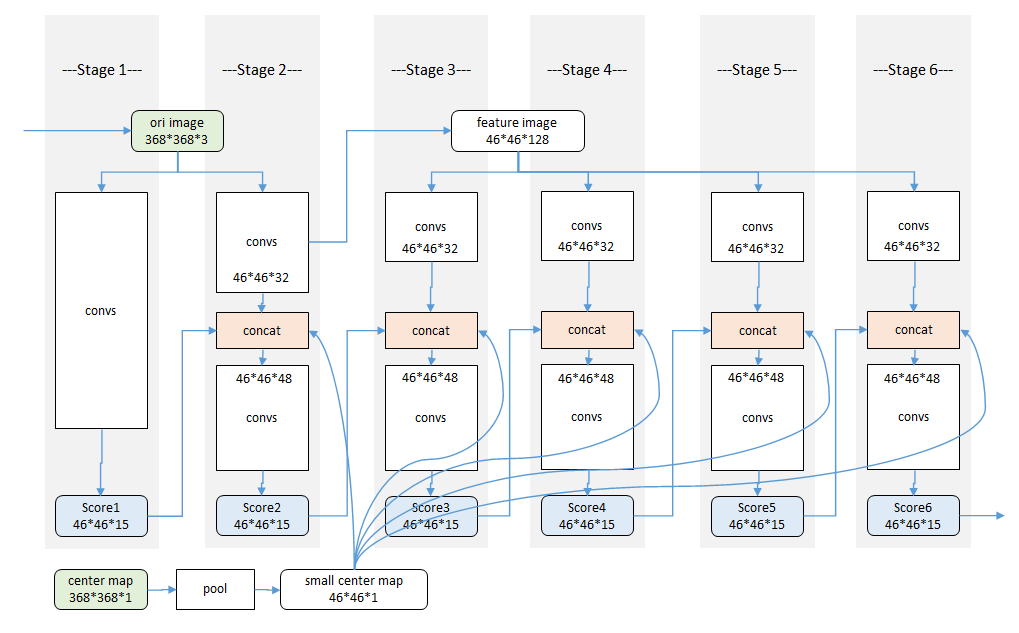
训练细节
输入:为了达到一定的精度,我们将输入的裁剪图像规格化为368×368。
损失函数:上述姿态机器的设计产生了一个可以有大量层的深层架构。训练这样一个具有许多层的网络可能容易出现梯度消失的问题,使用中间监督。p部分的belief-map写为b^p^∗(Yp=z),通过将高斯峰置于每个身体部位p的地面真值位置来创建。因此,我们旨在使每个级别的每个阶段的输出最小化的成本函数如下所示:
整个架构的总体目标是通过增加每个阶段的损失来实现的,具体如下所示:
我们制作了两套belief-map进行训练:一套包括每个人在主要受试者附近出现的所有峰值,另一种是我们只为主要受试者放置峰值。由于初始阶段仅依赖于局部图像证据进行预测,因此我们在第一阶段为损失层提供了第一组belief-map。我们将第二种类型的belief-map提供给后续阶段。
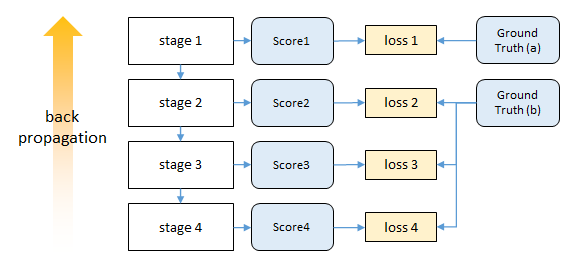
实验结果
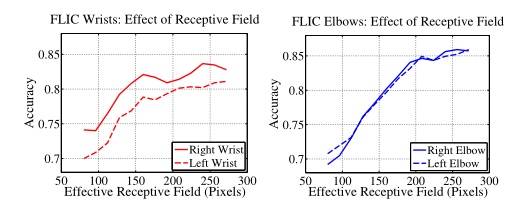
感受野
我们发现准确率会随着感受野的尺寸增大而提高,在FLIC数据集上,我们通过对归一化尺寸为304×304的输入图像进行一系列的实验,发现检测准确率随着感受野的变化而增大,在大约250像素的时候趋于饱和,而这个数字恰好是归一化后的目标(人)的大小。当然在这一对比实验过程中我们通过改变结构来保证参数数量不发生太大变化。
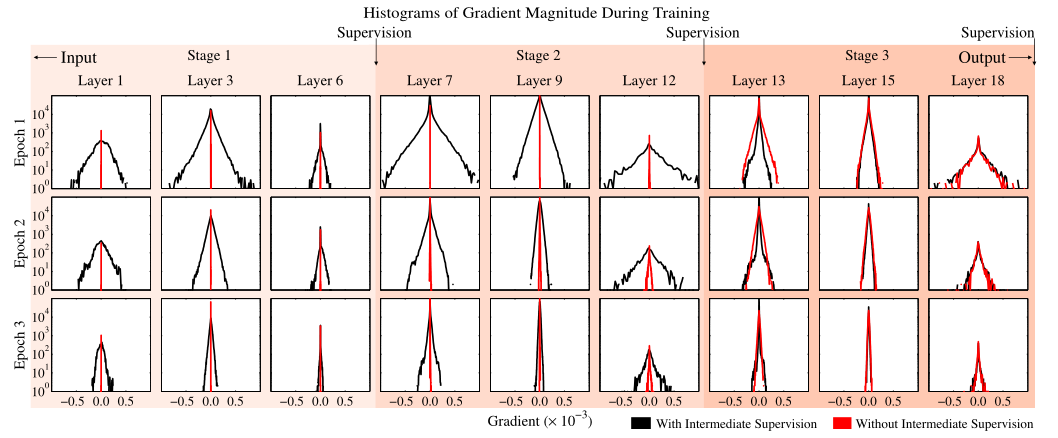
中间监督处理消失梯度
下图展示了 (是/否)带有中间监督的情况下,训练过程中不同网络深度处的梯度强度对比。在训练初期,最后一层的梯度分布方差都还挺大,若没有中间监督,越往前(层数越小)梯度都集中在0附近(梯度消失);若有中间监督,浅层的梯度分布方差也挺大,表明中间监督确实对梯度消失问题有帮助。训练后期,没有中间监督时层数越浅,梯度消失仍然越严重;而有中间监督的情况下,浅层的梯度分布方差没有训练初期那么大(但是也没消失),这表明了模型的收敛。
# CHP(2017 ICCV)
Compositional human pose regression
# Adversarial posenet(2017 ICCV)
Adversarial posenet: A structure-aware convolutional network for human pose estimation
# 2D-3D-Softargmax(2018 CVPR)
2d/3d pose estimation and action recognition using multitask deep learning
出发点:行为识别和人体姿态估计密切相关,但在文献中,这两个问题通常作为不同的任务处理。
- 相关任务可以相互受益,在这项工作提出了一个多任务框架。用于从静止图像中联合估计二维和三维姿态,以及从视频序列中识别人体行为。
- 因为大多数姿态估计方法都执行热图预测。这些基于检测的方法需要使用不可微的argmax函数来恢复关节坐标,作为后处理阶段,这打破了端到端学习所需的反向传播链。我们建议通过扩展可微soft-argmax来解决这个问题,用于关节二维和三维姿态估计。这使我们能够在姿态估计的基础上叠加行为识别,从而形成一个端到端可训练的多任务框架。
- 所提出的体系结构可以无缝地同时使用来自不同类别的数据进行训练。在四个数据集(MPII、Human3.6M、Penn Action和NTU)上报告的结果证明了我们的方法对目标任务的有效性。
整体结构
一种用于姿态估计和行为识别的多任务方法。从单个图像或帧序列中提供2D/3D姿态估计。姿态和视觉信息用于在统一的框架中预测行为。
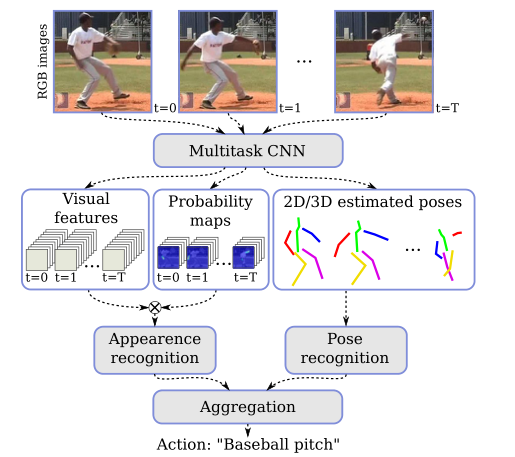
Human pose estimation
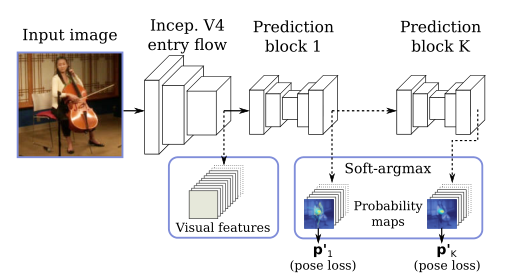
网络体系结构的入口流程基于Inception-V4,用于提供基本特征提取。
K个预测块被用于细化估计,从中我们使用最后一个预测p^k^作为我们的估计姿态p。每个预测块由八个残差深度方向的卷积组成,分成三个不同的分辨率。作为副产品,我们还可以访问低级视觉特征和中间联合概率图。
这些都是通过soft-argmax层间接学习到的。
给定输入信号,主要思想是考虑u参数可以在输入信号的归一化后近似于具有分布性质。事实上,对于一个足够尖锐(轻量级)的分布,期望值应该接近最大后验概率(MAP)估计。
使用标准化指数函数(Softmax),因为它减轻了低于最大值的值的不良影响,并增加了结果分布的“尖锐性”。对于作为输入的2D热图,归一化信号可以解释为关节处于位置(x,y)的概率图,并且关节位置的期望值由归一化信号上的期望值给出:
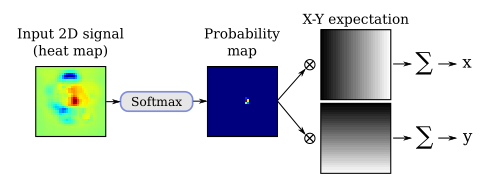
其中,x是维数为Wx×Hx的输入热图,Φ是Softmax归一化函数。
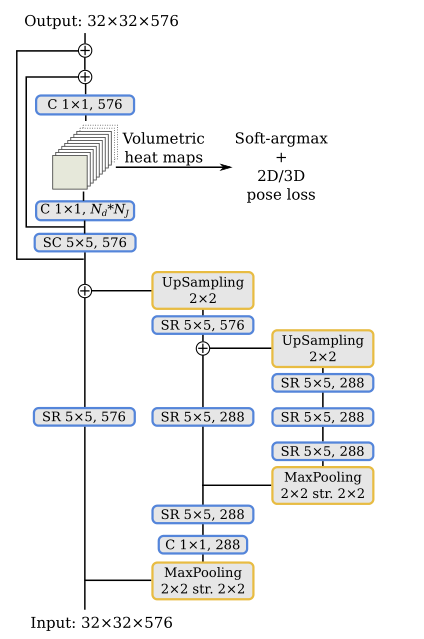
3D姿态估计:通过将二维热图扩展到体积表示,我们将二维姿态回归扩展到三维场景。我们定义了与深度分辨率相对应的Nd叠加二维热图。(x,y)坐标中的预测是通过对平均热图应用Soft-argmax操作来执行的,而z分量是通过对x和y维度中的平均体积表示应用一维Soft argmax来回归的。
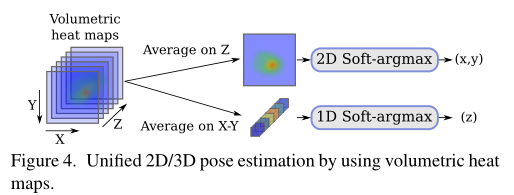
详细模型结构
基于深度可分离卷积SC的可分离残差模块 (SR),输入与输出通道不等则选左边,相等右边。
基于Inception-V4的共享网络(入口流)。C:卷积,SR:可分离残差模块。
姿态估计的预测块,其中Nd是每个关节的深度热图数,NJ是身体关节数。C:卷积,SR:可分离残差模块。
Human action recognition 提议的行为识别方法分为两部分,一部分基于身体关节坐标序列,我们称之为基于姿态的识别,另一部分基于视觉特征序列,我们称之为基于外观的识别。将每个部分的结果结合起来,以估计最终行动标签。
Pose-based recognition
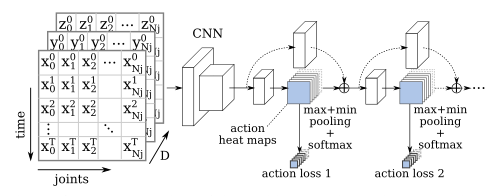
为了探索身体关节位置编码的高级信息,我们将一系列具有NJ关节的T姿态转换为类似图像的表示。我们选择将时间维度编码为垂直轴,将关节编码为水平轴,并将每个点的坐标((x,y)编码为2D,(x,y,z)编码为3D)作为通道。
通过这种方法,我们可以使用经典的二维卷积直接从身体关节的时间序列中提取模式。由于姿态估计方法基于静止图像,我们使用时间分布的抽象来处理视频片段,这是一种处理单个图像和视频序列的简单技术。
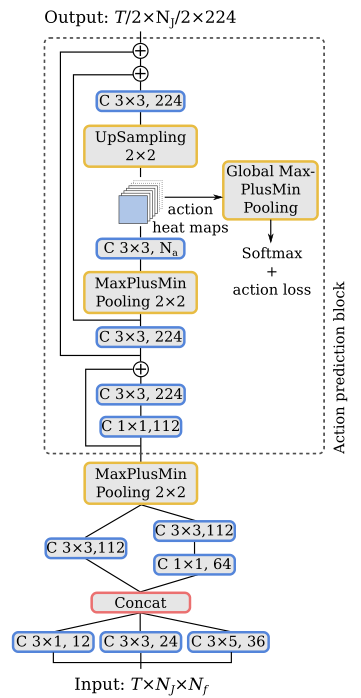
为了产生视频剪辑每个行为的输出概率,必须在行为图上执行一个池操作。为了对每个行为的最强响应更敏感,我们使用max plus min pooling,然后使用Softmax激活。此外,受人体姿态回归方法的启发,我们通过在K个预测块中使用具有中间监督的堆叠结构来细化预测。然后将每个预测块的行为热图重新注入下一个行为识别块。
详细模型结构
用于行为识别的网络架构。行为预测块可以重复K次。同样的架构用于姿态和外观识别,除了姿态,每个卷积使用这里显示的特征数量的一半。T表示帧数,Na表示行为数。
Appearance-based recognition
外观特征被输入行为识别网络,类似于基于姿态的动作识别块,不同之处在于它依赖于局部外观特征,而不是关节坐标,即视觉特征取代身体关节的坐标。
构建外观特征输入
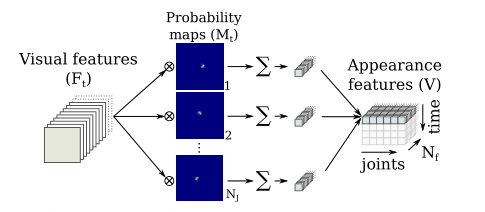
为了提取局部外观特征,我们将视觉特征的张量Ft(Wf×Hf×Nf)与全局最后获得的概率图M t(Wf×Hf×NJ)相乘,其中Wf×Hf是特征图的大小,Nf是特征的数量,NJ是关节的数量。
我们没有像克罗内克乘积那样单独乘以每个值,而是将每个通道相乘,得到大小为 (Wf×Hf×NJ×Nf)的张量。然后,空间维度被一个和折叠,从而得到一个时间t的外观特征,大小为 (NJ×Nf)。对于一系列帧,我们将t={0,1,…,t}的每个外观特征连接起来,从而得到视频片段外观特征V(T×NJ×Nf)。
我们的多任务框架对于基于外观的部分有两个好处:
- 第一,由于大部分计算是共享的,因此它在计算上非常高效。
- 第二,提取的视觉特征更加健壮,因为它们针对不同的任务和不同的数据集同时进行训练。
Action aggregation
- 一些动作很难仅通过高水平的姿态表示来区分。例如,如果我们只考虑身体关节,喝水和打电话的动作非常相似,但如果我们有与杯子和电话对应的视觉信息,则很容易将其分离。另一方面,其他动作与视觉信息没有直接关系,但与身体动作有关,如敬礼和触摸胸部,在这种情况下,姿态信息可以提供补充信息。
- 为了探索姿态和外观模型的贡献,我们使用一个完全连接的层和Softmax激活将各自的预测结合起来,从而给出我们模型的最终预测。
训练过程
- 我们使用RMSprop优化器优化姿态回归部分,初始学习率为0.001,当验证分数稳定时,初始学习率降低了0.2倍,并批量生成24幅图像。
- 对于动作识别任务,我们使用预先训练好的姿态估计模型同时训练姿态和外观模型,初始权重为冻结。在这种情况下,我们使用了一个经典的SGD优化器,Nesterov动量为0.98,初始学习率为0.0002,在验证平稳时减少了0.2倍,并使用了一批2个视频剪辑。
- 当验证准确性停滞时,我们将最终学习率除以10,并对整个网络进行微调,使其持续5个epochs以上。
损失函数
对于姿态估计任务,我们在预测姿态上使用弹性净损失函数对网络进行训练:
式中,ˆpn和pn分别是第n个关节的估计位置和真值位置。
对于动作识别任务,我们使用分类交叉熵损失训练网络。
在训练中,我们从视频样本中随机选择带有T帧的固定大小片段。在测试中,我们报告单剪辑或多剪辑的结果。
实验结果
Ablation study
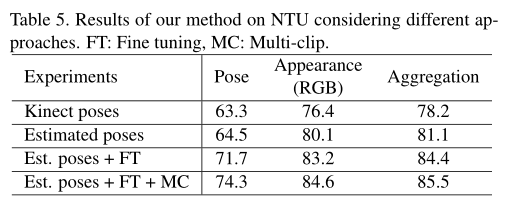
我们的方法的有效性依赖于三个主要特征:
- 首先,多个预测块提供了对动作准确性的持续改进,
- 其次,由于我们的完全可微架构,我们可以将模型从RGB帧微调到预测动作,从而显著提高准确性。
- 第三,所提出的方法还受益于互补的外观和姿态信息,这些信息在聚合后可以提高分类精度。
# Posefix(2019 CVPR)
Posefix: Model-agnostic general human pose refinement network
# FPD(2019 CVPR)
Fast human pose estimation
# Soft-gated Skip Connections(2020 FG)
Toward fast and accurate human pose estimation via soft-gated skip connections
# SCNet (2020 CVPR)
# UDP (2020 CVPR)
# LiteHRNet (2021 CVPR)
Lite-HRNet: A Lightweight High-Resolution Network
出发点: 人体姿势估计需要高分辨率表示才能实现高性能。基于对模型效率的日益增长的需求,本文研究了在计算资源有限的情况下开发高效高分辨率模型的问题。
- 现有的高效网络主要从两个角度进行设计:
- 一种是借用分类网络的设计,如MobileNet和ShuffleNet,以减少矩阵向量乘法中的冗余,其中卷积运算占主要成本。
- 另一种是通过各种技巧来调解空间信息丢失,例如编码器-解码器架构和多分支架构。
- 现有的高效网络主要从两个角度进行设计:
本文贡献:
- 我们首先通过简单地结合ShuffleNet中的shuffle块和HRNet中的高分辨率设计模式来研究一个简单的轻量级网络。在位置敏感问题中,HRNet在大型模型中表现出更强的能力,例如语义分割、人体姿势估计和目标检测。目前尚不清楚高分辨率是否有助于小型模型。我们的经验表明,直接组合优于ShuffleNet、MobileNet和Small HRNet1。
- 为了进一步实现更高的效率,我们引入了一个高效的单元,称为conditional channel weighting,用于执行跨信道的信息交换,以取代shuffle块中代价高昂的逐点(1×1)卷积。引入高效单元后网络称为 Lite-HRNet。性能优于shuffle块和HRNet的简单组合(naive-Lite-HRNet)。
- conditional channel weighting非常有效:其复杂度与信道数呈线性关系,低于逐点卷积的二次时间复杂度。例如,利用64×64×40和32×32×80的多分辨率特性,conditional channel weighting 单元可以将shuffle块的整体计算复杂度降低80%。
- 我们的解决方案从所有通道和多个分辨率中学习权重,这些分辨率在HRNet的并行分支中随时可用。它使用权重作为桥梁,在通道和分辨率之间交换信息,补偿逐点(1×1)卷积所起的作用。
Naive Lite-HRNet
Shuffle blocks
『高性能模型』轻量级网络ShuffleNet_v1及v2 - 叠加态的猫 - 博客园 (cnblogs.com) (opens new window)
ShuffleNet_V2中的shuffle块首先将通道分割为两个分区。一个分区经过1×1卷积、3×3深度卷积和1×1卷积序列,输出与另一个分区连接。最后,串接的通道被shuffle。下图a。
其中的DWConv表示的是Depthwise convolution,其输入和输入通道数相同,并且每个卷积核只与一个特征通道进行卷积,其使用线性激活函数。DWConv实现时将groups属性设置为和out_channels相同即可。
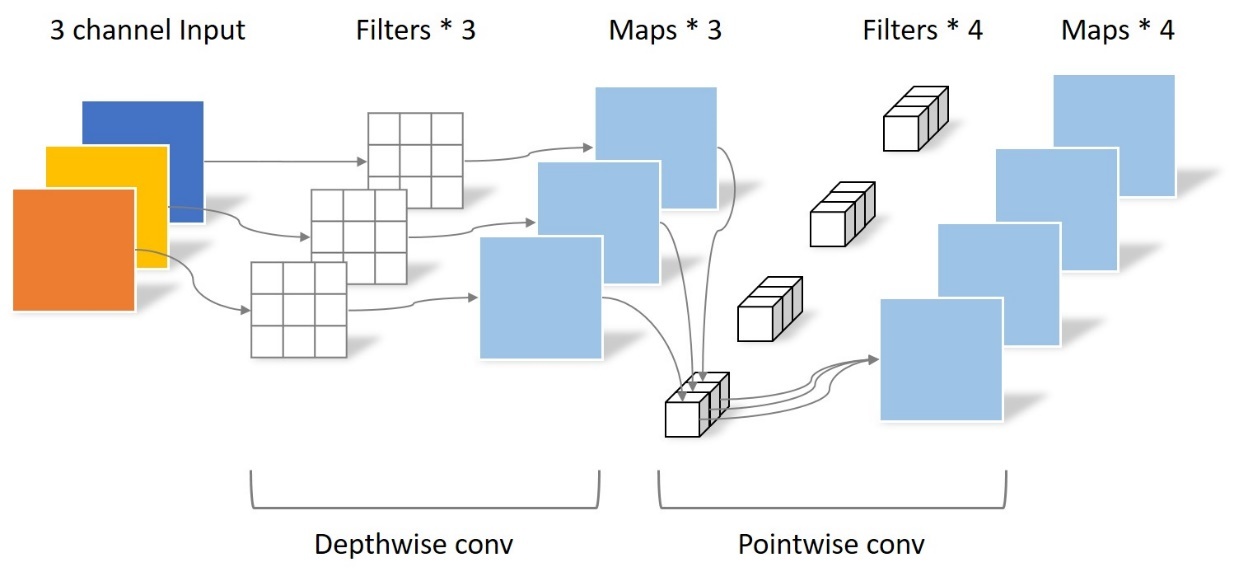
(a)shuffle块。(b) 我们的conditional channel weighting块。虚线表示其他分辨率的表示以及分配给其他分辨率的权重。H=交叉分辨率加权函数。F=空间加权函数。
Small HRNet-W16
它由一个高分辨率的stem(由两个步幅为2的3×3的卷积组成)作为第一级,逐渐增加高分辨率到低分辨率的流作为主体。主体有一系列阶段,每个阶段包含平行的多分辨率流和重复的多分辨率融合。
Simple combination
我们采用Shuffle blocks替换small HRNet主干中的第二个3×3卷积,并替换所有正常的residual blocks(由两个3×3卷积组成)。多分辨率融合中的正常卷积被可分离卷积所取代,从而形成了一个 naive Lite-HRNet。
1×1 convolution is costly
1×1卷积相对于信道数(C)具有二次时间复杂度(Θ(C^2^))。3×3 DWconv具有线性时间复杂度(Θ(9C)。在shuffle块中,两个1×1卷积的复杂度远高于深度卷积:对于通常情况C>5,Θ(2C2)>Θ(9C)。
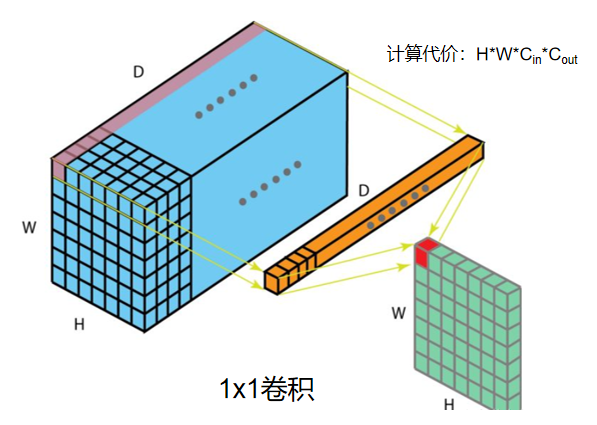
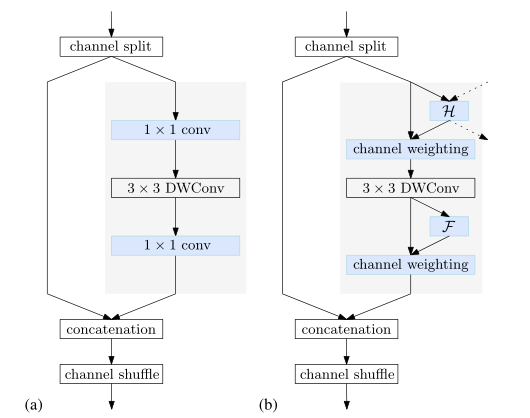
Conditional channel weighting
我们建议在naive Lite HRNet中使用元素加权操作来代替1×1卷积,后者在第s阶段具有s分支。第s解析分支的元素加权操作写为:
其中,Ws是一个权重图,一个大小为Ws×Hs×Cs的三维张量,以及⊙ 是按元素的乘法运算符。复杂度与通道数Θ(C)成线性关系,远低于shuffle块中的1×1卷积。我们通过使用单个分辨率的通道和所有分辨率的通道来计算权重Ws,如上图(b)所示,并表明权重在通道和分辨率之间起着交换信息的作用。
两种条件通道加权(即两种计算Ws方法):
Cross-resolution weight computation
考虑到第s级,有s个平行分辨率和s个权重图W1,W2,Ws,每个都对应于相应的分辨率。我们使用一个轻量级函数Hs(·)计算所有通道在不同分辨率下的s权重图:
轻量级函数Hs(·)实现:
其中{X1,…,Xs}是s分辨率的输入映射**。X1对应于最高分辨率,Xs对应于第s个最高分辨率**。我们在{X1,X2,…,Xs−1}上执行自适应平均池(AAP) :X′1=AAP(X1),X′2=AAP(X2),X's−1=AAP(Xs−1) ,其中AAP将任何输入大小合并为给定的输出大小Ws×Hs。然后我们连接{X′1,X′2,…,X′s−1} 和Xs一起。
然后经过如下运输,Conv是1x1 Conv:(2个卷积使用了bottleneck结构,先减少通道数,再增加)
生成由s分区、W′1、W′2,W‘s(每种分辨率对应一种)。
s− 1权重图,W′1,W′2,W's−1,被上采样到相应的分辨率,输出W1,W2,Ws−1,用于后续的元素通道加权。
优点:
- 位置i处的权重向量wsi的每个元素(来自权重映射Ws)从在所有分辨率下,从同一位置的所有输入通道接收信息。
- Hs(·)应用于小分辨率,因此计算复杂度很低。
Spatial weight computation
对于每个分辨率,我们还计算与空间位置一致的空间权重:所有位置的权重向量wsi都是相同的。权重取决于单个分辨率中输入通道的所有像素:
这里,函数Fs(·)被实现如下。全局平均池(GAP)操作符用于从所有位置收集空间信息。数据维度(11C)=GAP(HWC)
全连接相当于1x1卷积,这里先减少通道维度再恢复。
实例
Lite HRNet由高分辨率stem和主体组成,以保持高分辨率表示。茎部有一个步幅2的3×3卷积,和一个shuffle块,作为第一阶段。主体部分有一系列模块化模块。 每个模块包括两个条件信道加权块和一个多分辨率融合。每个分辨率分支的通道尺寸分别为C、2C、4C和8C。Lite-HRNet-N中的N表示层数。( ccw = conditional channel weight)

计算复杂度比较
存疑🤔(具体参考代码,这里记录有差)
实现代码上 /ratio
两个1X1卷积之间结合使用Bottleneck结构
Bottleneck结构就是为了降低参数量,Bottleneck 三步走是先 PW 对数据进行降维,再进行常规卷积核的卷积,最后 PW 对数据进行升维(类似于沙漏型)。
实验结果
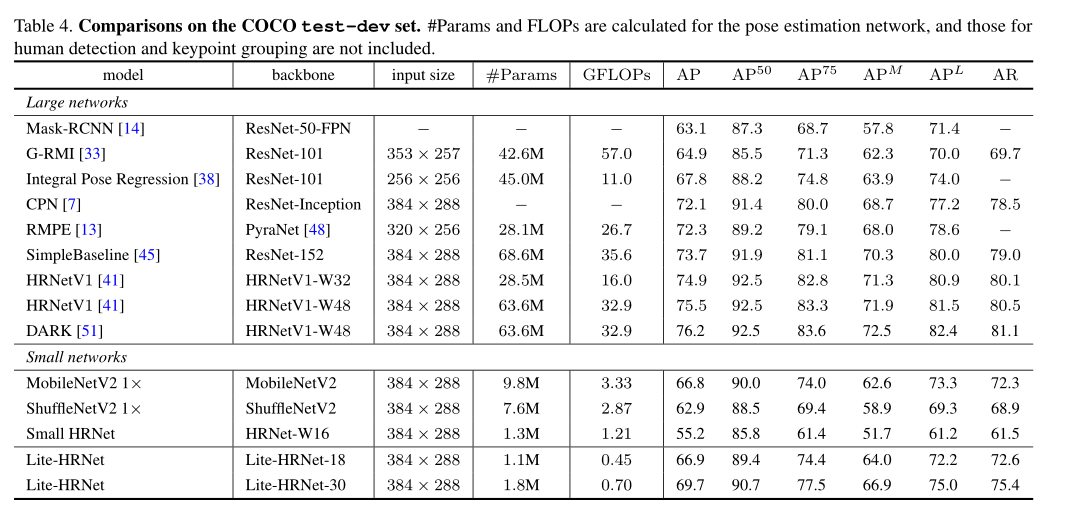
我们的Lite-HRNet-30达到69.7 AP分数。它明显优于小型网络,并且在GFLOP和参数方面更有效。与大型网络相比,我们的Lite-HRNet-30优于Mask RCNN、G-RMI和Integral Pose Regression。虽然与一些大型网络存在性能差距,但我们的网络的GFLOP和参数要低得多。
Ablation Study
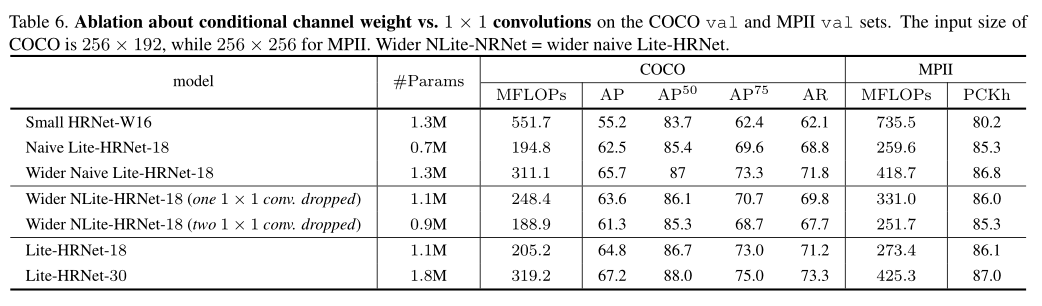
Lite-HRNet vs. Small HRNet/ Naive Lite-HRNet
wider naive Lite-HRNet是增加层使参数与small HRNet-W16一致作比较。
Spatial and multi-resolution weights
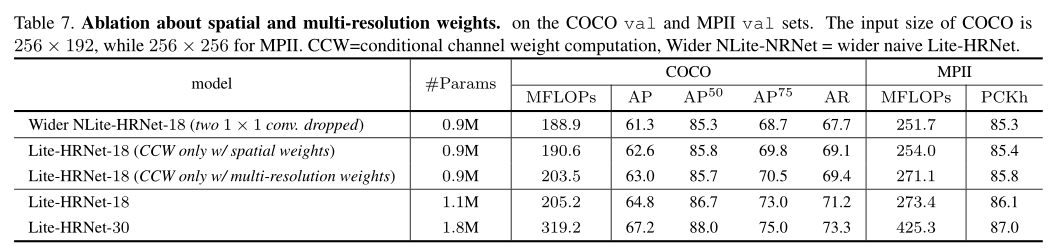
我们通过改变空间加权和交叉分辨率加权的排列顺序进行了实验,获得了类似的性能。仅使用两个空间权重或两个交叉分辨率权重的实验几乎会导致0.3的下降。
# PRTR(2021 CVPR)
Pose Recognition with Cascade Transformers
# TransPose(2021 ICCV)
TransPose: Keypoint Localization via Transformer
# 多人-Top down
# Simple baselines(2018 ECCV)
Simple baselines for human pose estimation and tracking
# CPN(2018 CVPR)
Cascaded pyramid network for multi-person pose estimation
# HRNet(2019 CVPR)
Deep high-resolution representation learning for human pose estimation
Deep High-Resolution Representation Learning for Visual Recognition
解读: https://zhuanlan.zhihu.com/p/134253318
code:HRNet (github.com) (opens new window)
当前网络局限:
大多数现有方法通过网络传递输入,通常由串联的高到低分辨率子网络组成,然后提高分辨率。
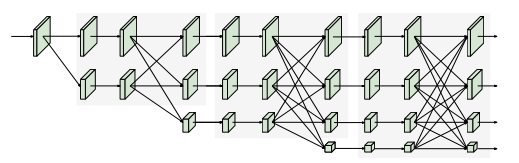
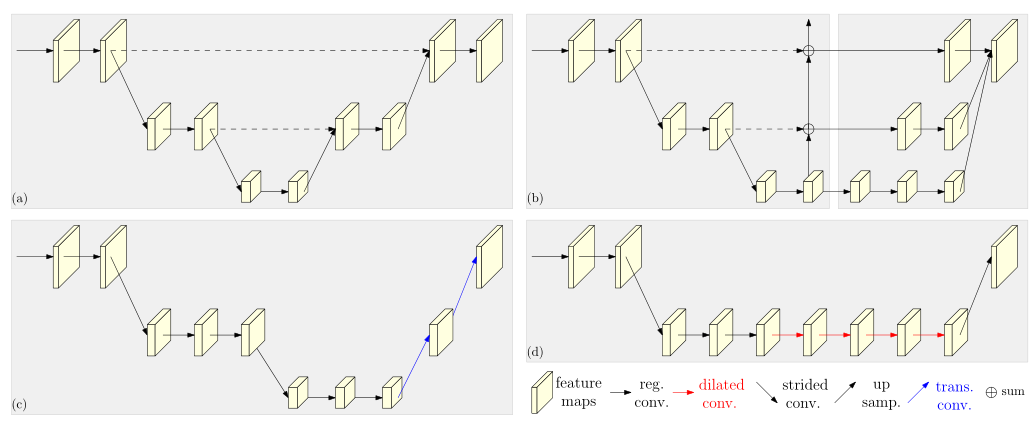
最新开发的分类网络,包括AlexNet、VGGNet、GoogleNet、ResNet等,都遵循LeNet-5的设计规则。该规则如图(a)所示:逐渐减小特征地图的空间大小,将高分辨率到低分辨率的卷积串联起来,形成低分辨率表示,并进一步处理以进行分类。
位置敏感任务需要高分辨率表示,例如语义分割、人体姿势估计和目标检测。先前最先进的方法采用高分辨率恢复过程,以从图(b)所示的分类或类分类网络输出的低分辨率表示提高表示分辨率,例如 SegNet , DeconvNet , U-Net and Hourglass , encoder-decoder and SimpleBaseline 。此外,dilated convolutions用于移除一些下采样层,从而产生中等分辨率表示。

基于高到低和低到高框架的典型姿势估计网络的图示。(a) Hourglass .Cascaded pyramid networks. (c) SimpleBaseline(d) Combination with dilated convolutions
本文贡献:
我们提出了一种新的体系结构,即高分辨率网络(HRNet)
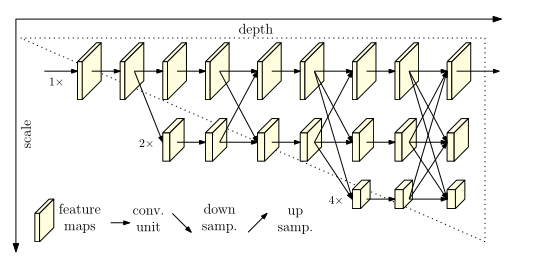
- 我们的方法是并行连接高分辨率到低分辨率的子网络,而不是像大多数现有解决方案那样串联。因此,我们的方法能够保持高分辨率,而不是通过从低到高的过程恢复分辨率,因此预测的热图在空间上可能更精确。
- 大多数现有的融合方案聚合了低级和高级表示。相反,我们通过重复的多尺度融合,在相同深度和相似级别的低分辨率表示的帮助下提高高分辨率表示,反之亦然。从而使高分辨率表示也有丰富的姿势估计。因此,我们预测的热图可能更准确。
- 我们通过网络输出的高分辨率表示来估计关键点。
网络
该网络由一个stem、主体(HRNet)、representation head组成。
该stem由两个降低分辨率的跨步卷积组成;我们将图像输入一个stem,该stem由两个步长为2的 3×3卷积组成,将分辨率降低到1/4,然后主体以相同的分辨率输出表示(1/4)。
主体以与其输入特征图相同的分辨率输出特征图;
representation head 选择进行后续任务预测的高分辨率特征图(或低分辨率),即用于估计选择关键点位置并转换为全分辨率的热图。
主体——HRNet(网络实例化 )
主体部分包含四个阶段和四个并行卷积流。分辨率分别为1/4、1/8、1/16和1/32。**当分辨率降低到一半,宽度(通道数)增加到两倍。**即四种分辨率的卷积宽度(通道数)分别为C、2C、4C和8C。
第一阶段包含4个residual units ,其中每个单元(与ResNet-50相同)由通道数为64的 bottleneck 形成,然后是一个3×3卷积,将特征映射的宽度减小到C。
第二、第三、第四阶段分别包含1、4、3个exchange block(或称 模块化块)。一个交换块包含4个 residual units(basicblock)和一个exchange unit在分辨率之间,其中每个单元在每个分辨率中包含两个3×3卷积。综上所述,共有8个exchange unit,即进行了8次多尺度融合。
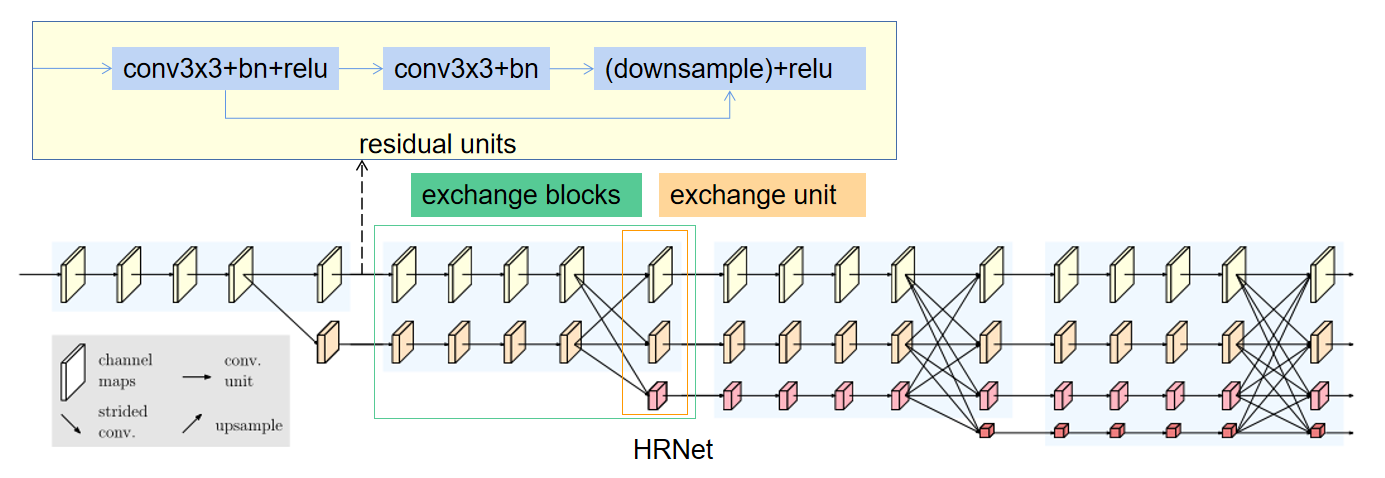
🐱🏍注意:在我们的实验中,我们研究了一个小网络和一个大网络:HRNet-W32和HRNet-W48,其中32和48分别代表最后三个阶段的高分辨率子网络的通道数(C)。对于HRNet-W32,其他三个并行子网的宽度分别为64、128、256,对于HRNet-W48,宽度分别为96、192、384。
重复多分辨率融合
融合模块的目标是在多分辨率表示中交换信息。
同分辨率的层直接复制。
需要升分辨率的使用bilinear upsample (或 nearest neighbor up-sampling) + 1x1卷积将channel数统一。
需要降分辨率的使用strided为2 的 3x3 卷积。
至于为何要用strided 3x3卷积,这是因为卷积在降维的时候会出现信息损失,使用strided 3x3卷积是为了通过学习的方式,降低信息的损耗。所以这里没有用maxpool或者组合池化。
三个feature map融合的方式是相加。
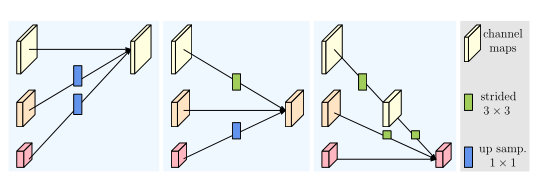
Representation Head
我们有三种表示头,如图4所示,分别称为HRNetV1、HRNetV2和HRNetV2p。
HRNetV1:输出是仅来自高分辨率流的表示。其他三种表述被忽略。如图(a)所示。
HRNetV2:我们通过双线性上采样重新调整低分辨率表示尺度,而不将通道数更改为高分辨率,并将四种表示拼接起来,然后进行1×1卷积以混合四种表示。如图(b)所示。
HRNetV2p:我们通过将HRNetV2的高分辨率表示输出降采样到多个级别来构造多级表示。如图(c)所示。
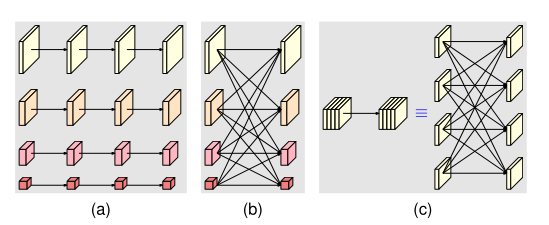
在本文中,我们将展示将HRNetV1应用于人体姿势估计、HRNetV2应用于语义分割和HRNetV2p应用于对象检测的结果。
如下主要用于分类网络:
分析
我们分析了模块化块,它分为两部分:多分辨率并行卷积(图a)和多分辨率融合(图b)。
- 多分辨率并行卷积类似于群卷积。它将输入通道划分为几个通道子集,并分别在不同的空间分辨率上对每个子集执行规则卷积,而在组卷积中,分辨率是相同的。 这种联系意味着多分辨率并行卷积可以享受群卷积的一些好处。
- 多分辨率融合单元类似于规则卷积的多分支全连接形式,如图c所示。
- 规则卷积可分为多个小卷积。输入通道被划分为几个子集,输出通道也被划分为几个子集。输入和输出子集以完全连接的方式连接,每个连接都是一个规则卷积。输出通道的每个子集是每个输入通道子集上卷积输出的总和。
- 不同之处在于,我们的多分辨率融合需要处理分辨率的变化。多分辨率融合和规则卷积之间的联系为探索HRNetV2和HRNetV2p中的所有四种分辨率表示提供了证据。
实验结果
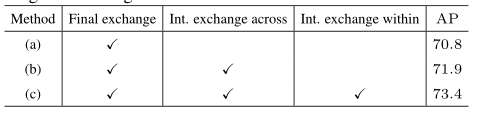
重复多尺度融合消融实验。我们实证分析了重复多尺度融合的效果。我们研究了网络的三种变体。(a) 没有中间交换单元(1个融合):除最后一个交换单元外,多分辨率子网之间没有交换。(b) 跨级交换单元(3个熔合):每个级内的并行子网之间没有交换。(c) 跨级和级内交换单元(共8个融合):这是我们提出的方法。所有的网络都是从零开始训练的。表给出的COCO验证集的结果表明,多尺度融合是有帮助的,更多融合会带来更好的性能。
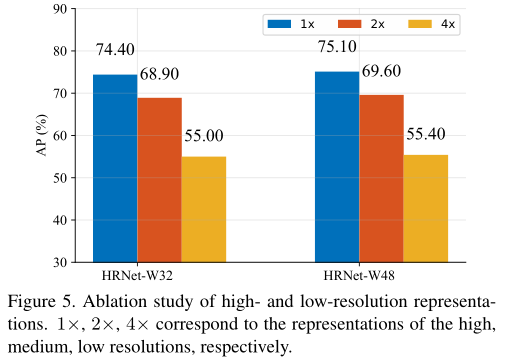
我们从两个方面研究了表征分辨率对姿态估计性能的影响:
从高到低检查由每个分辨率的特征图估计的热图的质量,我们通过为ImageNet分类预先训练的模型来训练我们的大小网络。我们的网络输出从高到低的四个响应图。较低分辨率的热图预测质量太低,AP分数低于10分。如图比较表明,分辨率确实会影响关键点预测质量。
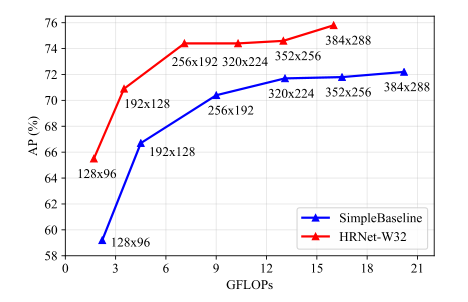
图显示了与SimpleBaseline(ResNet-50)相比,输入大小如何影响性能。由于在整个过程中保持了高分辨率,较小输入尺寸的改善比较大输入尺寸的改善更为显著。
Representation Head 比较
人体姿态估计中:HRNetV2-W32的AP得分为73.6,略高于HRNetW32的73.4分,两者性能几乎相同,因此我们选择HRNetV1,因为它的计算复杂度稍低。
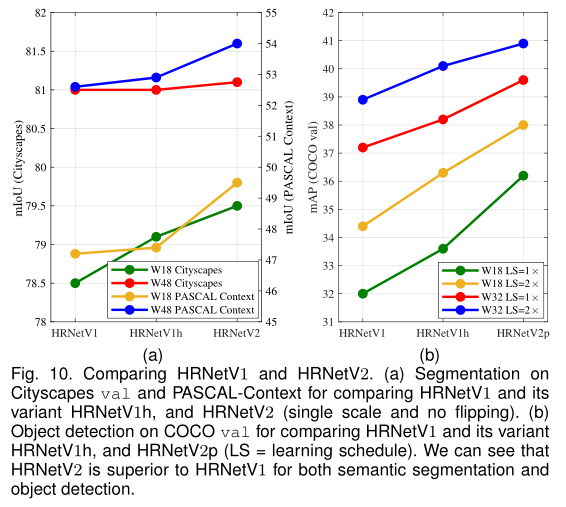
比较HRNetV2、HRNetV2p和HRNetV1在语义分割和目标检测方面的差异:
图中给出的分割和对象检测结果表明,HRNetV2显著优于HRNetV1,除了在Cityscapes数据集使用大模型分割的情况下增益较小。(图a红线)
HRNetV1h:它是通过附加1×1卷积来将输出高分辨率表示的维度与HRNetV2的维度对齐而构建的。(HRNetV2融合拼接过后会经过1x1卷积)
图中的结果表明,该变体对HRNetV1略有改善,这意味着将HRNetV2中低分辨率并行卷积的表示进行聚合对于提高性能至关重要
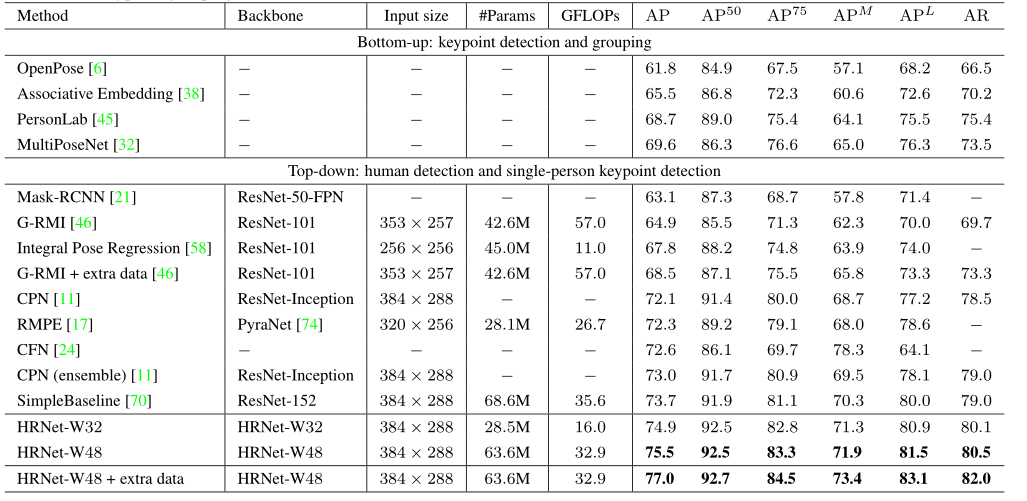
COCO测试集的比较
# MSPN(2019 arXiv)
Rethinking on multi-stage networks for human pose estimation
# Graph-PCNN(2020 ECCV)
Graph-pcnn: Two stage human pose estimation with graph pose refinement
# RSN(2020 ECCV)
Learning delicate local representations for multiperson pose estimation
# OASNet(2020 ECCV)
Occlusion-aware siamese network for human pose estimation
# ViPNAS (2021 CVPR)
ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search(2021 CVPR)
# FCPose(2021 CVPR)
FCPose: Fully Convolutional Multi-Person Pose Estimation With Dynamic Instance-Aware Convolutions
# TokenPose(2021 ICCV)
TokenPose:Learning Keypoint Tokens for Human Pose Estimation
# 多人-Bottom up
# Deepcut(2016 CVPR)
Deepcut: Joint subset partition and labeling for multi person pose estimation
# OpenPose(2017 CVPR)
Realtime multi-person 2d pose estimation using part affinity fields
# Associative embedding(2017 NeurIPS)
Associative embedding: End-to-end learning for joint detection and grouping
# Multiposenet(2018 ECCV)
Multiposenet: Fast multiperson pose estimation using pose residual network(2018 ECCV)
# SPR(2019 CVPR)
Single-stage multiperson pose machines
# Higherhrnet(2020 CVPR)
Higherhrnet: Scale-aware representation learning for bottomup human pose estimation
# SWAHR(2021 CVPR)
Rethinking the Heatmap Regression for Bottom-Up Human Pose Estimation
# CenterGroup(2021 ICCV)
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
# SIMPLE(2021 AAAI)
SIMPLE: SIngle-network with Mimicking and Point Learning for Bottom-up Human Pose Estimation
# PINet(2021 NeurIPS)
Robust Pose Estimation in Crowded Scenes with Direct Pose-Level Inference
# 基于视频(估计/跟踪)
# 单人
# ST-AOG(2015 CVPR)
Joint action recognition and pose estimation from video
# Personalizing ConvNet(2016 CVPR)
Personalizing human video pose estimation(2016 CVPR)
# Thin-slicingNet(2017 CVPR)
Thin-slicing network: A deep structured model for pose estimation in videos
# LSTM-PM(2018 CVPR)
LSTM pose machines
# DKD(2019 ICCV)
Dynamic kernel distillation for efficient pose estimation in videos
# UniPose(2020 CVPR)
Unipose: Unified human pose estimation in single images and videos
# BlazePose(2020 CVPRW)
BlazePose: On-device Real-time Body Pose tracking
出发点:提出一种用于人体姿态估计的轻量级卷积神经网络体系结构——BlazePose,专门用于移动设备上的实时推理。
- 热图选择可以以最小的开销扩展到多人,但它使单人的模型比适用于移动电话实时推理的模型大得多。与基于热图的技术相比,基于回归的方法虽然计算要求较低且更具可扩展性,但却试图预测平均坐标值,通常无法解决潜在的模糊性。
- 在我们的工作中,我们扩展了参数数量较少,叠层沙漏结构也能显著提高预测质量的想法,并使用编码器-解码器网络架构来预测所有关节的热图,然后使用另一个编码器直接回归到所有关节的坐标。我们工作背后的关键洞见是,在推理过程中可以丢弃热图分支,使其足够轻,可以在移动设备上运行。
Inference pipeline
我们的管道由一个轻量级身体姿态检测器和一个姿态跟踪器网络组成。跟踪器预测关键点坐标、当前帧上的人物以及当前帧的精细感兴趣区域。当跟踪器显示没有人在场时,我们在下一帧重新运行探测器网络。

Person detector
出发点:大多数现代目标检测解决方案的最后一个后处理步骤都依赖于非最大抑制(NMS)算法。这适用于自由度很少的刚性对象。然而,这种算法在包含高度关节化姿态(如人类的姿态)的场景中会失效,例如人们挥手或拥抱。这是因为多个不明确的框满足NMS算法的联合交集(IoU)阈值。
为了克服这一局限性,我们着重于检测相对刚性身体部位(如人脸或躯干)的边界框。
我们观察到,在许多情况下,向神经网络发送的有关躯干位置的最强信号是人的脸(因为它具有高对比度特征,外观变化较少)。为了使这样的人检测器快速、轻便,我们提出了一个强有力的假设,即在我们的单人用例中,人的头部应该始终可见,但对于AR应用程序来说,这是有效的。
因此,我们使用快速设备人脸检测器作为个人检测器的代理。该面部检测器可预测其他特定于人的对齐参数:人的臀部之间的中点、环绕整个人的圆圈的大小,以及倾斜度(连接两个肩部中点和臀部中点的线条之间的角度)。
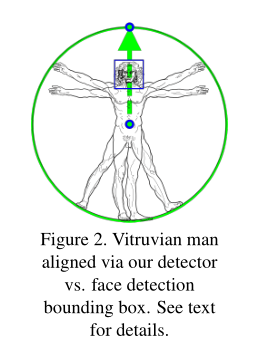
Topology
我们利用BlazeFace、BlazePalm和Coco使用的超集,提出了一种新的拓扑结构,使用人体上的33个点。这使我们能够与各自的数据集和推理网络保持一致。
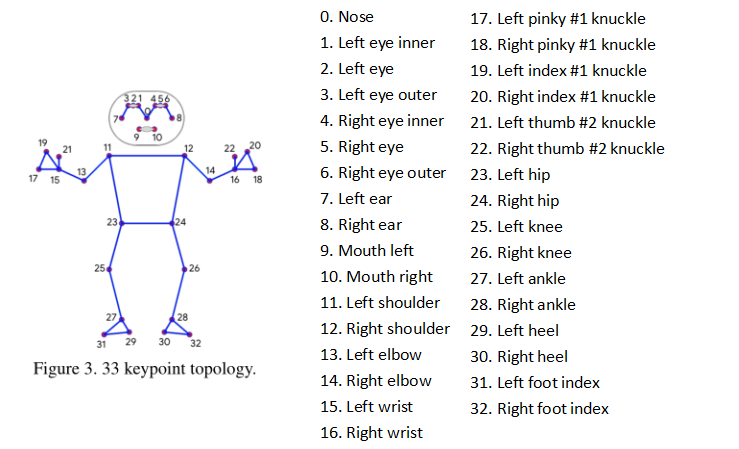
神经网络结构
我们系统的姿势估计组件预测所有33个人关键点的位置,并使用管道第一阶段提供的个人定位建议。
我们采用了组合热图、偏移和回归方法。我们仅在训练阶段使用热图和补偿损失,并在运行推理之前从模型中删除相应的输出层。因此,我们有效地使用热图来监督轻量级嵌入,然后由回归编码器网络使用。
我们叠加了一个基于热图的微型编码器-解码器网络和一个随后的回归编码器网络。我们积极利用网络所有阶段之间的跳过连接,以实现高级和低级功能之间的平衡。然而,回归编码器的梯度不会传播回经过热图训练的特征(请注意图中的梯度停止连接)。我们发现,这不仅改善了热图预测,而且大大提高了坐标回归的精度。
数据集
与大多数使用热图检测关键点的现有姿势估计解决方案相比,我们基于跟踪的解决方案需要初始姿势对齐。我们将数据集限制在可以看到整个人,或者可以自信地标注髋部和肩部关键点的情况下。为了确保模型支持数据集中不存在的严重遮挡,我们使用了大量遮挡模拟增强。我们的训练数据集由60K图像和25K图像组成,其中场景中有一个或几个人摆出普通姿势,场景中有一个人进行健身锻炼。所有这些图像都是由人类注释的。
Alignment and occlusions augmentation
在增强和训练数据准备期间,我们故意限制角度、比例和平移的支持范围。这允许我们降低网络容量,使网络更快,同时需要更少的计算资源,从而减少主机设备上的能源。
- 基于检测阶段或之前的帧关键点,我们对齐人,使髋部之间的点位于作为神经网络输入传递的方形图像的中心。我们将旋转估计为髋部中点和肩部中点之间的线L,并旋转图像,使L平行于y轴。对比例进行估计,以便所有身体点都适合在身体周围的方形边界框中。
- 我们还应用了10%的缩放和移位增强,以确保跟踪器处理帧间的身体运动和扭曲的对齐。
- 为了支持对不可见点的预测,我们在训练期间模拟遮挡(填充各种颜色的随机矩形),并引入逐点可见性分类器,以指示特定点是否被遮挡,以及位置预测是否被认为不准确。这使得即使是在严重遮挡的情况下,也可以持续跟踪一个人。
实验结果
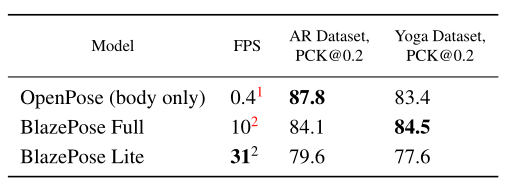
我们手动注释了两个包含1000张图像的内部数据集,每个图像中有1-2人。第一个数据集被称为AR数据集,由各种各样的野外人体姿势组成,而第二个数据集仅由瑜伽/健身姿势组成。为了保持一致性,我们只使用了MS Coco拓扑,17个点用于评估,这是OpenPose和BlazePose的共同子集。
作为评估指标,我们使用20%公差的正确点百分比 (PCK@0.2 )(如果2D欧几里德误差小于相应人躯干尺寸的20%,我们假设该点被正确检测到)。
为了验证人类基线,我们要求两名注释员独立地重新注释AR数据集,并获得手工注释平均值 PCK@0.2=97.2。
我们训练了两个不同能力的模型:BlazePose Full(6.9 MFlop,3.5 M参数) 和BlazePose Lite(2.7 MFlop,1.3 M参数)。
虽然我们的模型显示的性能比OpenPose模型稍差 AR数据集BlazePose Full在Yoga/健身用例上的表现优于OpenPose。同时,BlazePose在单个中端手机CPU上的性能比在20核桌面CPU上的OpenPose快25-75倍。
# Motion Adaptive Pose Net(2021 ICCV)
Motion Adaptive Pose Estimation From Compressed Videos
# 多人-Top down
# Detect-and-track(2018 CVPR)
Detectand-track: Efficient pose estimation in videos(2018 CVPR)
# PoseFlow (2018 BMVC)
Pose flow: Efficient online pose tracking
# POINet(2019 ACM MM)
POINet: pose-guided ovonic insight network for multi-person pose tracking
# KeyTrack(2020 CVPR)
15 keypoints is all you need
# PGPT(2020 TMM)
Poseguided tracking-by-detection: Robust multi-person pose tracking
# DetTrack(2020 CVPR)
Combining detection and tracking for human pose estimation in videos
# DCPose(2021 CVPR)
Deep Dual Consecutive Network for Human Pose Estimation
# 多人-Bottom up
# PoseTrack(2017 CVPR)
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
# Jointflow(2018 BMVC)
Jointflow: Temporal flow fields for multi person pose tracking
# Spatio-temporal associative embedding(2019 CVPR)
Multi-person articulated tracking with spatial and temporal embeddings
# 3D人体姿态估计
# 基于单目图像/视频
# 单视图单人
# Regression
# 2D-3D-Lifting
# Human Mesh Recovery (HMR)
# 单视图多人
# Top-down
# Bottom-up
# 多视图
# 基于深度信息(RGB+D)
# 基于其他源
# 数据集
# 2D HPE 数据集
# MPII
MPII是单人人体关键点检测的主要数据集。包含丰富的活动和多样性捕获环境,包括室内和室外。它是从YouTube的3913个视频中收集的,涉及491个不同的活动。从收集的视频中总共提取了24920帧。注释由亚马逊机械土耳其公司(AMT)的内部工作人员进行。
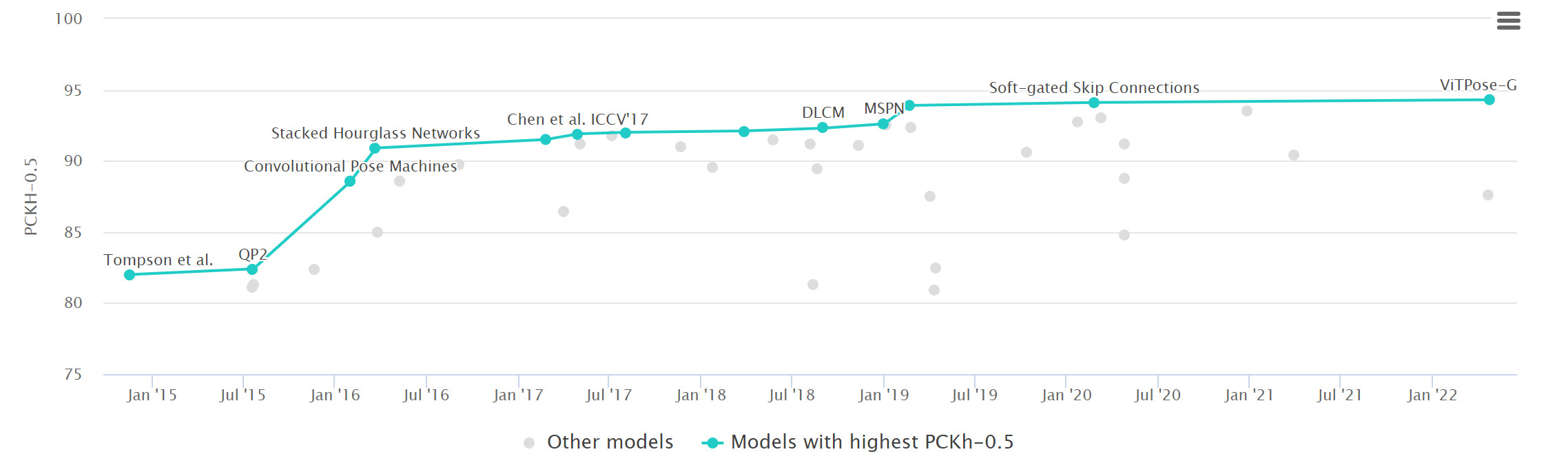
注释包括16个关键点的二维位置、完整的三维躯干和头部方向、关键点的遮挡标签以及活动标签。相邻的视频帧也可用于运动信息。最后,40522人被贴上标签,其中28821人用于培训,11701人用于测试。MPII数据集已被广泛用于姿态估计和其他与姿态相关的任务。由于姿态相对容易,检测到的2D关键点的精度较高,性能接近饱和。
现在(20220901)最优模型为ViTPose-G,PCKh-0.5为94.3。
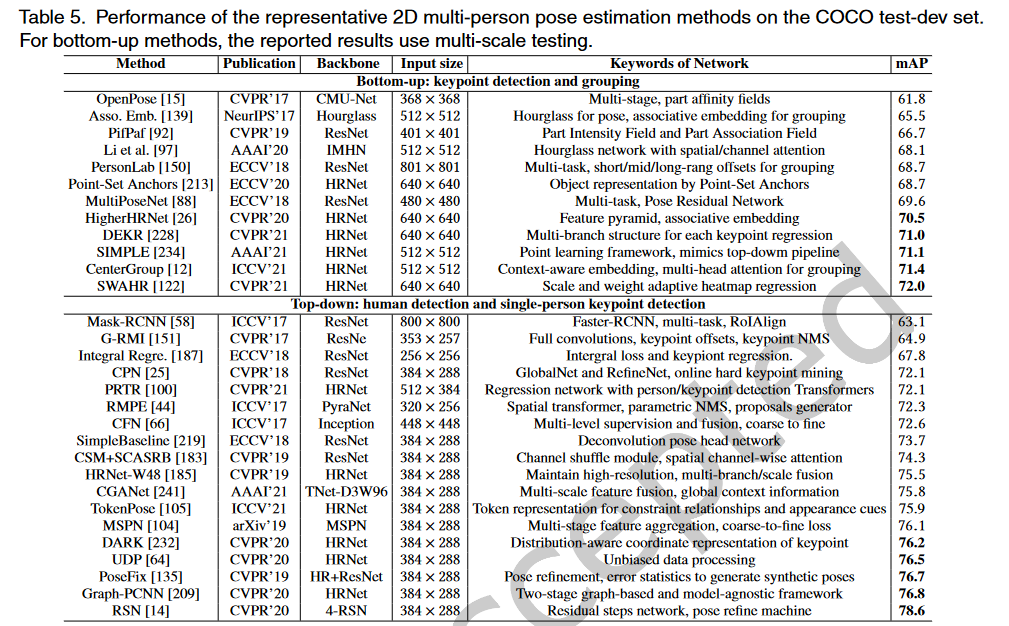
# COCO
COCO是多人关键点检测的主要数据集。包含用于对象检测、全景分割和关键点检测的注释。这些图片来自谷歌、必应和Flickr等网站。注释由亚马逊的Mechanical Turk(AMT)上的工人执行。该数据集包含超过20万张图像和25万个人实例。自2016年以来,除了数据集,COCO关键点检测的挑战每年都会举行。数据集有两个版本。区别在于训练集和验证集的划分。
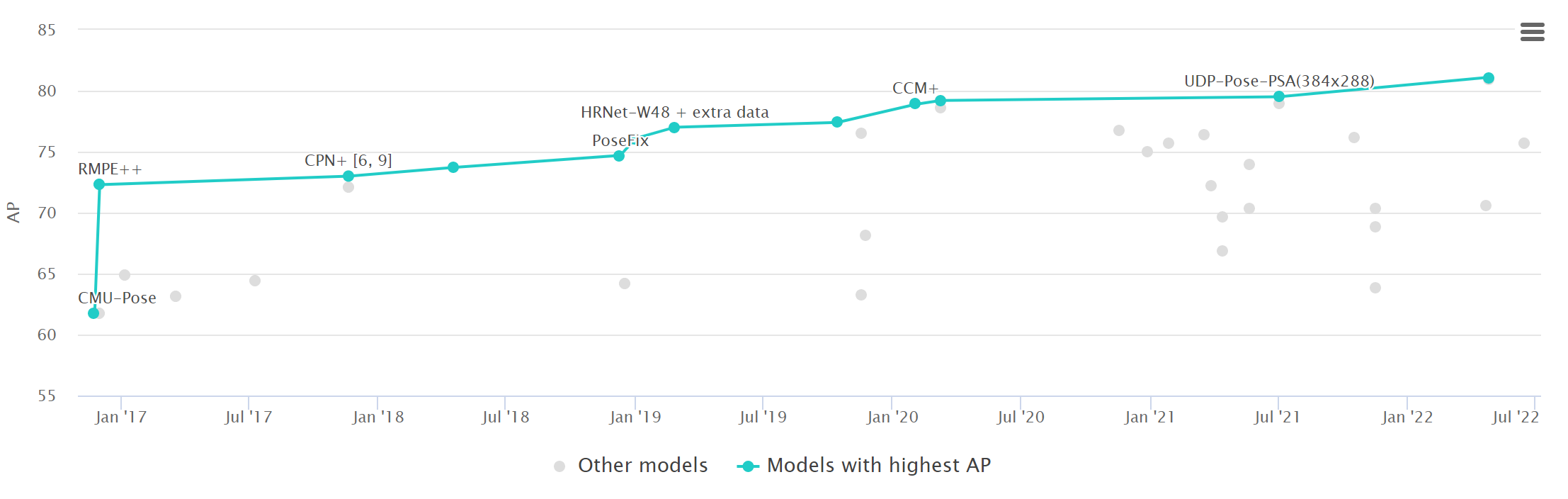
在2017年的最新版本中,training/val images拆分为118K/5K,而不是之前的83K/41K。测试集包含20K图像,注释由官方测试服务器提供。此外,还发布了120K未标记图像,它们与标记图像遵循相同的类别分布。它们可以用于半监督学习。对于关键点检测,将标记17个关键点以及可见性标记、边界框和身体分割区域。COCO数据集是一个广泛使用的评估基准,并作为姿态相关任务的辅助数据。
现在(20220901)最优模型为ViTPose(ViTAE-G, ensemble),mAP为81.1。
# J-HMDB
J-HMDB数据集是关节注释HMDB的缩写,是HMDB51数据库的子集,该数据库包含51个人类行为的5100多个片段。J-HMDB数据集包含928个剪辑,包含21个行为类别。每个行为类包含36-55个片段。每个剪辑包括15-40帧。31838张图片通过亚马逊 2D puppet model进行注释。最多可标记15个可见的身体关键点,以及比例、视点、分割、遮罩和流。训练和测试图像的数量比例大约为7:3。J-HMDB数据集已广泛应用于视频中的姿态估计和行为识别。
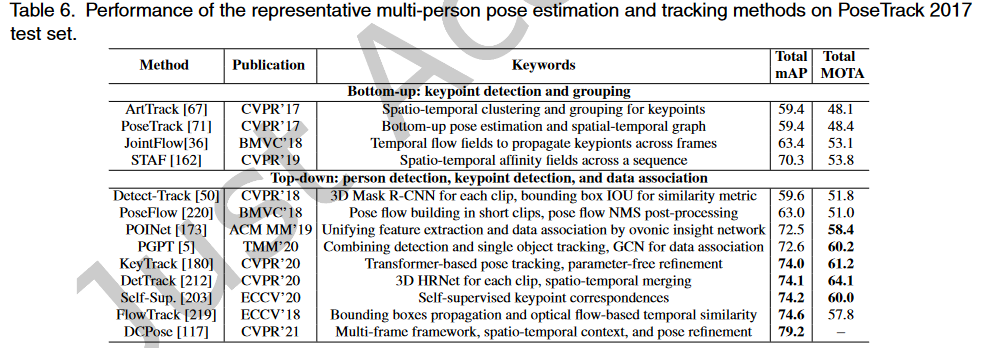
# PoseTrack
PoseTrack数据集是第一个大规模多人姿态估计和跟踪数据集。它是从MPII多人姿态数据集中的未标记视频中收集的。它有两个版本,即PoseTrack 2017和PoseTrack 2018。PoseTrack 2017包含550个视频,分为292、50和208个视频,分别用于训练、验证和测试。共有23000帧使用153615个姿态标签进行注释。PoseTrack 2018是其扩展版。它包含593个训练视频、170个验证视频和375个测试视频。对于训练集中的每个视频,中间的30帧都会被注释。对于验证集和测试集,中间的30帧以及每四帧被注释。标签包含15个二维关键点、一个唯一的个人ID和每个人的头部边界框。PoseTrack具有挑战性,因为视频包含各种姿态外观和比例变化,以及身体部位的遮挡和截断。
# 3D HPE 数据集

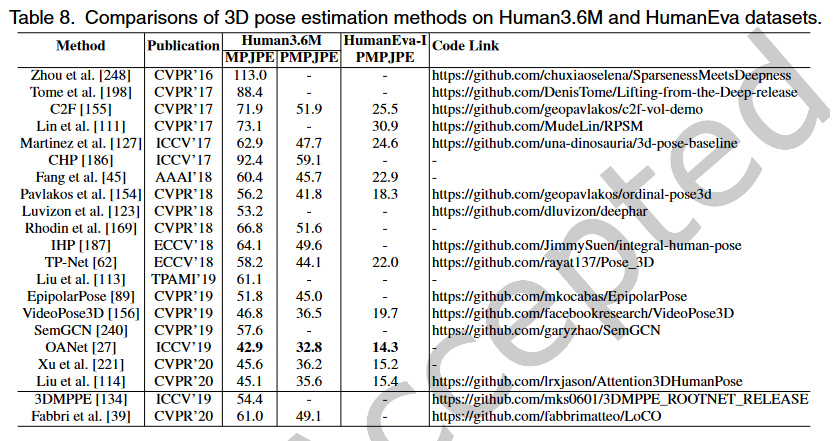
# Human3.6M
Human3.6M是最广泛使用的单人3D人体姿态基准。使用4台RGB摄像机、1台飞行时间传感器和10台运动摄像机在4m×3m的室内空间中捕获数据集。它包含360万个3D人体姿态和15种场景中的相应视频(50 FPS),如讨论、坐在椅子上、拍照等。视频分辨率为1000×1000像素。特别是,人体24个关键点的3D位置和角度都可用。最近,通过Mosh++,视频中人物的SMPL参数也可在[1]中找到。目前,由于隐私问题,只有7名受试者的数据可用。为了评估,视频通常按第5/64帧进行下采样,以消除冗余。方法通常根据两种常用方案进行评估,以进行比较。第一个方案是对5名受试者(S1、S5、S6、S7、S8)进行训练,并对受试者S9和S11进行测试。第二个方案共享相同的训练/测试集,但仅评估正面视图中捕获的图像。即增加了刚体变换的后处理操作,将预测骨骼与真实值先对齐再计算误差。
[1] Monocular, One-stage, Regression of Multiple 3D People(2021 ICCV)
# HumanEva
HumanEva是一个单人3D姿势数据集,包含两个子集,HumanEv-I和HumanEva-II。HumanEva-I在60Hz下从7个摄像机视图(4个灰度级和3个颜色)捕获。三个摄影机分别放置在场景的前部、左侧和右侧。它包含6.8K、6.8K和24K帧,分别用于训练、验证和测试。视频分辨率为659×494像素。它包含4个执行6个动作的受试者。方法通常由受试者S1、S2和S3执行的3个动作(步行、慢跑和拳击)进行评估。HumanEva II由4个摄像机从场景的4个角落拍摄,仅包含2个受试者执行组合的2460帧。
# MPI-INF-3DHP
MPI-INF-3DHP是在14摄像机工作室中使用商用无标记运动捕捉设备捕捉的,用于获取地面真实三维姿态。它包含8名演员(4名男性和4名女性),执行8项活动。从广泛的视点记录RGB视频。从所有14台摄像机捕获了超过130万帧,覆盖了广泛的视点。除了安装在胸部或更高位置的周围10个摄像机外,三个摄像机具有自顶向下的视图,最后一个摄像机位于膝盖高度,向上倾斜。除了一个人的室内视频外,他们还提供了MATLAB代码,通过混合分割的前景人像来生成多人数据集MuCo-3DHP。通过提供的身体部位分割,研究人员还可以使用额外的纹理数据交换衣服和背景。
# MoVi
MoVi是一个大规模的单人视频数据集,具有同步的3D身体姿态和网格注释。与Human3.6M和MPI-INF-3DHP不同,它包含更多受试者(60名女性和30名男性)。每个人执行20个预定义动作和一个自选动作。它还提供了这些受试者的详细特征,如年龄、身高、BMI和惯用手。与运动捕捉同步的视频从正面和侧面两个角度拍摄。为了捕捉精确的3D姿态,他们共同使用IMU设备和运动捕捉相机。除了3D姿态和相机参数外,MoVi还提供通过MoSh++获得的SMPL参数。
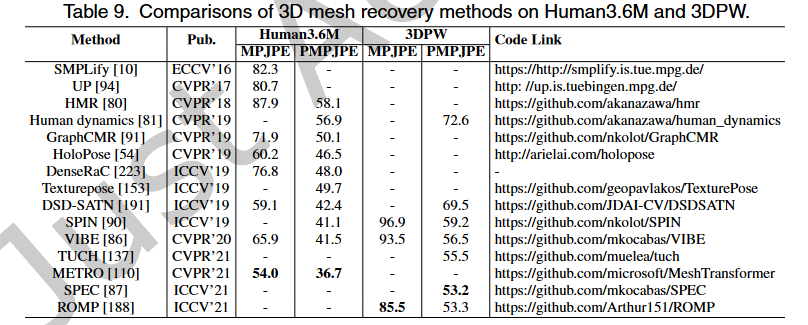
# 3DPW
3DPW是一个单视图、多人的野生3D人体姿势数据集,包含60个丰富活动的视频序列(24个训练、24个测试和12个验证),如攀岩、打高尔夫球和在海滩上放松。视频拍摄于各种场景,如森林、街道、操场和购物中心。尽管场景复杂,但它们利用IMU获得精确的3D姿态。3DPW包含丰富的3D注释,包括2D/3D姿势注释、3D身体扫描和SMPL参数。在一些拥挤的场景中(例如在街上),3DPW仅提供目标人物的标签,而忽略路过的行人。一开始,整个数据集用于评估,没有任何微调。最近,一些方法在测试集上进行了评估,有/没有进行微调。
# Benchmark🧿
在室内单人3D姿态基准、Human3.6M和HumanEva上,3D姿态估计方法在获得更好的3D姿态精度方面显示出明显的优势。3D网格恢复方法更适合于更全面的3D人体分析和可视化。此外,3DPW是一个新的野外多人3D姿态基准。三维网格恢复方法在其上显示了良好的泛化能力。
# 评价指标
# 2D HPE 评价标准
人体姿态估计-评价指标 - 知乎 (zhihu.com) (opens new window)
二维姿态估计的评估旨在测量预测的二维位置的准确性。根据数据集的特点,广泛使用的评估指标包括:
- 正确部位百分比 (PCP)
- 正确关键点百分比 (PCK)
- 平均精度 (AP),其中使用到 关键点相似度 (OKS)
# PCP
正确部分百分比(PCP)是2D HPE早期工作中常用的一种度量,用于评估棒预测,以报告肢体的定位精度。当预测关节和地面真实关节之间的距离小于肢体长度的一部分(在0.1到0.5之间)时,确定肢体的定位。在某些工作中,PCP测量也被称为PCP@0.5,其中阈值为0.5。此度量用于单人HPE评估。然而,PCP并没有在最新的研究中得到广泛应用,因为它会惩罚长度较短且难以检测的肢体。当模型具有较高的PCP度量时,其性能被认为更好。为了解决PCP的缺点,引入了检测关节百分比(PDJ),其中如果预测关节和真实关节之间的距离在躯干直径的某个分数内,则预测关节被视为检测到。
# PCK
正确关键点百分比(PCK)是衡量2D关键点预测准确性的一个广泛使用的指标。在17年比较广泛使用,现在基本不再使用。
计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例。
- FLIC数据集中是以躯干直径(左肩到右臂的欧式距离) 作为归一化参考
- MPII数据集中是以头部长度(头部直径) 作为归一化参考,即PCKh
例如
- PCK@0.2表示以躯干直径作为参考,如果归一化后的距离小于阈值0.2,则认为预测正确。
- PCKh@0.5表示以头部长度作为参考,如果归一化后的距离小于阈值0.5,则认为预测正确。
计算
其中$ i
id
i$ 的关键点
表示第 $\mathrm{k} $个阈值
表示第 $\mathrm{p} $个行人
表示第
为$ i$ 的关键点的预测值和groundtruth的欧式距离
表示第
$T_{k}
T_{k} \in[0: 0.01: 0.1]$
表示 T_{k} 阈值下
的关键点的PCK指标
$P C K_{\text {mean }}^{k} $表示
阈值下的算法PCK指标
code
def compute_pck_pckh(dt_kpts,gt_kpts,refer_kpts): """ pck指标计算 :param dt_kpts:算法检测输出的估计结果,shape=[n,h,w]=[行人数,2,关键点个数] :param gt_kpts: groundtruth人工标记结果,shape=[n,h,w] :param refer_kpts: 尺度因子,用于预测点与groundtruth的欧式距离的scale。 pck指标:躯干直径,左肩点-右臀点的欧式距离; pckh指标:头部长度,头部rect的对角线欧式距离; :return: 相关指标 """ dt=np.array(dt_kpts) gt=np.array(gt_kpts) assert(len(refer_kpts)==2) assert(dt.shape[0]==gt.shape[0]) ranges=np.arange(0.0,0.1,0.01) kpts_num=gt.shape[2] ped_num=gt.shape[0] #compute dist scale=np.sqrt(np.sum(np.square(gt[:,:,refer_kpts[0]]-gt[:,:,refer_kpts[1]]),1)) dist=np.sqrt(np.sum(np.square(dt-gt),1))/np.tile(scale,(gt.shape[2],1)).T #compute pck pck = np.zeros([ranges.shape[0], gt.shape[2]+1]) for idh,trh in enumerate(list(ranges)): for kpt_idx in range(kpts_num): pck[idh,kpt_idx] = 100*np.mean(dist[:,kpt_idx] <= trh) # compute average pck pck[idh,-1] = 100*np.mean(dist <= trh) return pck1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# OKS
OKS(object keypoint similarity),关键点相似度,在人体关键点评价任务中,对于网络得到的关键点好坏,并不是仅仅通过简单的欧氏距离来计算的,而是有一定的尺度加入,来计算两点之间的相似度。这个指标启发于目标检测中的IoU指标,主要是用在多人姿态估计任务当中。
说明
表示检测的关键点与真实关键点之间的欧氏距离;
表示groundtruth人的尺度因子,其值为行人检测框面积的平方根:
# 有些使用关键点xy最大值 area = (np.max(pred[:, 0]) - np.min(pred[:, 0])) * ( np.max(pred[:, 1]) - np.min(pred[:, 1]))1
2
3表示关键点可见性,参考COCO数据集,v=0表示关键点未标记,可能的原因是图片中不存在,或者不确定在哪;v=1表示关键点无遮挡并且已经标注,v=2表示关键点有遮挡但已标注;
表示符合条件为1
# AP
指标是作为COCO数据集的指标,既可以用在单人姿态估计,也可以用在多人姿态估计,他针对的是计算测试集精度百分比,这就是平均准确率(AP)。AP是通过测量对象关键点相似性(OKS)来计算的。
😆存疑:多人姿态计算只是recall?AP应该使用PR曲线面积来计算。p理解为多个样本好点?
单人姿态估计AP
计算出groundtruth与检测得到的关键点的相似度oks为一个标量,然后人为的给定一个阈值T,然后可以通过所有图片的oks计算AP:
多人姿态估计AP
多人姿态估计,如果采用的检测方法是自顶向下,先把所有的人找出来再检测关键点,那么其AP计算方法如同单人姿态估计AP。
如果采用的检测方法是自底向上,先把所有的关键点找出来然后再组成人,那么假设一张图片中共有M个人,预测出N个人,由于不知道预测出的N个人与groundtruth中的M个人的一一对应关系,因此需要计算groundtruth中每一个人与预测的N个人的oks,那么可以获得一个大小为M × N 的矩阵,矩阵的每一行为groundtruth中的一个人与预测结果的N个人的oks,然后找出每一行中oks最大的值作为当前GT的oks。最后每一个GT行人都有一个标量oks,然后人为的给定一个阈值T,然后可以通过所有图片中的所有行人计算AP:
说明
给定所有标记关键点的OKS,可以计算平均精度(AP)和平均召回率(AR)。通过调整OKS值,可以计算精度召回曲线。不同OKS下的AP和AR可以全面反映测试算法的性能。
(OKS=0.50时的AP)
(10个值的AP得分平均值,OKS=0.50:0.05:0.95)
- 中等对象的
,大对象的
# 3D HPE 评价标准
低MPJPE并不总是表示精确的姿态估计,因为它取决于人体形状和骨骼的预测比例。尽管3DPCK对不正确的关节更为鲁棒,但它无法评估正确关节的精度。现有度量被设计用于评估单个帧中估计姿态的精度。然而,现有的评估度量无法在连续帧上检查重建的人体姿态的时间一致性和平滑度。设计帧级评估指标,以评估具有时间一致性和平滑性的3D HPE性能,仍然是一个开放的问题
# MPJPE
MPJPE(Mean Per Joint Position Error)是评估3D HPE性能的最广泛使用的度量。MPJPE通过使用估计的3D关节和地面真实位置之间的欧几里得距离计算,不过一般关键点的表示形式为root-relative,即以其中一个关键点为根节点的坐标。然后通常是在相机坐标系下进行计算。这个指标越小则可认为这个3D人体姿态估计算法越好。
其中是关节点数,
与
分别是第i个真实关节和预测关节的位置
# PMPJPE
P-MPJPE(Procrustes analysis MPJPE)是基于Procrustes分析的MPJPE,先对输出进行刚性变换向groundtruth对齐后再计算MPJPE。
# 3DPCK
3DPCK是2D HPE评估中使用的正确关键点百分比(PCK)度量的3D扩展版本。如果估计值与地面真实值之间的距离在某个阈值内,则认为估计的关节是正确的。通常,阈值设置为150𝑚𝑚.
# AUC
曲线下面积AUC(越高越高)
# 深度估计
# 相关知识
# Group Convolution分组卷积
Group Convolution分组卷积,最早见于AlexNet——2012年Imagenet的冠军方法,Group Convolution被用来切分网络,主要是解决显存不足问题,使其在2个GPU上并行运行。
Group Convolution顾名思义,则是对输入feature map进行分组,然后每组分别卷积。假设输入feature map的尺寸仍为C∗H∗W,输出feature map的数量为N个,如果设定要分成G个groups,则每组的输入feature map数量为C/G,每组的输出feature map数量为N/G,每组卷积核的尺寸为N/G∗C/G∗K∗K,所有组卷积核的总参数量为N∗C/G∗K∗K,可见,总参数量减少为原来的 1/G。
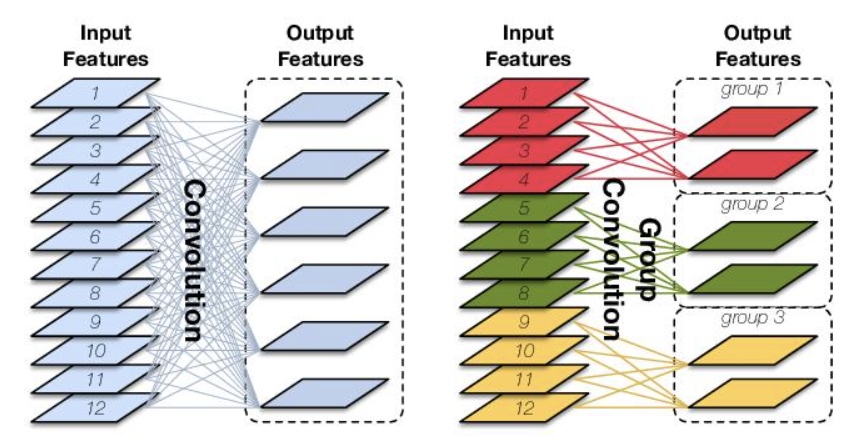
# Depth-wise Convolution
Depth-wise Convolution - 知乎 (zhihu.com) (opens new window)
Separable Convolution可以分成spatial separable convolution和depthwise separable convolution
depth-wise卷积的FLOPs更少没错,但是在相同的FLOPs条件下,depth-wise卷积需要的IO读取次数是普通卷积的100倍,因此,由于depth-wise卷积的小尺寸,相同的显存下,我们能放更大的batch来让GPU跑满,但是此时速度的瓶颈已经从计算变成了IO。自然desired小尺寸卷积应该有的快速的特性,也无法实现。
# 最新文献
# 2022年 works
# 2D HPE
DeciWatch: A Simple Baseline for 10x Efficient 2D and 3D Pose Estimation(2022 ECCV)
Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation(2022 CVPR)
Poseur: Direct Human Pose Regression with Transformers(2022 ECCV)
SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos(2022 ECCV)
PETR
End-to-End Multi-Person Pose Estimation with Transformers(2022 CVPR)
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation(2022 ECCV)
SimDR
- Is 2D Heatmap Representation Even Necessary for Human Pose Estimation?(2022 ECCV Oral)
# 3D HPE
MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation(2022 CVPR)
MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video(2022 CVPR)
Distribution-Aware Single-Stage Models for Multi-Person 3D Pose Estimation(2022 CVPR)
BEV: Putting People in their Place: Monocular Regression of 3D People in Depth(2022 CVPR)
SMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation(2022 ECCV)
DOPE: Distillation Of Part Experts for whole-body 3D pose estimation in the wild(2022 ECCV)
Faster VoxelPose: Real-time 3D Human Pose Estimation by Orthographic Projection(2022 ECCV)
Boosting Monocular 3D Human Pose Estimation With Part Aware Attention(2022 TIP)
Locally Connected Network for Monocular 3D Human Pose Estimation(2022 TPAMI)