 大型语言模型(LLM)
大型语言模型(LLM)
# 大型语言模型 (LLM)
# 基础知识
# 分类
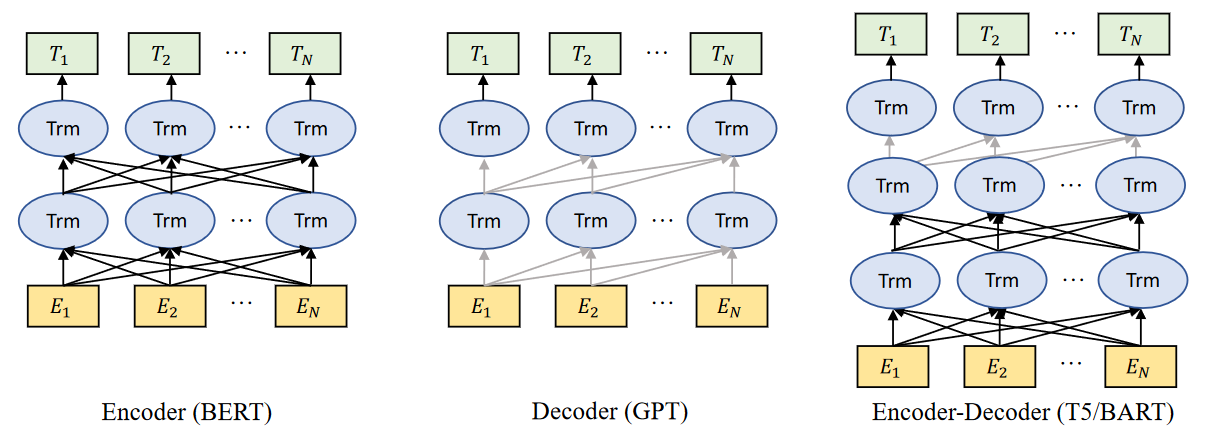
预训练的LLM的类别。黑线表示双向模型中的信息流,而灰线表示从左到右的信息流。
Encoder models,例如BERT,是用上下文感知目标进行训练的。
Decoder models,例如GPT,是用自回归目标训练的。
Encoder-decoder models,例如T5和BART,将两者结合起来,使用上下文感知结构作为编码器,使用从左到右结构作为解码器。
# Transformer
# 综述
# A Survey of Large Language Models(2023)
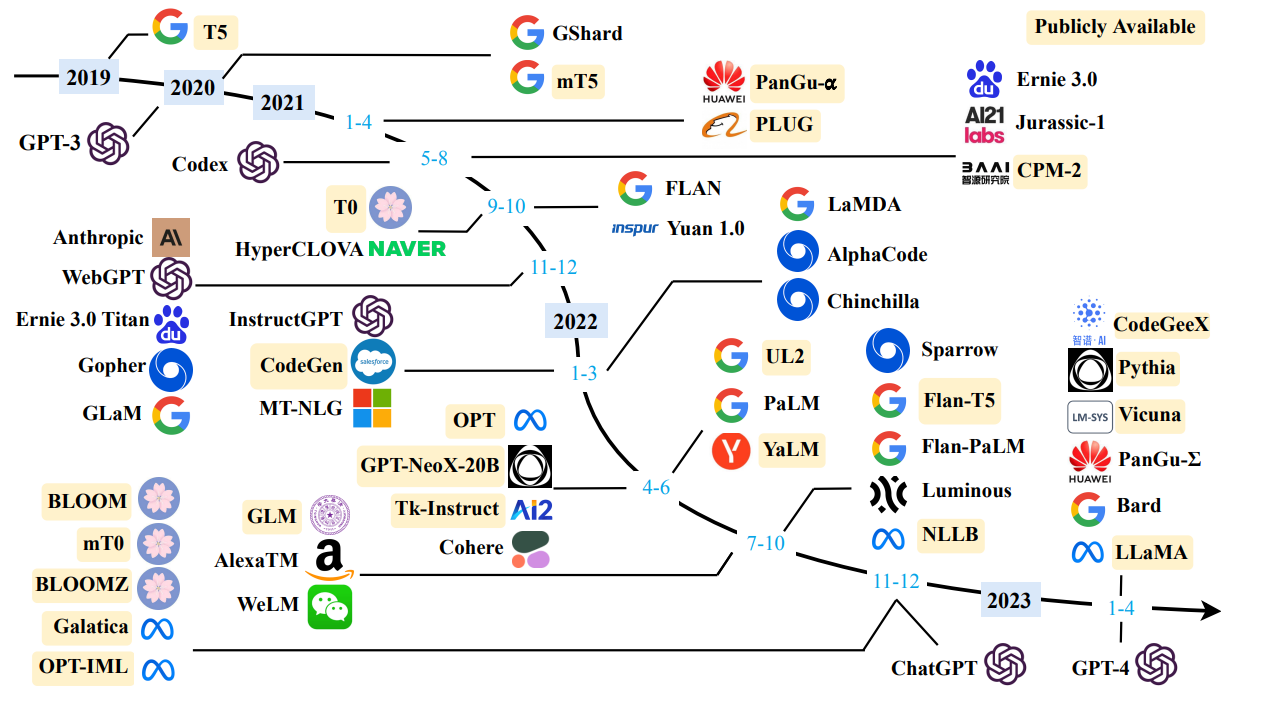
近年来现有的大型语言模型(大小大于10B)的时间表。时间表主要是根据模型技术文件的发布日期(例如提交给arXiv的日期)确定的。如果没有相应的论文,我们将模型的发布日期设置为其公开发布或公告的最早时间。我们用黄色的公开可用的模型检查点标记LLM。由于该图的篇幅限制,我们只包括公开报告评估结果的LLM。
# 相关工作
# GPT3(2020 NeurIPS)
Language Models are Few-Shot Learners
# PaLM(2022)
# LLaMa(2023)
Large Language Model Meta AI

# GPT4(2023)
# Scaling laws
Scaling laws for neural language models
Scaling Laws简单介绍就是:随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。并且为了获得最佳性能,所有三个因素必须同时放大。 当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系
# 量化微调架构
# Full Parameter Fine-tuning for Large Language Models with Limited Resources(2023)
# QLoRA(2023)
QLORA: Efficient Finetuning of Quantized LLMs
QLoRA:一种高效LLMs微调方法,48G内存可调65B 模型,调优模型Guanaco 堪比Chatgpt的99.3%! - 知乎 (zhihu.com) (opens new window)
# 输入长度限制问题
# MemTRM(2022)
Memorizing transformers
# LONGMEM(2023)
Augmenting Language Models with Long-Term Memory
作者:Microsoft
https://aka.ms/LongMem
出发点: 由于输入长度的限制,现有的大型语言模型(LLM)只能提供固定大小的输入,这使它们无法利用来自过去输入的丰富的长上下文信息。
为了解决这一问题,我们提出了一个框架,即长期记忆增强语言模型(LONGMEM),它使LLM能够记忆长期历史。我们设计了一种新的解耦网络架构,将原始骨干LLM冻结为内存编码器,将自适应残差侧网络作为内存检索器和读取器。这种解耦的存储器设计可以很容易地缓存和更新用于存储器检索的长期过去上下文,而不会受到存储器老化(memory staleness)的影响。
通过记忆增强适应训练的增强,LONGMEM可以记住过去很久的上下文,并将长期记忆用于语言建模。所提出的内存检索模块可以在其内存库中处理无限长度的上下文,以有利于各种下游任务。通常,LONGMEM可以将长形式存储器扩大到65k个令牌,从而缓存许多镜头额外演示示例作为用于上下文学习的长形式存储器。实验表明,我们的方法在ChapterBreak(一个具有挑战性的长上下文建模基准) 上优于强长上下文模型,并在LLM的上下文学习中实现了显著的内存增强改进。结果表明,该方法在帮助语言模型记忆和利用长格式内容方面是有效的。
# 介绍
大型语言模型(LLM)已经彻底改变了自然语言处理,在各种理解和生成任务方面取得了巨大成功。大多数LLM从大型语料库的自我监督培训中受益匪浅,他们从固定规模的局部上下文中获取知识,显示出应急能力,例如零样本提示、上下文学习和思维链(CoT)推理。然而,现有LLM的输入长度限制使它们无法推广到真实世界的场景中,在这些场景中,处理固定大小会话之外的长格式信息的能力至关重要,例如,长水平规划。为了解决长度限制问题:
最简单的方法是简单地放大输入上下文的长度。例如,GPT-3将输入长度从GPT-2的1k增加到2k个令牌,以捕获更好的长程依赖关系。然而,这种方法通常会从头开始进行计算密集型训练,并且上下文中的密集注意力仍然受到Transformer自注意力的二次计算复杂性的严重限制。
最近的另一项工作转而专注于在上下文中开发稀疏注意力,以避免自我注意力的二次成本,这在很大程度上仍然需要从头开始训练。
记忆变换器(MemTRM),通过对上下文内tokens和从Transformrer的不可微分存储器中检索的memorized tokens的密集关注,近似了上下文内稀疏关注。因此,MemTRM将生成的语言模型放大,以处理多达65k个令牌,并在建模长篇书籍或长篇论文时获得了显著的困惑增益。然而,MemTRM在训练过程中面临着记忆老化的挑战,因为它的耦合记忆设计使用单一的模型来编码记忆,并使用融合记忆来进行语言建模。换言之,随着模型参数的更新,存储器中缓存的较旧表示可能与最新模型中的表示相比具有分布变化,从而限制了存储器扩充的有效性。
# 架构
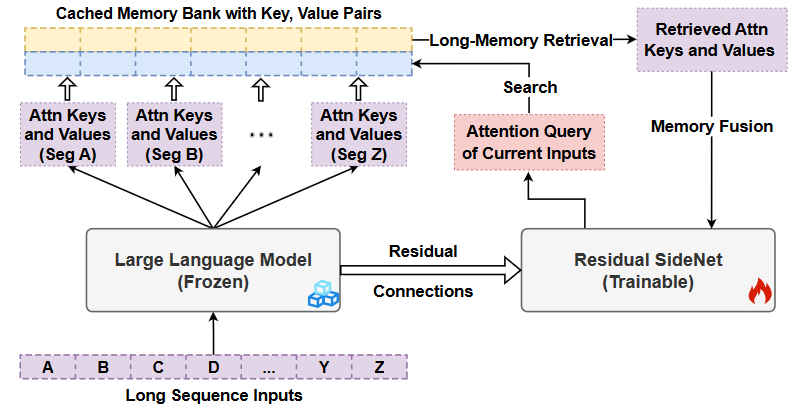
简单步骤: 将长文本序列拆分为固定长度的片段,然后通过大型语言模型转发每个片段,并将第m层的注意力关键字和值向量缓存到长期内存库中。对于未来的输入,通过基于注意力查询关键字的检索,检索长期记忆的前k个注意力key-value对,并将其融合到语言建模中。
为了实现存储器的解耦,我们设计了一种新的残差侧网络(SideNet)。使用冻结的主干LLM将先前上下文的成对关注密钥和值提取到存储器组中。在SideNet的内存增强层中,如上所述,生成的当前输入的注意力查询用于从内存中检索先前上下文的缓存(键、值),然后通过联合注意力机制将相应的内存增强融合为学习到的隐藏状态。此外,SideNet和冻结骨干LLM之间新设计的跨网络残差连接能够更好地从预训练的骨干LLM传递知识。
去耦内存设计带来了两个主要好处:
首先,我们提出的体系结构通过解耦的冻结骨干LLM和SideNet将先前输入编码到内存的过程与内存检索和融合的过程解耦。这样,主干LLM只充当长上下文知识编码器,而残差SideNet充当内存检索器和读取器,有效地解决了内存过时的问题。
其次,用内存增强直接调整整个LLM在计算上效率低下,而且还会遭受灾难性的遗忘。由于骨干LLM在有效的记忆增强适应阶段被冻结,LONGMEM不仅可以利用预先训练的知识,还可以避免灾难性的遗忘。
下面详细介绍
为了使LLM能够从内存中过去的长上下文中获取相关信息,我们建议使用解耦的内存模块来增强冻结的主干LLM。为了融合记忆上下文信息,我们设计了一种新的轻量级残差SideNet,它可以以有效的方式进行连续训练。下面分成三部分展开:
先讨论具有记忆增强的语言模型;
然后介绍残差SideNet(用于调整冻结的预训练LLM,以联合处理当前输入上下文和检索的内存上下文);
最后介绍整个设计的过程(如何对过去的记忆进行编码、存储、回忆和融合,以进行语言建模)
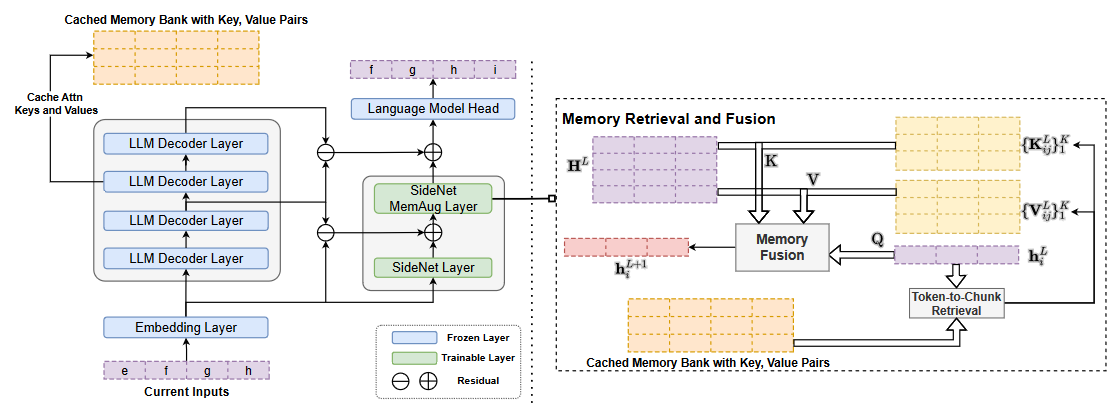
鉴于Transformer在预训练LLM中的广泛采用,LONGMEM模型建立在Transformer架构上。有三个关键组件:冻结主干LLM、SideNet和缓存内存库。
# Language Models Augmented with Long-Term Memory
# Residual SideNet
# Memory Retrieval and Fusion
# 实验
# 代码生成
# WizardCoder(2023)
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
# MoE: 专家混合系统
Moe,是Mixture-Of-Experts的缩写,可以在保证运算速度的情况下,将模型的容量提升>1000倍。
# 大模型开源库
# h2oGPT
h2oGPT: Democratizing Large Language Models