 大模型用于数据分析
大模型用于数据分析
# 大模型用于数据分析
“Is LLM a Good Data Analyst? ” “Of course.”
# 基本概念
# 数据分析定义/职责
数据分析师的主要工作范围包括利用业务数据从数据中识别有意义的模式和趋势,并为利益相关者提供做出战略决策的宝贵见解。为了实现他们的目标,他们必须具备各种技能,包括SQL查询编写、数据清理和转换、可视化生成和数据分析。
基于上述三项主要技能,数据分析师的主要工作范围可以分为三个步骤:数据收集、数据可视化和数据分析。
根据业务合作伙伴的要求从多个数据库中提取相关数据:最初的步骤包括理解业务需求,并决定哪些数据源与回答它相关。一旦确定了相关的数据表,分析师就可以通过SQL查询或其他提取工具提取所需的数据。
以易于理解的方式呈现数据可视化:创建视觉辅助工具,如图形和图表,有效地传达见解。
以要点的形式展示提供数据的分析和见解:在数据分析阶段,分析师可能需要确定不同数据点之间的相关性,识别异常和异常值,并跟踪一段时间内的趋势。从这一过程中得出的见解可以通过书面报告或演示传达给利益相关者。
# 数据集上Task Setting
根据数据分析师的主要工作范围,我们在下面描述我们的任务设置。
形式上,给定一个与业务相关的问题(q)和一个或多个相关的数据库表(d)及其模式(s),我们的目标是提取所需的数据(D),生成用于可视化的图(G),并提供一些分析和见解(A)。
更具体地说,根据给定的问题,必须识别数据库中包含图表所需数据的相关表和方案,然后从数据库中提取数据,并以适合图表生成的方式对其进行组织。一个示例问题可以是:“在散点图中显示身高和体重之间的相关性”。可以看出,问题还包括图表类型信息,因此还必须根据数据的性质和所问问题选择合适的图表类型,并使用合适的软件或编程语言生成图表。最后,需要分析数据,以确定有助于回答最初问题的趋势、模式和见解。
# 相关工作
# Is GPT-4 a Good Data Analyst?(2023)
作者:alibaba-inc GitHub - DAMO-NLP-SG/GPT4-as-DataAnalyst (opens new window)
随着大型语言模型(LLM)在许多领域和任务中展示了其强大的能力,包括上下文理解、代码生成、语言生成、数据讲述等,许多数据分析师可能会担心他们的工作是否会被人工智能(AI)取代。这个有争议的话题引起了公众的极大关注。然而,我们仍然处于意见分歧的阶段,没有任何明确的结论。受此启发,我们在这项工作中提出了“GPT-4是一个好的数据分析师吗?”的研究问题,并旨在通过进行面对面的比较研究来回答这个问题。详细地说,我们将GPT-4视为一个数据分析师,用来自广泛领域的数据库执行端到端的数据分析。我们提出了一个框架,通过仔细设计GPT-4进行实验的提示来解决这些问题。
我们还设计了几个特定任务的评估指标,以系统地比较几个专业人类数据分析师和GPT-4之间的性能。实验结果表明,GPT-4可以达到与人类相当的性能。在我们得出GPT-4可以取代数据分析师的结论之前,我们还对我们的结果进行了深入的讨论,以阐明进一步的研究。
# 贡献
我们首次提出了GPT-4是否是一个好的数据分析师的研究问题,并对其利弊进行了定量评估。
对于这样一个典型的数据分析师工作范围,我们提出了一个端到端的自动框架来进行数据收集、可视化和分析。
我们对GPT-4的输出进行系统和专业的人类评估。高质量的数据分析和见解可以被认为是NLP社区数据分析的第一个基准。
# 架构
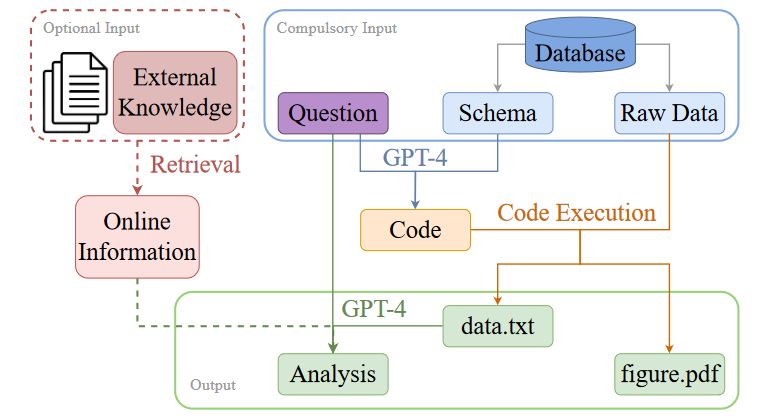
目标是使用GPT-4来自动化整个数据分析过程,步骤如下图所示。基本上,涉及三个步骤:(1)代码生成(如蓝色箭头所示)、(2)代码执行(如橙色箭头所示,)和(3)分析生成(如绿色箭头所示。
将GPT-4作为数据分析师的框架的流程:包含业务问题和数据库的强制输入信息显示在右上角的蓝色框中。参考外部知识源的可选输入在左上角的红色虚线框中圈出。输出包括提取的数据(即“data.txt”)、数据可视化(即“figure.pdf”)和分析,在底部的绿色框中圈出。
伪代码:

# 第1步:代码生成
利用GPT-4从模式中理解问题以及多个数据库表之间的关系。请注意,由于数据安全原因,此处仅提供数据库表的模式。大量的原始数据仍然在离线时保持安全,这些数据将在稍后的步骤中使用。该步骤的设计提示(prompt) 如下所示:
代码生成。蓝色文本:具体问题、数据库文件名和数据库模式。
Question: [question]
conn = sqlite3.connect([database file name])
[database schema]
Write python code to select relevant data and draw the chart. Please save the plot to "figure.pdf" and save the label and value shown in the graph to "data.txt".
# 第2步:代码执行
如前一步所述,为了维护数据安全,我们离线执行GPT-4生成的代码。
该步骤中的输入是从步骤1生成的代码和数据库中的原始数据。通过执行python代码,我们可以获得“figure.pdf”中的图表和保存在“data.txt”中的提取数据。
# 第3步:分析生成
在我们获得提取的数据后,我们的目标是生成数据分析和见解。为了确保数据分析与原始查询一致,我们使用问题和提取的数据作为输入。为该步骤的GPT-4设计的提示如下所示。
Question: [question]
[extracted data]
Generate analysis and insights about the data in 5 bullet points.
我们没有生成一段关于提取数据的描述,而是指示GPT-4生成5个要点中的分析和见解,以强调关键要点。请注意,我们也考虑了使用生成的图表作为输入的替代方案,因为GPT-4技术报告提到它可以将图像作为输入。然而,这一功能仍然没有向公众开放。由于提取的数据基本上包含与生成的图形相同的信息量,因此目前仅使用此处提取的数据作为输入。从我们的初步实验来看,GPT-4能够在没有看到图像的情况下从数据本身了解趋势和相关性。
为了使我们的框架更加实用,从而有可能帮助人类数据分析师提高他们的日常表现,我们添加了一个利用外部知识源的选项。由于实际的数据分析师角色通常需要相关的业务背景知识,我们设计了一个外部知识检索模型g(·)来查询来自外部知识源(如谷歌)的实时在线信息(I)。在这样的选项中,GPT-4将数据(D)和在线信息(I)作为输入来生成分析(A)。
# 实验
在NvBench数据集的基础上对每个实例增加5个要点的数据见解作为评估数据集
使用自定义指标分别评估图像和分析(参考下文),通过人为评估
# GPT-4 Performance
下表显示了GPT-4作为数据分析师对200个样本的性能。我们展示了每个评估者小组的结果以及这两个小组之间的平均得分。对于图表类型的正确性评估,两个评估组都给出了几乎满分。这表明,对于“绘制条形图”、“显示饼图”等简单明了的指令,GPT-4可以很容易地理解其含义,并对图表类型的含义有背景知识,因此可以相应地以正确的类型绘制图表。在美学评分方面,它平均可以得到2.73分(满分3分),这表明生成的大多数数字对观众来说都是清晰的,没有任何格式错误。然而,对于绘制的图表的信息正确性,分数并不那么令人满意。我们手动检查这些图表,发现尽管有一些小错误,但大多数图表都能大致得到正确的数字。我们的评估标准非常严格,只要x轴或y轴的任何数据或标签都是错误的,就必须扣除分数。尽管如此,它还有进一步改进的空间。

在分析评估中,对齐度和流利度平均都得满分。它再次验证了生成流畅且语法正确的句子对GPT-4来说绝对不是问题。我们注意到,分析的平均正确性得分远高于数字的信息正确性得分。这很有趣,因为尽管生成了错误的数字,但分析可能是正确的。 它再次验证了我们之前对数字图像信息正确性分数的解释。如前所述,由于生成的图形大多与黄金图形一致,因此可以正确生成一些要点。只有少数与图中错误部分相关的要点被认为是错误的。就复杂度得分而言,平均2.16分(满分3分)是合理且令人满意的。
# Comparison between Human Data Analysts and GPT-4
为了进一步回答我们的研究问题,我们聘请了专业的数据分析师来完成这些任务,并与GPT-4进行了全面的比较。我们完全补偿他们的注释。表显示了来自不同背景的不同专家级别的几位数据分析师与GPT-4相比的表现。总的来说,GPT-4的性能与人类数据分析师相当,而不同的指标和人类数据分析师的优势各不相同。
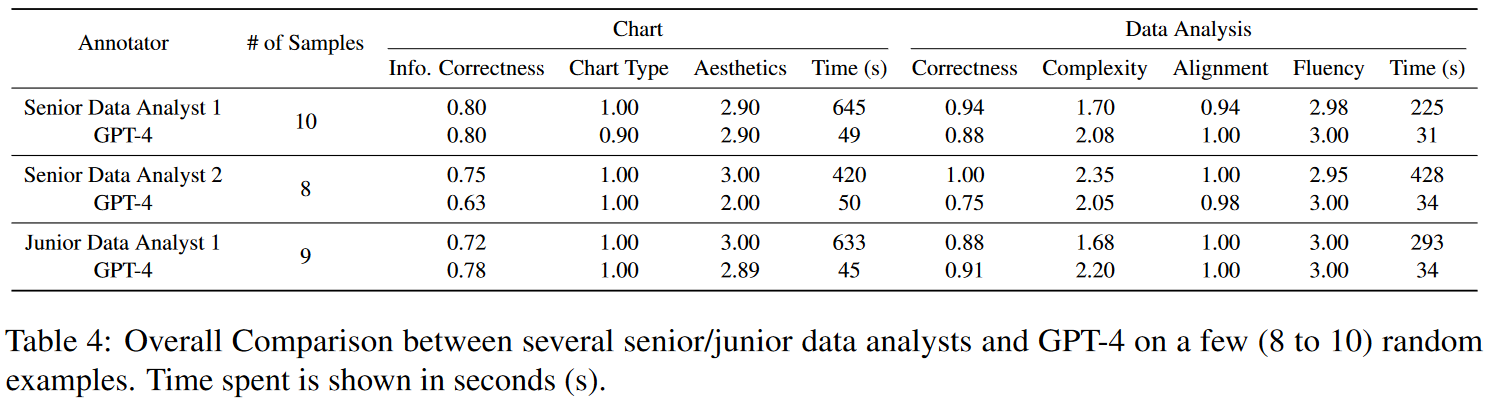
第一块显示了一位在金融行业拥有6年以上数据分析工作经验的高级数据分析师(即高级数据分析师1)的10个样本表现。从表中可以看出,GPT-4的性能在大多数指标上都与专家数据分析师相当。尽管GPT-4的正确性得分低于人类数据分析师,但复杂性得分和比对得分更高。
第二块显示了GPT-4与另一位在互联网行业担任数据分析师超过5年的高级数据分析师(即高级数据分析师2)之间的另一个8样本性能比较。由于样本量相对较小,结果显示人类和人工智能数据分析师之间的差异较大。这位人类数据分析师在数据的信息正确性和美观性、见解的正确性和复杂性方面超过了GPT-4,这表明GPT-4仍有改进的潜力。
第三块比较了GPT-4和一位在咨询公司有两年数据分析工作经验的初级数据分析师之间的另一个随机9样本性能。GPT-4不仅在数字和分析的正确性方面表现更好,而且往往比人类数据分析师产生更复杂的分析。
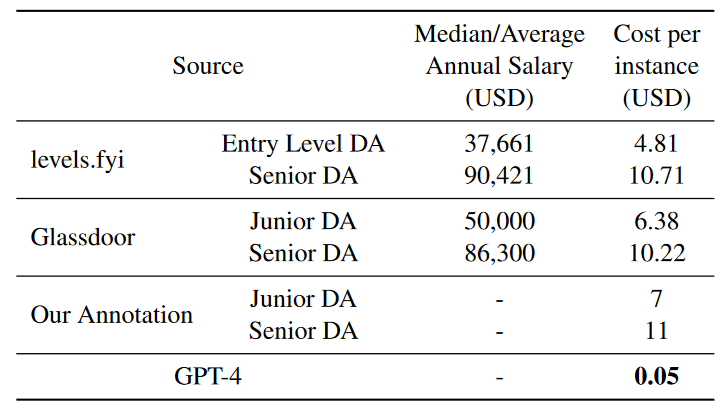
除了所有数据分析师和GPT-4之间的可比性能外,我们可以注意到GPT-4花费的时间比人类数据分析师短得多。下表显示了不同来源的成本比较。我们从level.fly获得新加坡数据分析师的平均年薪,从Glassdoor获得新加坡数据分析员的平均年薪(令人羡慕的待遇,AI都得眼红)。我们假设每月约有21个工作日,每天的工作时间约为8小时,并根据每个级别的数据分析师花费的平均时间计算每个实例的成本(美元)。对于我们的注释,我们根据市场利率向数据分析师支付相应的费用。GPT4的成本约为初级数据分析师成本的0.71%,为高级数据分析师的0.45%。
# 个案分析研究(Case study)
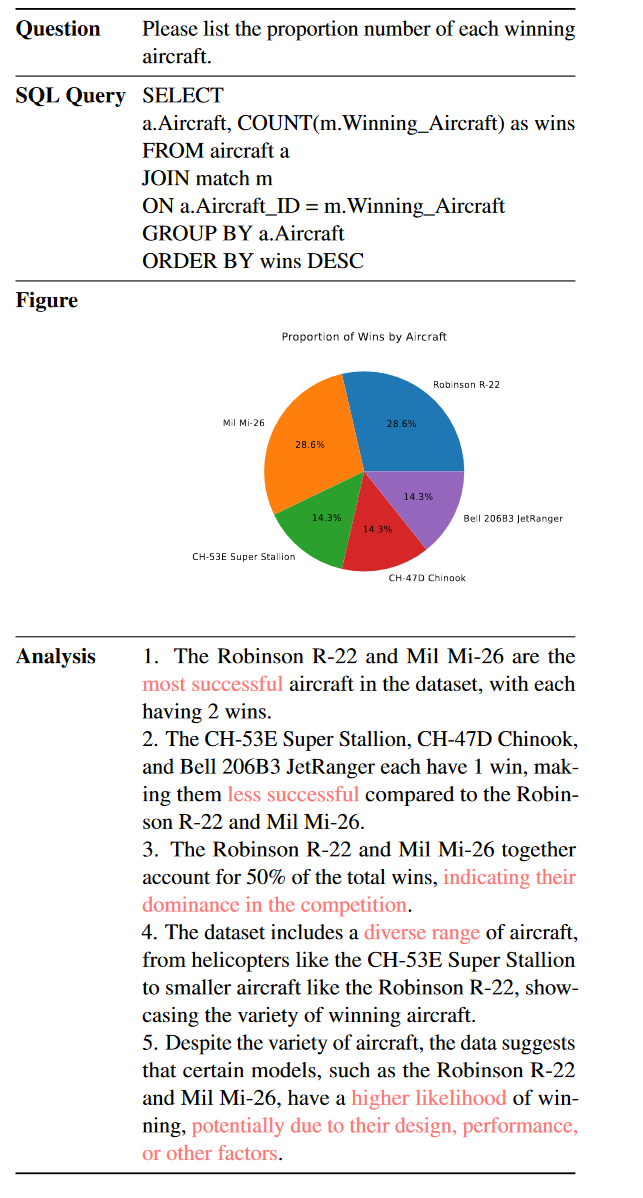
在下表所示的第一种情况下,GPT-4能够生成包含正确SQL查询的python代码,以提取所需的数据,并根据给定的问题绘制正确的饼图。就分析而言,GPT-4能够通过进行适当的比较(例如,“最成功的”、“不太成功的”和“多样的范围”)来理解数据。此外,GPT-4可以从数据中提供一些见解,例如:“表明他们在竞争中的主导地位”。GPT-4的上述能力,包括上下文理解、代码生成和数据讲述,也在许多其他情况下得到了证明。此外,在这种情况下,GPT-4还可以根据数据及其背景知识做出一些合理的猜测,例如:“可能是由于它们的设计、性能或其他因素”。
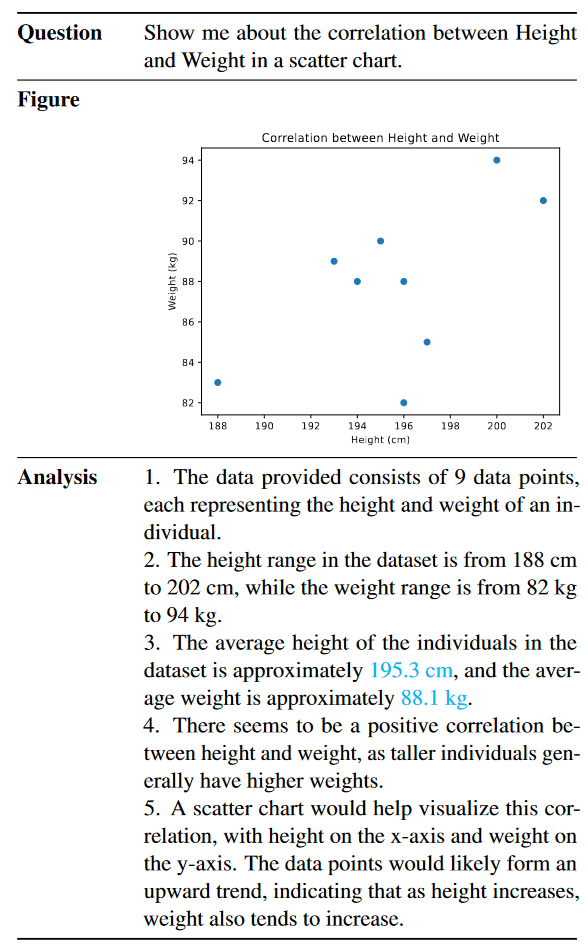
第二种情况显示了GPT-4解决的另一个问题。同样,GPT-4能够提取正确的数据,绘制正确的散点图并生成合理的分析。尽管大多数要点都是忠实生成的,但如果我们仔细阅读和检查,我们可以注意到平均身高和体重的数字是错误的。除了众所周知的幻觉问题外,我们怀疑GPT-4的计算能力并不强,尤其是对于那些复杂的计算。我们在其他几个案例中也注意到了这一问题。尽管GPT-4以非常自信的语气生成分析要点,但计算有时不准确。
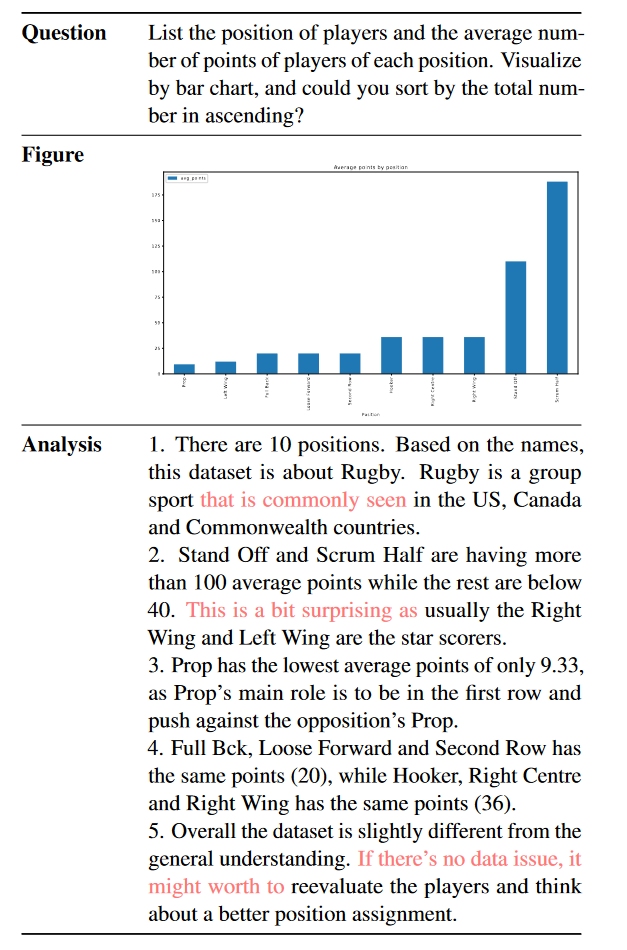
下表显示了高级分析员2所做的一个例子。我们可以注意到,这位专业的人力数据分析师还可以理解需求,编写代码来绘制正确的条形图,并以要点形式分析提取的数据。除此之外,我们可以总结GPT-4的三个主要差异:
首先,与GPT-4不同,人类数据分析师可以用一些个人的想法和情绪来表达分析。例如,数据分析师提到“这有点令人惊讶……”。在现实生活中,个人情绪有时很重要。通过这些情绪化的短语,观众可以很容易地理解数据是如预期的还是异常的。
其次,人力数据分析师倾向于应用一些背景知识。虽然GPT-4通常只关注提取的数据本身,但人类很容易与背景知识联系在一起。例如,数据分析师提到“…是常见的…”,这在数据分析师的实际工作中更为自然。因此,为了更好地模拟人类数据分析师,在我们的演示中,我们添加了一个选项,在生成数据分析时使用谷歌搜索API提取实时在线信息。
第三,当提供见解或建议时,人类数据分析师往往是保守的。例如,在第5个要点中,人力数据分析师在给出建议之前提到“如果没有数据问题”。与人类不同,GPT-4将以自信的语气直接提供建议,而不提及其假设。
# 调查结果和讨论
在我们的实验中,我们注意到了一些现象,并对它们进行了一些思考。在本节中,我们将讨论我们的发现,并希望研究人员能够在未来的工作中解决其中的一些问题。一般来说,GPT-4的表现可以与我们初步实验中的数据分析师相媲美,而在我们得出GPT-4是一个好的数据分析师的结论之前,仍有几个问题需要解决:
首先,如案例研究部分所示,GPT-4仍然存在幻觉问题(hallucination problems),这也在GPT-4技术报告中提到。数据分析工作不仅需要这些技术技能和分析技能,还需要保证高准确性。因此,专业的数据分析师总是试图避免这些错误,包括计算错误和任何类型的幻觉问题。
其次,在提供有见地的建议之前,专业的数据分析师通常对所有假设都很有信心。GPT4不应该直接从数据中给出任何建议或做出任何猜测,而应该小心所有假设,并使声明严格。
实验中选择问题过于具体:我们选择的问题是从NvBench数据集中随机选择的。尽管这个问题确实涵盖了很多领域、数据库、难度级别和图表类型,但根据人类数据分析师的反馈,它们仍然有些过于具体。这些问题通常包含以下信息:两个变量之间的特定相关性,特定的图表类型。在更实际的环境中,原始需求更为一般,这需要数据分析师从一般业务需求中制定这样一个特定的问题,并确定哪种图表更能代表数据。 我们的下一步是收集更多实用和通用的问题,以进一步测试GPT-4的问题制定能力。
由于预算限制,人工评估和数据分析师注释的数量相对较少。对于人的评价,我们严格选择那些专业的评价者,以便给出更好的评价。在开始人工评估之前,他们必须通过我们的几轮测试注释。对于数据分析师的选择,我们甚至更加严格。我们验证他们是否真的有数据分析工作经验,并确保他们在开始数据注释之前掌握这些技术技能。然而,由于聘请人力数据分析师(尤其是那些资深和专业的人力数据分析师)非常昂贵,我们只能要求他们做一些样本。
# 总结
像GPT-4这样的大型语言模型(LLM)取代人类数据分析师的潜力引发了一场有争议的讨论。然而,关于这个问题还没有一个明确的结论。本研究旨在通过进行几项初步实验来回答GPT-4是否能够作为一名优秀的数据分析师的研究问题。 我们设计了一个框架来提示GPT-4对来自不同领域的数据库执行端到端数据分析,并使用精心设计的特定任务评估指标将其性能与几个专业的人类数据分析师进行了比较。结果和分析表明,GPT-4可以实现与人类相当的性能,但在得出GPT-4能够取代数据分析师的结论之前,还需要进一步的研究。
# Data-Copilot(2023)
Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow
作者:Zhejiang University
# 摘要
金融、气象和能源等各个行业每天都会产生大量的异构数据。人们自然需要高效地管理、处理和显示数据。然而,这需要劳动密集型的工作和高水平的专业知识来完成这些与数据相关的任务。考虑到大型语言模型(LLM)在语义理解和推理方面表现出了很好的能力,我们主张LLM的部署可以自主管理和处理大量数据,同时以人性化的方式显示和交互。基于这一信念,我们提出了Data-Copilot,这是一个基于LLM的系统,一端连接大量数据源,另一端满足不同的人类需求。Data-Copilot像一位经验丰富的专家一样,自主地将原始数据转换为最符合用户意图的可视化结果。
具体而言,Data-Copilot自主设计用于数据管理、处理、预测和可视化的通用接口(工具)。在实时响应中,它通过根据用户的请求逐步调用相应的接口,自动部署简洁的工作流程。接口设计和部署过程完全由Data-Copilot自己控制,无需人工协助。此外,我们创建了一个Data-Copilot演示,链接来自不同领域(股票、基金、公司、经济和现场新闻)的丰富数据,并准确响应各种请求,成为可靠的人工智能助手。
# 贡献
为了有效地大规模处理数据密集型任务,我们设计了一个通用系统Data-Copilot,通过将LLM集成到管道的每个阶段,减少繁琐的劳动力和专业知识,将来自不同领域和不同用户口味的数据源连接起来。
数据Copilot可以自主管理、处理、分析、预测和可视化数据。当收到请求时,它会将原始数据转换为最符合用户意图的信息结果。
作为设计者和调度器,Data-Copilot包括两个阶段:离线接口设计和在线接口调度。Data-Copilot通过自我要求和迭代细化,设计了具有不同功能的通用接口工具。在接口调度中,它顺序或并行地调用相应的接口以获得准确的响应。
我们为中国金融市场构建了一个Data-Copilot演示。它可以访问股票、基金、经济、金融数据和实时新闻,并提供各种可视化:图形、表格和文本描述,可根据用户的要求进行定制。
# 架构

Data-Copilot是一个基于LLM的系统,用于数据相关任务,连接数十亿数据和各种用户请求。它独立设计接口工具,用于数据的高效管理、调用、处理和可视化。
在收到一个复杂的请求后,Data-Copilot会自动调用这些自设计接口来构建一个工作流,以实现人类的意图。在没有人工帮助的情况下,它可以熟练地将不同格式的异构源的原始数据转换为友好的输出,如图形、表格和文本。
Data Copilot不仅仅是一个可视化工具,它是一个通用的框架,一端连接来自不同领域的众多数据源,另一端满足不同用户的需求。它可以通过少量的种子请求不断丰富其接口工具,从而扩展其功能范围,如高级数据分析和更复杂的数据预测。为此,它包括两个过程:接口设计和接口调度。
接口设计(Interface Design):Data-Copilot采用迭代的自我请求流程,充分挖掘数据,覆盖大多数场景。如下图所示,Data-Copilot被指示从几个种子请求中生成大量不同的请求,然后将自己生成的请求抽象到接口工具中,并合并具有类似功能的接口。最后,它获得了一些通用接口,包括数据采集、处理、预测、表格操作和可视化。
接口调度(Interface Dispatch):当收到用户请求时,Data-Copilot首先解析用户意图,然后在查看自己设计的接口描述后计划接口调用过程。它能够灵活地构建具有各种结构(包括顺序、并行和循环结构)的工作流,以满足用户请求。
下面是详细介绍

# Interface Design
概括: Data-Copilot维护了一个接口工具库,用于存储当前生成的接口。首先,向LLM提供一些种子请求,并自主生成大量请求。然后LLM设计相应的接口(只有描述和参数)来处理这些请求,并在每次迭代中逐渐优化接口设计。最后,我们利用LLM强大的代码生成能力为接口库中的每个接口生成特定的代码。这个过程将接口的设计与特定的实现分离开来,创建了一组通用的接口工具,可以满足大多数请求。
Explore Data by Self-Request: 接口的设计取决于两个方面:什么样的数据可用,以及用户提出什么样的需求。Data-Copilot首先自主探索数据以挖掘更多请求。然后,基于这些请求和数据,它继续设计接口。具体来说,我们为每个数据源生成一个解析文件,以帮助LLM理解数据。每个解析文件都包括数据的描述、每列(属性)的名称、访问示例以及输出的第一行和最后一行。这个过程不需要太多的劳动力,因为数据提供商通常会提供数据和访问方法的描述。然后,我们采用自请求过程来探索数据,即这些解析文件和一些种子请求被作为提示输入LLM,并指示LLM生成更多不同的请求。 这些生成的请求用于下一步(接口定义)。允许LLM自主探索数据并自行生成请求至关重要,因为这确保了后续步骤中的接口设计是充分和通用的。在上图中,LLM基于两个种子请求和所有数据源生成四个请求。
Interface Definition: 在这一步中,Data-Copilot定义了各种接口工具来满足以前生成的请求。具体来说,我们将所有数据解析文件和存储在接口库中的所有接口(第一次迭代时为空)作为提示提供给Data-Copilot。如上图所示,每个请求都被一个接一个地输入到Data-Copilot中,并提示Data-Copilt使用接口库中的现有接口或重新定义一个新接口来满足当前请求。 重要的是,Data-Copilot只使用自然语言来定义接口的功能及其参数,而没有考虑具体的实现,这是无语法的。该过程类似于软件架构设计,但由Data-Copilot自动实现。它使Data-Copilot能够更加专注于设计具有不同功能的接口的布局和关系,而不是遵循编程语法。
Interface Merging: 为了使接口更加通用,Data-Copilot考虑了每个新设计的接口是否可以与库中现有的接口合并。具体来说,当Data-Copilot为新请求设计新接口时,它还检查该接口在功能、参数等方面是否与以前的接口相似。两个相似的接口被合并以创建一个新的通用接口。这个过程类似于软件开发人员在开发过程中将类似的模块封装到一个新模块中。通过这个过程,大量类似的接口被合并。库中的每个接口都有非常清晰的功能,并且与其他接口有很大不同,这有利于在实时响应中部署清晰简洁的工作流程。
2/3详细提示如下图所示:

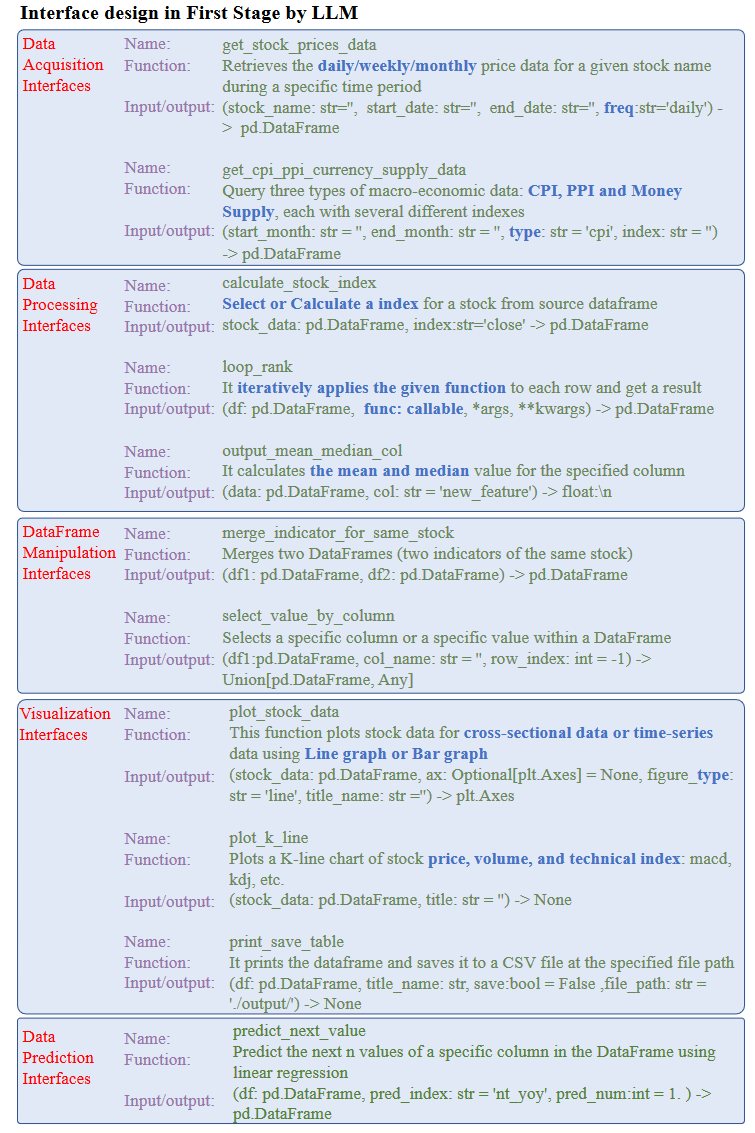
Interface Implementation: 每个请求都被依次输入Data-Copilot,用于接口定义和接口合并。最终,当库中的接口可以满足所有请求时,Data-Copilot利用LLM强大的代码生成功能为每个接口生成实现代码。整个接口设计过程是离线的。 如下图所示,Data-Copilot在接口库中自动生成五种类型的接口:数据采集、处理、预测、可视化和DataFrame操作。它将重复和乏味的劳动转化为自动化过程,还可以毫不费力地添加新的接口来适应额外的请求或新的数据源。此外,Data-Copilot还可以轻松切换到其他编程平台和数据库,只需重新生成接口的实现代码,即可实现出色的可扩展性。
大多数接口是几个简单接口的组合。例如,用蓝色标记的文本表示该接口包含多个功能。
# Interface Dispatch
概括: 在前一阶段,我们获得了用于数据采集、处理和可视化的各种通用接口工具。每个接口都有一个清晰明确的功能描述。如前图所示的两个示例,Data-Copilot通过规划和调用实时请求中的不同接口,形成了从数据到多表单结果的工作流。
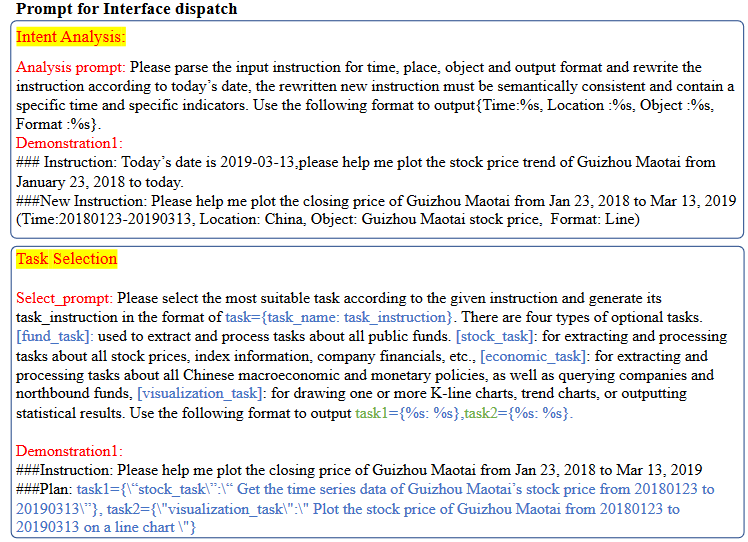
Intent Analysis: 为了准确理解用户请求,Data-Copilot首先分析用户意图。意图分析包括解析时间、位置、数据对象和输出格式,这些对数据相关任务都至关重要。为了实现这一点,我们首先调用一个外部API来获取本地时间和网络IP地址,然后将此外部信息与原始请求一起输入LLM以生成解析结果。如下所示,我们提供了一个详细的提示设计来指导该阶段的LLM。
Planing Workflow: 一旦准确理解了用户的意图,Data-Copilot就计划了一个合理的工作流程来处理用户的请求。我们指示LLM生成一个固定格式的JSON,表示调度的每个步骤。除了在设计阶段生成的界面描述外,Data-Copilot还包含了几个demo(In-context learning),作为上下文学习提示的一部分。如下图所示,每个演示都包括一条任务指令(####指令:)和相应的接口调用过程(####函数调用:),这提高了Data-Copilot对不同接口之间逻辑关系的理解。
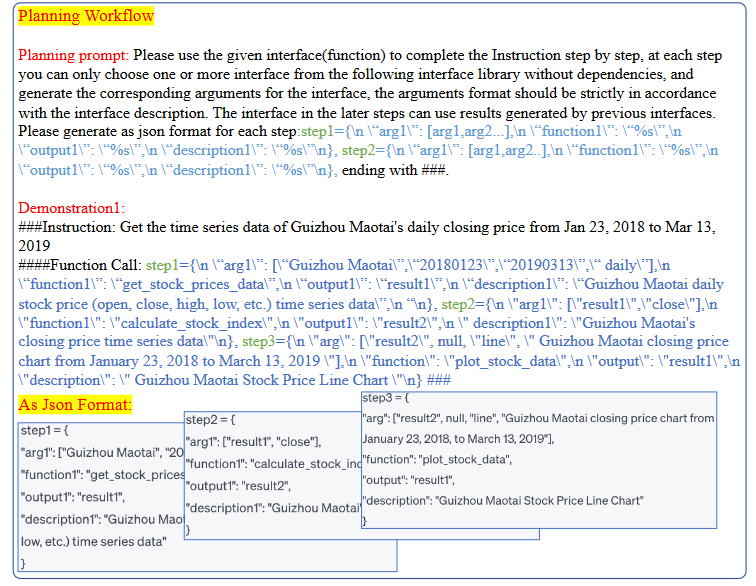
在接口描述和几次demo的提示下,Data-Copilot在每一步中都以顺序或并行的方式精心安排接口的调度。LLM根据用户的请求和接口定义自主决定应该调用哪些接口,以及调用顺序。
Multi-form Output: 在部署和执行工作流后,Data-Copilot会以图形、表格和描述性文本的形式生成所需的结果。此外,Data-Copilot还提供了整个工作流程的全面总结。这一系统总结不仅提供了清晰简洁的结果,而且阐明了为实现这些结果所采取的步骤,从而提高了与数据相关的任务的透明度和理解力。在下图中,我们提供了一个详细的示例,用户输入请求:“预测中国未来4个季度的GDP增长率。”Data-Copilot首先根据当地时间解释用户的意图。随后,它部署了一个三步工作流程:第一步涉及调用{getGDPData}接口来获取历史GDP数据。第二步涉及调用{predict next value}接口进行预测。最后一步是可视化输出。

# 实验
# 设定
我们使用中国金融数据和Gradio库构建了一个Data Copilot演示,可以访问股票、基金、经济数据、实时新闻、公司财务数据等。这允许实时数据查询、计算、分析和各种可视化。在我们的实验中,我们通过OpenAI API使用gpt-4、gpt-3.5-turbo作为LLM,并采用Tushare作为数据源。在第一阶段,Data-Copilot使用gpt-4进行接口设计,第二阶段使用gpt-3.5-turbo进行接口调度,并在接口实现阶段为每个接口生成Python代码。我们过滤在第一阶段获得的接口,保留那些可以无错误运行的接口。
此外,为了提高规划效率,我们在接口调度阶段进行了分层规划:Data-Copilot在收到请求后,首先确定所涉及的数据任务类型(库存任务、资金任务等),然后加载相应的接口描述,然后使用相应的接口进行接口规划。为了使输出结果更加稳定,我们将温度系数(temperature coefficient)设置为0。
# Case study
提供了几个案例来可视化Data Copilot部署的工作流程,其中包括使用不同结构(并行、串行和循环结构)查询不同来源(股票、公司财务、基金等)。
Different Structures: Data-Copilot根据用户需求部署了不同的结构工作流。参考具体实例。这些简洁的工作流程能够很好地处理这些复杂的请求,这表明Data Copilot的接口设计和调度过程是合理有效的。
Diverse Sources: Data-Copilot能够处理大量的数据来源,包括股票、基金、新闻、财务数据等。尽管这些数据类型的格式和访问方法截然不同,但我们的系统通过其自行设计的多功能界面高效地管理和显示数据,只需最少的人工干预。
# Limitations
Data-Copilot通过LLM提出了一种解决数据相关任务的新范式。但我们想强调的是,它仍然存在一些局限性或改进空间:
在线设计接口。Data-Copilot的本质在于有效的接口设计,这一过程直接影响后续接口部署的有效性。目前,这个界面设计过程是离线进行的。因此,探索如何在线设计接口并同时部署接口至关重要。这将大大拓宽Data-Copilot的应用场景。
系统稳定性接口部署过程偶尔会不稳定。这种不稳定性的主要来源是由于LLM不是完全可控的。尽管LLM在生成文本方面很熟练,但它们偶尔会不遵守说明或提供错误的答案,从而导致界面工作流程出现异常。因此,在接口调度过程中,寻找将这些不确定性降至最低的方法应该是未来的一个关键考虑因素。
# Lida(2023 ACL DEMO)
Lida: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models
支持用户自动创建可视化的系统必须解决几个子任务——理解数据的语义,列举相关的可视化目标,并生成可视化规范。在这项工作中,我们将可视化生成视为一个多阶段生成问题,并认为基于大型语言模型(LLM)和图像生成模型(IGM)的精心编排的管道适合于解决这些任务。
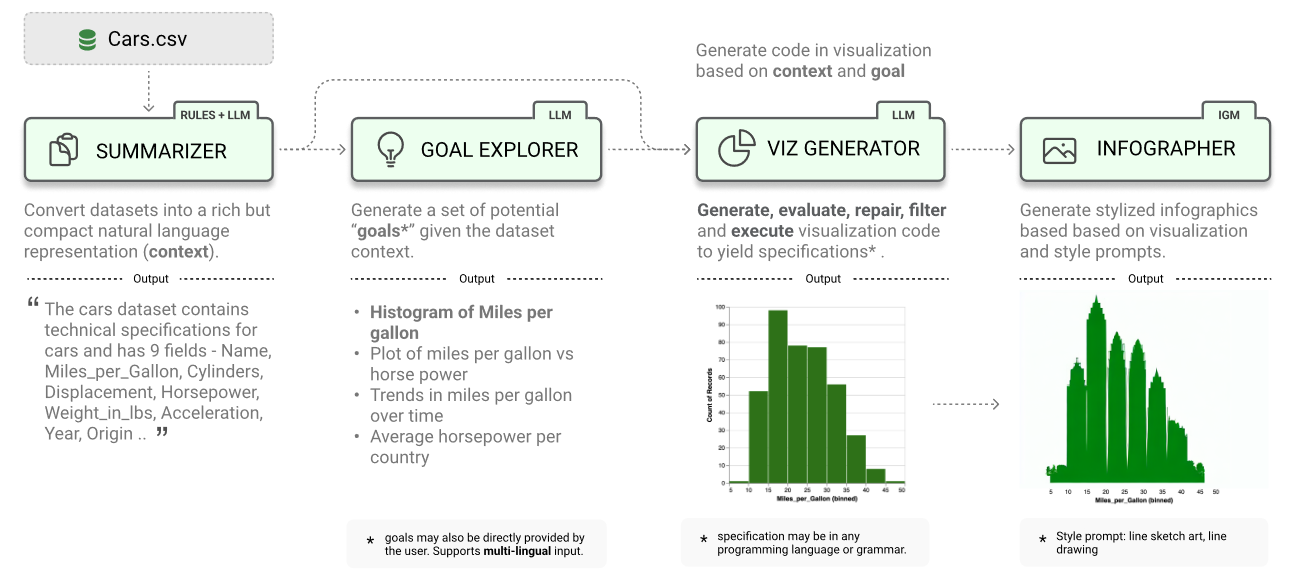
LIDA是一种用于生成语法不可知的可视化和信息图的新工具。LIDA由4个模块组成:
SUMMARIZER将数据转换为丰富但紧凑的自然语言摘要
GOAL EXPLORER列举给定数据的可视化目标
VISGENERATOR生成、细化、执行和过滤可视化代码
INFOGRAPHER模块使用IGM生成数据忠实的风格化图形。
# 实验评估
# Data Analysis任务
任务设置在NLP社区中是新的,由于没有完全匹配的数据集,我们选择了最相关的一个,称为NvBench数据集。
我们从不同领域、不同图表类型和不同难度水平随机选择100个问题进行主要实验。图表类型包括条形图、堆叠条形图、折线图、散点图、分组散点图和饼图。难度等级包括:容易、中等、难和超难。这些领域包括:体育、艺术家、交通、公寓租赁、大学等。在现有的NvBench数据集的基础上,我们还使用我们的框架为每个实例编写了5个要点的数据见解,并使用我们自行设计的评估指标评估质量。
# NL2VIS任务
将自然语言(NL)查询转换为相应的可视化(VIS),涵盖了数据分析师主要工作范围的前半部分。
# NvBench
Synthesizing natural language to visualization (nl2vis) benchmarks from nl2sql benchmarks(2021 SIGMOD)
NvBench数据集
该数据集共有153个数据库和780个表,涵盖105个领域,该任务(NL2VIS)引起了商业可视化供应商和学术研究人员的极大关注。
# Text-to-SQL任务
NL2VIS任务的另一个流行子任务称为Text-to-SQL任务,它将自然语言问题转换为sql查询。
下面是Text-to-SQL任务的三个主要基准数据集。由于这项工作更侧重于模仿数据的工作范围的整个过程
# Spider
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task(2018 ACL)
# SParC
SParC: Cross-domain semantic parsing in context(2019 ACL)
# CoSQL
CoSQL: A conversational text-to-SQL challenge towards crossdomain natural language interfaces to databases(2019 EMNLP-IJCNLP)
# 评价指标
为了全面研究性能,最早的一篇工作仔细设计了几个人工评估指标,以分别评估每个测试实例生成的图形和分析。
# Figure Evaluation
信息的正确性和图表类型的正确性是从0到1计算的,而美学是在0到3的范围内。
信息正确性(information correctness):图中显示的数据和信息正确吗?
图表类型正确性(chart type correctness):图表类型是否符合问题中的要求?
美学(aesthetics):图形是否美观清晰,没有任何格式错误?
# Analysis Evaluation
对于分析和洞察中生成的每个要点,我们定义了4个评估指标.
正确性(correctness):分析是否包含错误的数据或信息?
对齐(alignment):分析是否与问题对齐?
复杂性(complexity):分析有多复杂和深入?
流利性(fluency):生成的分析是否流畅、语法正确且没有不必要的重复?
我们以0到1的范围对正确性和一致性进行评分,以0到3的范围对复杂性和流畅性进行评分。为了进行人工评估,从一家数据注释公司聘请了6名专业的数据注释员,根据上述评估指标对每个图和分析要点进行注释。 注释者的工作得到了充分的补偿。每个数据点由两个不同的注释器独立标记。
# 其他
其他论文
Professional certification benchmark dataset: The first 500 jobs for large language models(2023)