 大模型应用开发及落地
大模型应用开发及落地
# 大模型应用开发及落地
# 介绍
几分钟开发 AI 应用成为可能,为什么说大模型中间件是 AI 必备软件? (qq.com) (opens new window)
大模型是指基于大型语言模型的人工智能应用。它能够与用户进行流畅的对话,并提供即时且针对性的回应。大模型带来了前所未有的高度个性化体验,例如,借助基于大型语言模型的AI写作助手,用户能够快速生成高质量的文章草稿,其风格与用户贴合,极大提高了内容创作效率。但是,大模型要在企业侧真正落地仍然面临很大挑战,总结为下面四个方面:
大模型专业深度不够,数据更新不及时,缺乏与真实世界的连接;
大模型有Token的限制,记忆能力有限;
用户对于数据安全的担忧;
使用大模型的成本问题。
# 解决方案
第一是将大模型部署到企业本地,结合企业私有数据进行训练,打造垂直领域专有模型。
第二是在大模型基础上进行参数微调,改变部分参数,让其能够掌握深度的企业知识。
第三种是围绕向量数据库打造企业的知识库,基于大模型和企业知识库再配合Prompt打造企业专属AI应用。
# LLM+知识库
从实用性和经济性的角度考虑,第三种是最为有效的解决方案。该方案大致实现方式如下所示
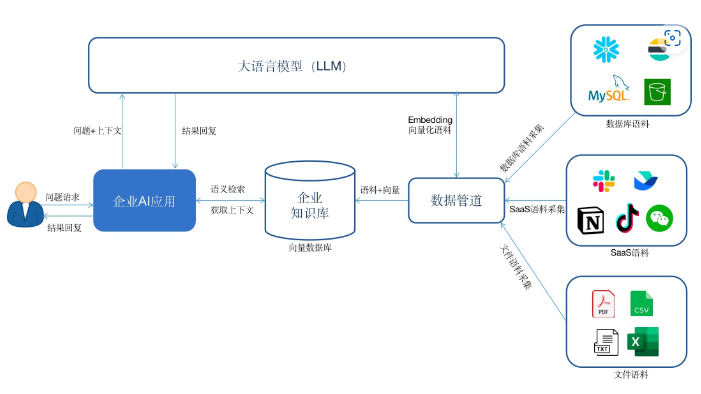
企业首先基于私有数据构建一个知识库。
通过数据管道将来自数据库、SaaS软件或者云服务中的数据实时同步到向量数据库中,形成自己的知识库。在这个过程中需要调用大模型的Embedding接口,将语料进行向量化,然后存储到向量数据库。
当用户与企业AI应用对话时,AI应用首先会将用户的问题在企业知识库中做语义检索;
然后将检索的相关答案和问题以及配合一定的prompt一并发给大模型,获得最终的答案。
# 大模型中间件
大模型中间件主要解决向量数据库的问题,包括:
知识库的构建
AI应用的集成
数据安全性的问题
大模型中间件是位于AI应用与大模型之间的中间层基础软件,它主要解决大模型落地过程中数据集成、应用集成、知识库与大模型融合等问题。
下图给出了企业AI应用的典型软件架构,一共分为大语言模型、向量数据库、大模型中间件以及AI应用四层。
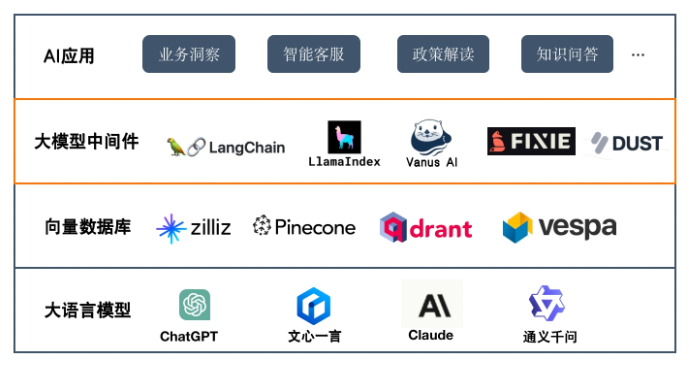
大语言模型为AI应用提供基础的语义理解、推理、计算能力;
向量数据库主要提供企业知识的存储和语义搜索。
大模型中间件解决大模型落地的最后一公里,提供语料的实时采集、数据清洗、过滤、embedding (知识库构建)。同时,为上层应用提供访问大模型与知识库的入口,提供大模型与知识库的融合、应用部署、应用执行 (下层访问封装)。
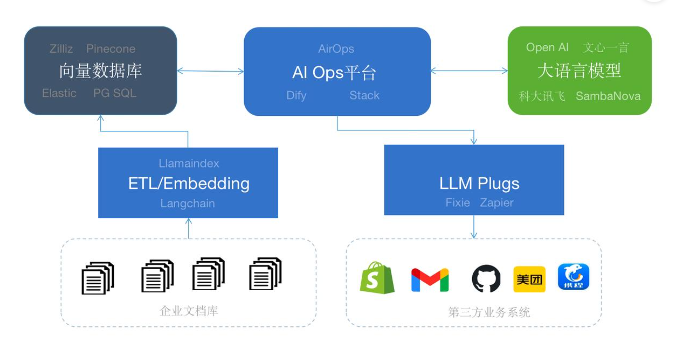
AI Stack:中间件作为连接
AI Ops平台可以连接大模型和企业知识库帮助用户一站式构建AI的应用。
如果AI应用需要连接第三方的应用执行操作可以通过Fixie或者Zapier等提供了插件。
# LangChain
“一个强大的框架,旨在帮助开发人员使用大型语言模型、并与其他计算或知识来源相结合,构建端到端的应用程序。”
hwchase17/langchain: ⚡ Building applications with LLMs through composability ⚡ (github.com) (opens new window)liaokongVFX/LangChain-Chinese-Getting-Started-Guide: LangChain 的中文入门教程 (github.com) (opens new window) LangChain 完整指南:使用大语言模型构建强大的应用程序 - 知乎 (zhihu.com) (opens new window)
# OpenAI 函数调用功能
OpenAI 重磅更新,API 添加新函数调用能力,能处理更长上下文,价格又降了 75%,有哪些影响? - 知乎 (zhihu.com) (opens new window)
# LangFlow
https://mp.weixin.qq.com/s/omHZ_IqjISphmdGz3tiMnQ
一款可轻松实验和原型化 LangChain流水线的AI项目
# 相关工作
# 检索增强生成 (RAG)
检索增强生成 (RAG) | Prompt Engineering Guide (promptingguide.ai) (opens new window)
通用语言模型通过微调就可以完成几类常见任务,比如分析情绪和识别命名实体。这些任务不需要额外的背景知识就可以完成。
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)(opens in a new tab) (opens new window)的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
RAG 在 Natural Questions(opens in a new tab) (opens new window)、WebQuestions(opens in a new tab) (opens new window) 和 CuratedTrec 等基准测试中表现抢眼。用 MS-MARCO 和 Jeopardy 问题进行测试时,RAG 生成的答案更符合事实、更具体、更多样。FEVER 事实验证使用 RAG 后也得到了更好的结果。
这说明 RAG 是一种可行的方案,能在知识密集型任务中增强语言模型的输出。
最近,基于检索器的方法越来越流行,经常与 ChatGPT 等流行 LLM 结合使用来提高其能力和事实一致性。
LangChain 文档中可以找到一个使用检索器和 LLM 回答问题并给出知识来源的简单例子(opens in a new tab) (opens new window)。