 2D-3D-Lifting
2D-3D-Lifting
# 单人3D人体姿态估计
# Regression
# 3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network(2014 ACCV)
# Coarse-to-Fine(2017 CVPR)
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
# Compositional human pose regression(2017 ICCV)
# Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision(2017 3DV)
# Vnect(2017 TOG/SIGGRAPH)
Vnect: Real-time 3d human pose estimation with a single rgb camera
# Integral human pose regression(2018 ECCV)
# 2D-3D-Lifting
受最近2D HPE成功的推动,2D到3D提升方法从中间估计的2D人体姿态推断3D人体姿态,已成为流行的3D HPE解决方案。在第一阶段,使用现有的2D HPE模型来估计2D姿态。 在第二阶段,利用2D到3D的提升来获得3D姿态,得益于最先进的2D姿态检测器的优异性能,2D到3D提升方法通常优于直接估计方法。
总体分类(不全面)
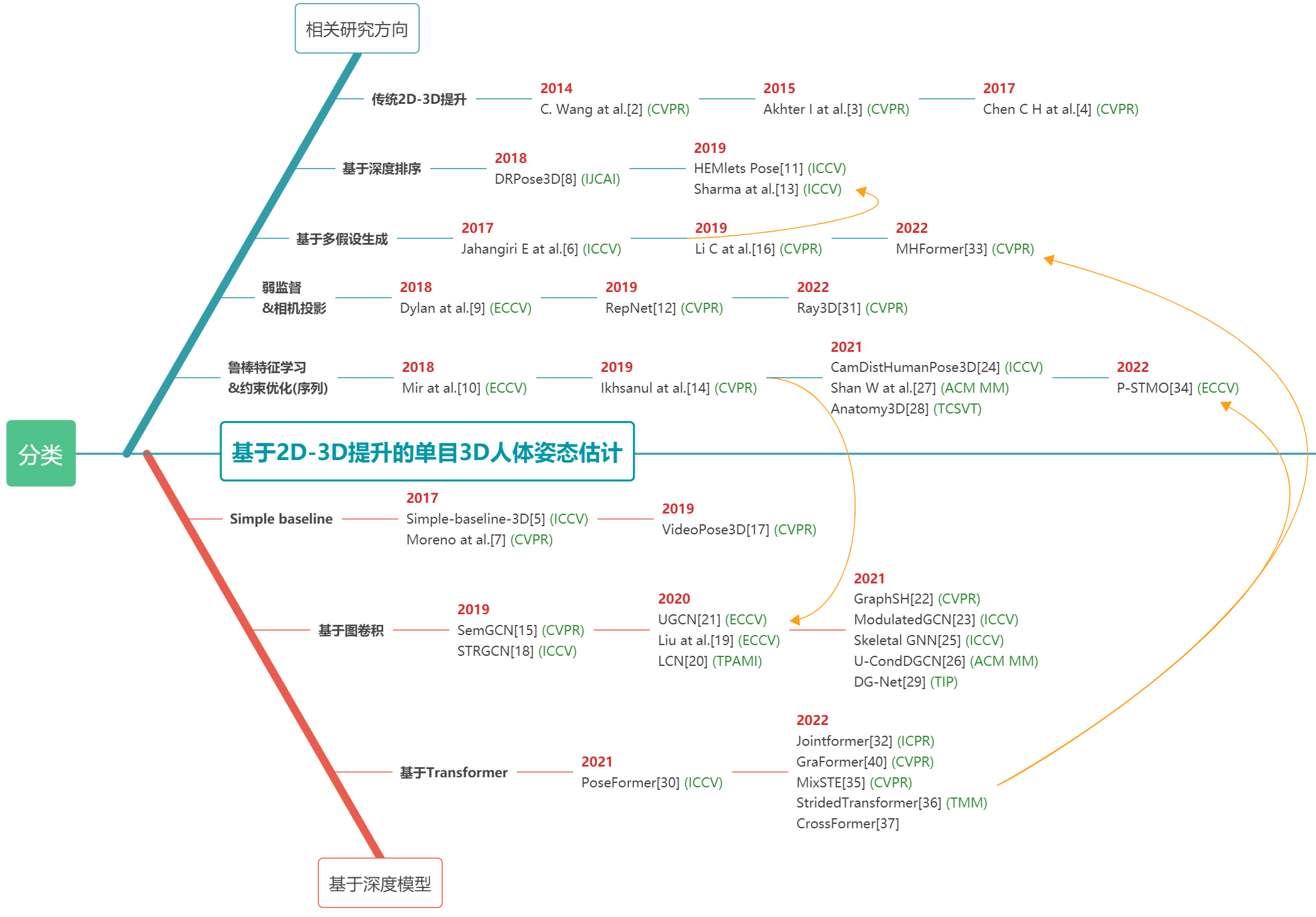
综述
Advanced Baseline for 3D Human Pose Estimation:A Two-Stage Approach
# 基于图像
# 3D Human Pose Estimation = 2D Pose Estimation + Matching(2017 CVPR)📌
2种扩展
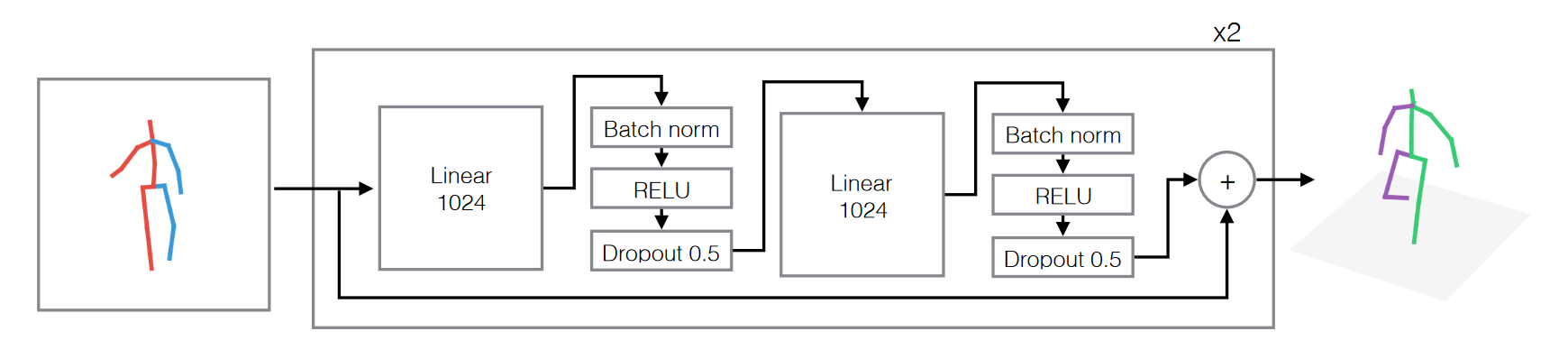
# Simple-baseline-3D(2017 ICCV)📌
A simple yet effective baseline for 3d human pose estimation
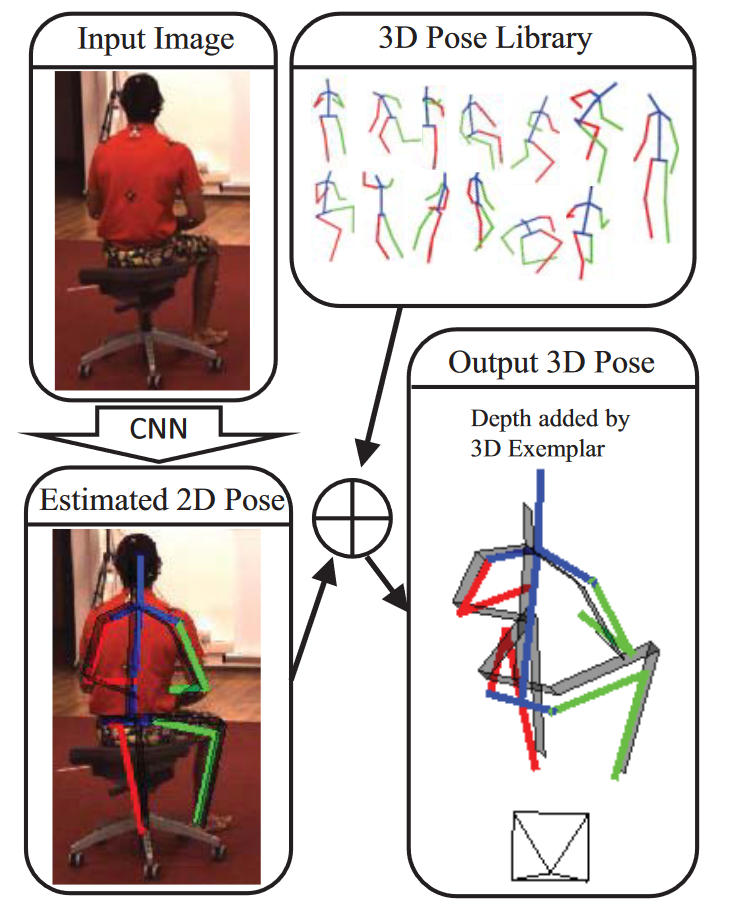
# Generating multiple diverse hypotheses for human 3d pose consistent with 2d joint detections(2017 ICCVW)
(最早提出生成多假设的工作)
由于单目图像中深度信息的丢失,通常存在与关节2D位置一致的多个3D姿态。在存在遮挡和关节2D检测不完善的情况下,3D姿态估计的不确定性增加。在本文中,我们提出了一种生成多种有效且多样化的3D姿态假设的方法,这些假设与2D联合检测一致。这些姿态假设可以稍后通过对2D关节位置以外的图像进行更详细的调查或基于一些上下文信息进行排序。
为了生成这些姿态假设,我们使用了一种新的无偏生成模型,该模型仅对关节角度限制和肢体长度比实施姿态条件解剖学约束。这是由[1]在识别典型MoCap数据集中的偏差后得出的姿态条件关节限制引起的。我们的合成生成模型统一地跨越了人类3D姿态的全部可变性,这有助于生成更多样化的假设。
我们对H36M数据集进行了实证评估,与其他近期基线估计的姿态相比,最佳姿态假设的平均关节误差更低。基线方法输出的3D姿态也可以作为一个假设,但为了研究我们的假设生成方法,我们在实验结果中没有这样做。我们的实验表明,在只给出关节的二维位置的情况下,尤其是当某些关节缺失时,具有多个3D姿态假设的重要性。我们希望我们生成多姿态假设的想法能够启发未来在考虑各种模糊源的3D姿态估计方面的新工作。
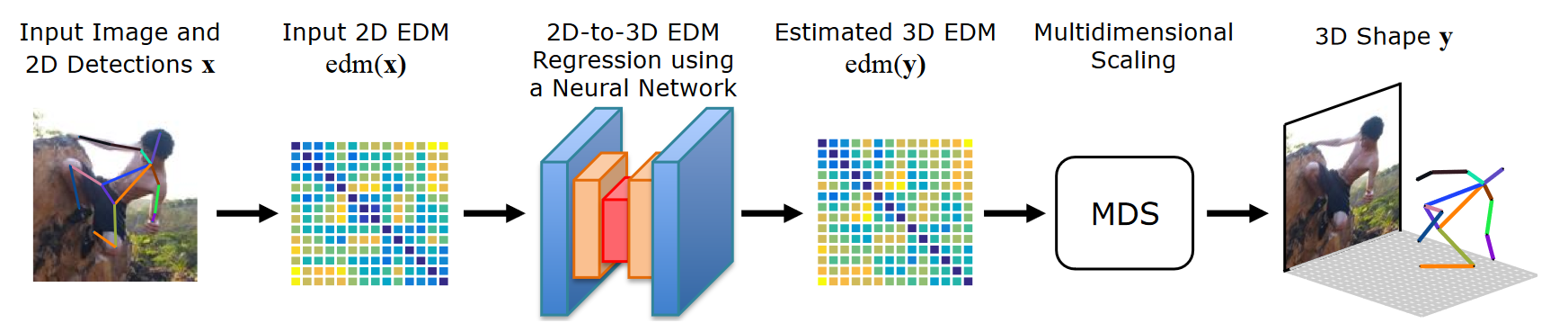
# Moreno(2017 CVPR)
3d human pose estimation from a single image via distance matrix regression
# Ordinal Depth Supervision(2018 CVPR)
Ordinal Depth Supervision for 3D Human Pose Estimation
# OriNet(2018 BMVC)
OriNet: A Fully Convolutional Network for 3D Human Pose Estimation
# DRPose3D(2018 IJCAI)
DRPose3D: Depth Ranking in 3D Human Pose Estimation
在本文中,我们提出了一种基于两阶段深度排序的方法(DRPose3D)来解决三维人体姿态估计问题。代替精确的3D位置,深度排名可以由人类直观地识别,并通过解决分类问题更容易地使用深度神经网络学习。 此外,深度排名包含丰富的3D信息。它可以防止两阶段方法中的2D到3D姿态回归不适定。在我们的方法中,首先,我们设计了成对排名卷积神经网络(PRCNN)来从图像中提取人类关节的深度排名。其次,提出了一种从粗略到精细的3D姿态网络(DPNet)来从深度排名和2D人类关节位置估计3D姿态。此外,为了提高模型的通用性,我们引入了一种统计方法来增强深度排名。对于所有三种测试协议,我们的方法都优于Human3.6M基准测试中的最先进方法,这表明深度排序是一个重要的几何特征,可以通过学习来改进3D姿态估计。
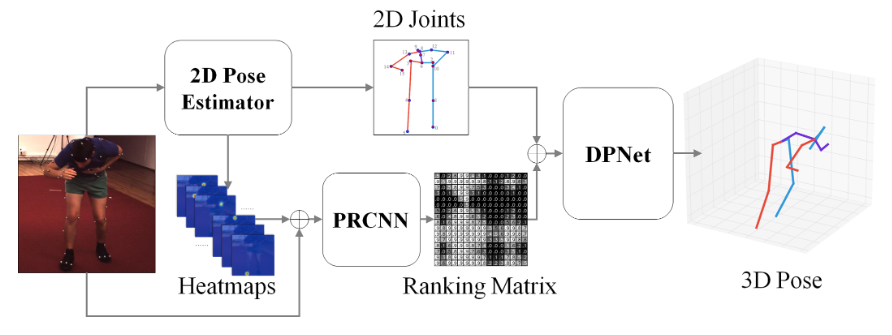
DPNet
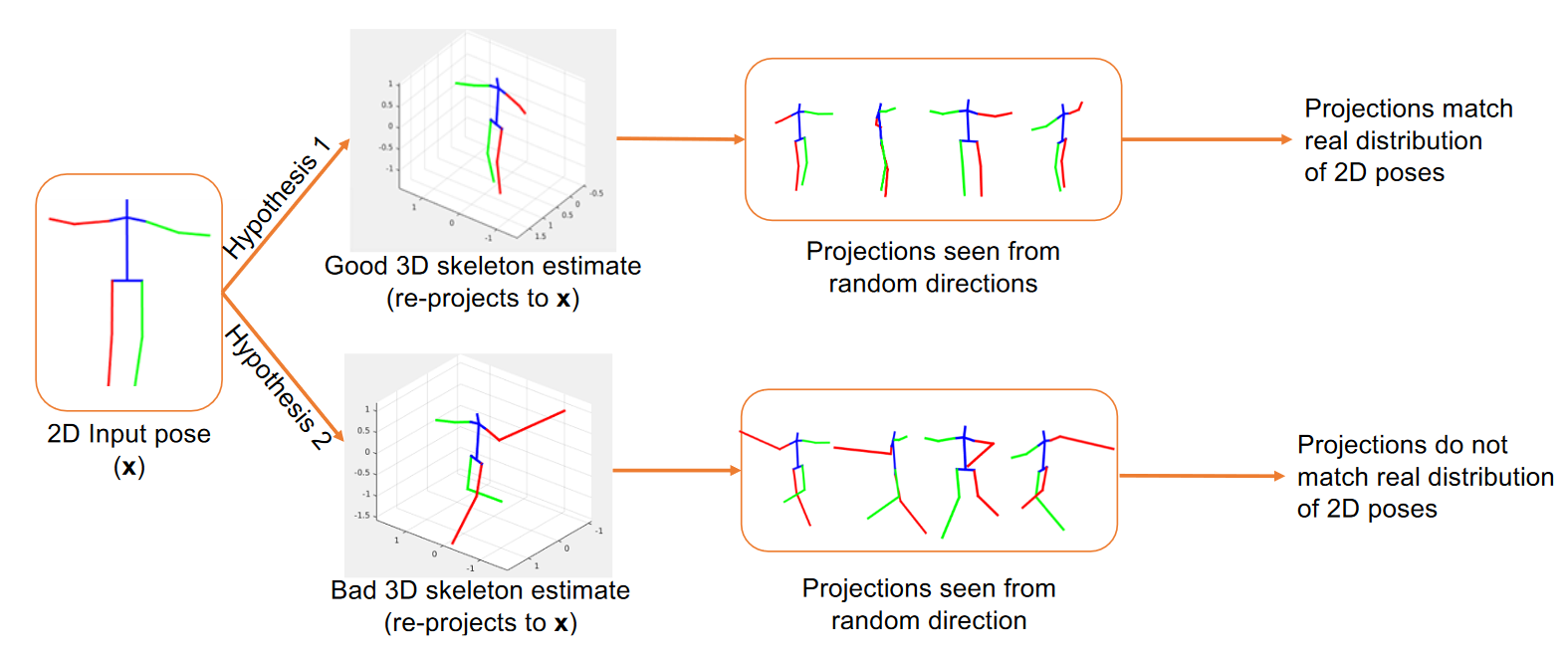
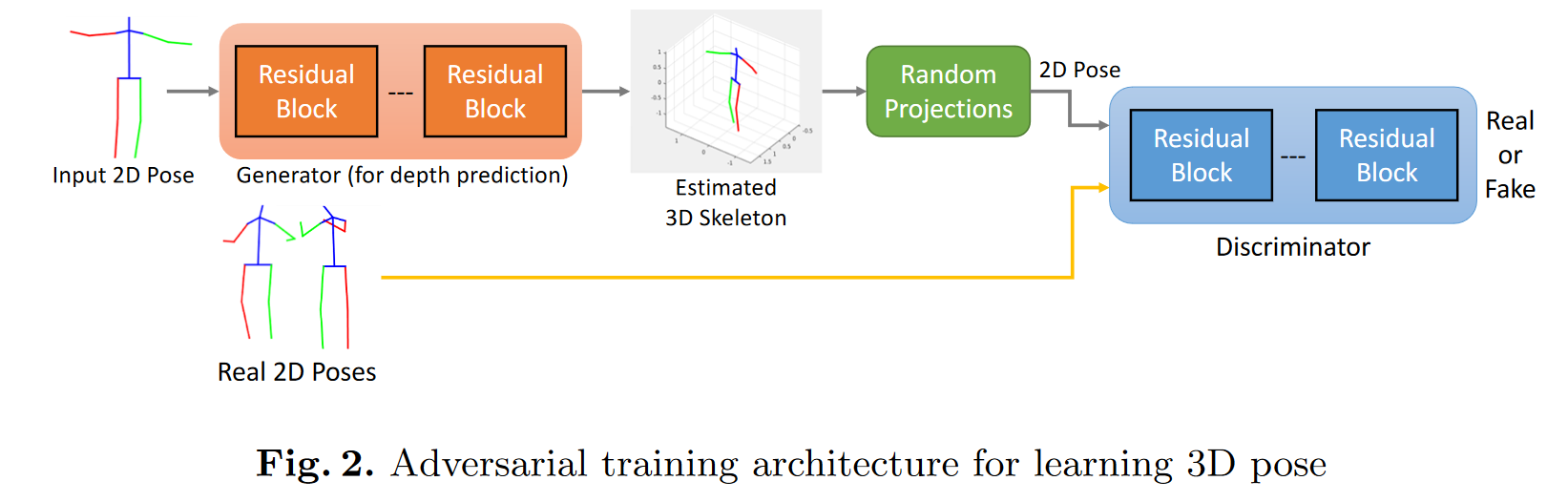
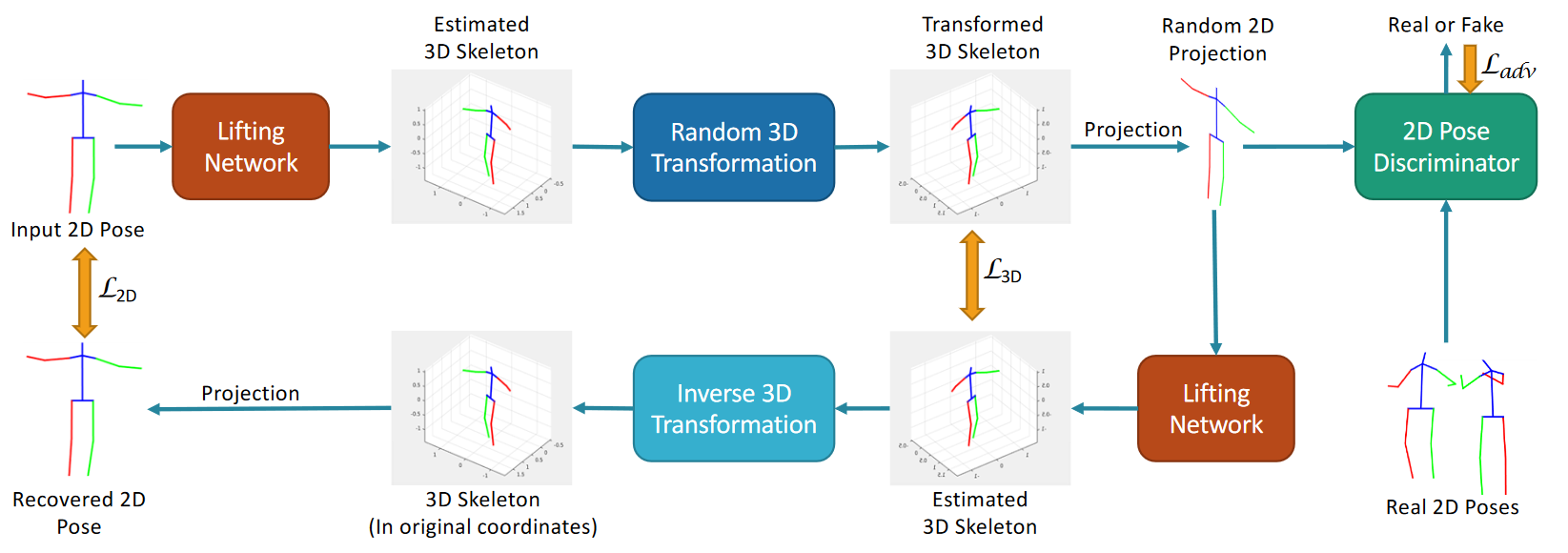
# Can 3D Pose be Learned from 2D Projections Alone?(2018 ECCV Weakly Supervised)
虽然最近在深度学习方面取得的大多数进展都是由标记数据推动的,但很难为大多数计算机视觉问题获得高质量的注释。我们提出了一种弱监督的方法来估计3D姿态点,仅给出2D姿态标记。我们的方法不需要2D和3D点之间的对应关系来构建明确的3D优先级。我们利用一个对抗性框架对3D结构施加一个先验,这完全是从它们的随机2D投影中获得的。给定一组2D姿态地标,生成器网络假设其深度以获得3D骨架。我们提出了一个新的随机投影层,它随机投影生成的3D骨架,并将生成的2D姿态发送给鉴别器。鉴别器通过从2D姿态的实际分布中区分生成的姿态和姿态样本来改进。训练不需要与生成器或鉴别器的2D输入之间的对应关系。我们将我们的方法应用于三维人体姿态估计任务。Human3.6M数据集上的结果表明,我们的方法优于许多以前的监督和弱监督方法。
我们方法背后的关键直觉:生成器可以为给定的输入2D姿态假设多个3D骨骼。然而,只有看似合理的3D骨架才能在随机投影后投影到逼真的2D姿态。鉴别器评估投影2D姿态的“真实性”,并向生成器提供适当的反馈,以学习生成逼真的3D骨架。
# On Boosting Single-Frame 3D Human Pose Estimation via Monocular Videos(2019 ICCV)
# Unsupervised 3D Pose Estimation with Geometric Self-Supervision (2019 CVPR)
我们提出了一种无监督学习方法,从从单个图像提取的2D骨骼关节中恢复3D人体姿态。我们的方法不需要任何多视图图像数据、3D骨架、2D-3D点之间的对应关系,也不需要在训练期间使用先前学习的3D先验。提升网络接受2D地标作为输入并生成相应的3D骨架估计。在训练期间,恢复的3D骨架将被重新投影到随机相机视点上,以生成新的“合成”2D姿态。通过将合成2D姿态提升回3D并在原始相机视图中重新投影,我们可以定义3D和2D中的自一致性损失。 因此,可以通过利用升力再投影升力过程的几何自洽性来自我监督训练。我们表明,仅自一致性不足以生成真实的骨架,但是添加2D姿态鉴别器可以使升降机输出有效的3D姿态。此外,为了从“野外”的2D姿态中学习,我们训练了一个无监督的2D域适配器网络,以允许扩展2D数据。这改善了结果,并证明了2D姿态数据对于无监督3D提升的有用性。用于3D人体姿态估计的Human3.6M数据集的结果表明,我们的方法比以前的无监督方法提高了30%,并且优于许多明确使用3D数据的弱监督方法。
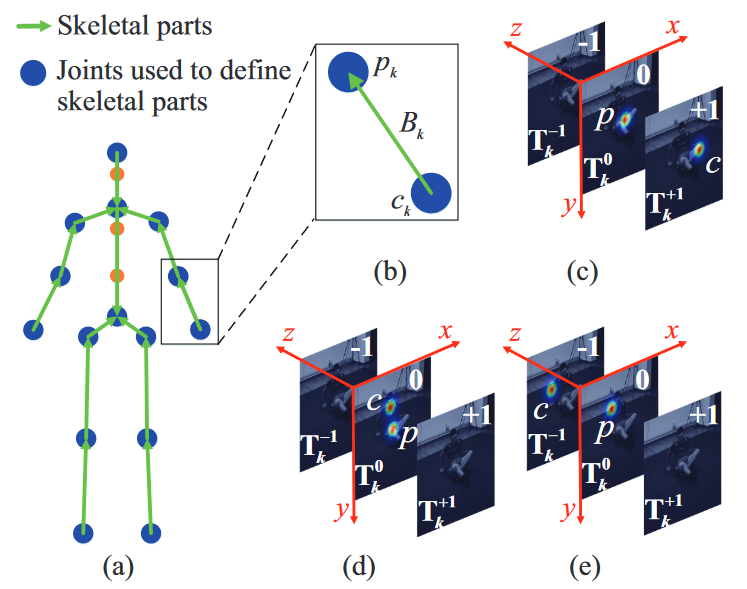
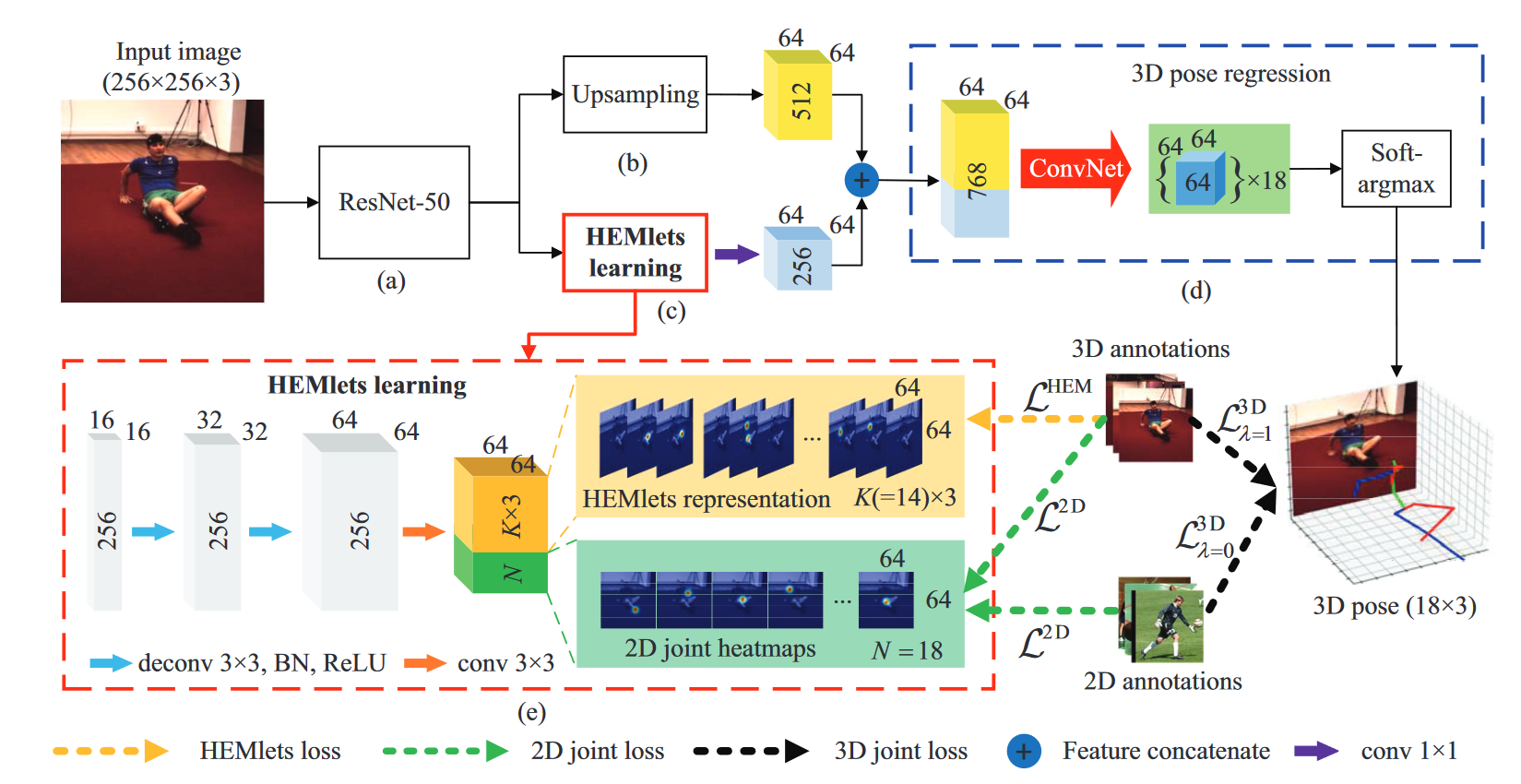
# HEMlets Pose(2019 ICCV)
HEMlets Pose: Learning Part-Centric Heatmap Triplets for Accurate 3D Human Pose Estimation
从单个图像估计3D人体姿态是一项具有挑战性的任务。这项工作试图通过引入一种中间状态——以部位为中心的热图三重态(HEMlet)来解决将检测到的2D关节提升到3D空间的不确定性,该中间状态缩短了2D观测和3D解释之间的差距。HEMlet利用三个关节热图来表示每个骨骼体部位末端关节的相对深度信息。在我们的方法中,首先训练卷积网络(ConvNet)从输入图像预测HEMlet,然后进行体积联合热图回归。我们利用积分运算从体积热图中提取关节位置,确保端到端的学习。尽管网络设计简单,但定量比较表明,与最佳方法相比,性能有了显著提高(Human3.6M约为20%)。提出的方法自然支持“野生”图像的训练,其中只有骨骼关节的弱注释相对深度信息可用。这进一步提高了我们模型的泛化能力,室外图像的定性比较验证了这一点。
以部位为中心的热图三重态(HEMlet),其中p和c是父关节和子关节。(a、b)关节和骨骼部件。我们将第k个骨骼部分Bk的母关节p定位在零极性热图T0k(c-e)。根据p和c的相对深度,子关节c分别位于正(c)、零(d)和负极性热图(e)中。
# RepNet(2019 CVPR)
RepNet:Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human PoseEstimation
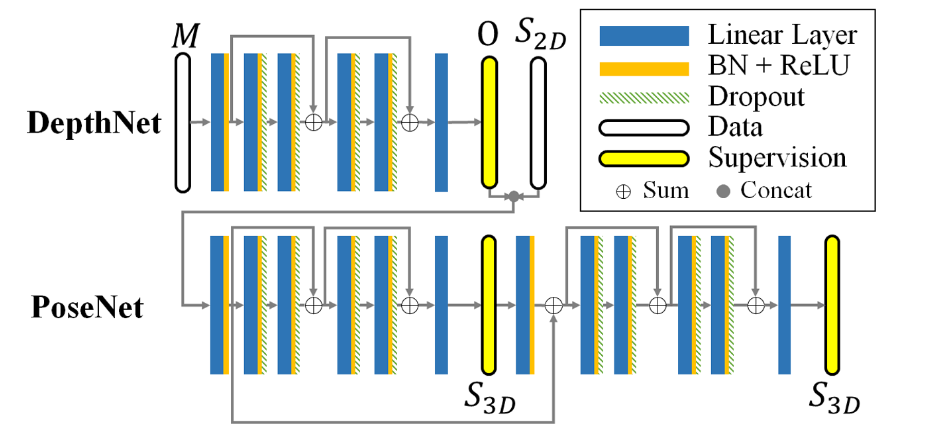
本文研究了基于单帧图像的三维人体姿态估计问题。长期以来,通过满足重投影误差,人类骨骼被参数化并拟合到观测值中,而现在研究人员直接使用神经网络从观测值中推断出3D姿态。然而,这些方法大多忽略了必须满足重投影约束这一事实,并且对过拟合敏感。我们通过忽略2D到3D的对应关系来解决过拟合问题。这有效地避免了对训练数据的简单记忆,并允许弱监督训练。提议的重投影网络(RepNet)的一部分使用对抗性训练方法学习从2D姿态分布到3D姿态分布的映射。网络的另一部分估计摄像机。这允许定义一个网络层,该网络层将估计的3D姿态重投影回2D,从而产生重投影损失函数。我们的实验表明,RepNet能够很好地泛化未知数据,在应用于未知数据时,性能优于最先进的方法。此外,我们的实现在标准台式PC上实时运行。
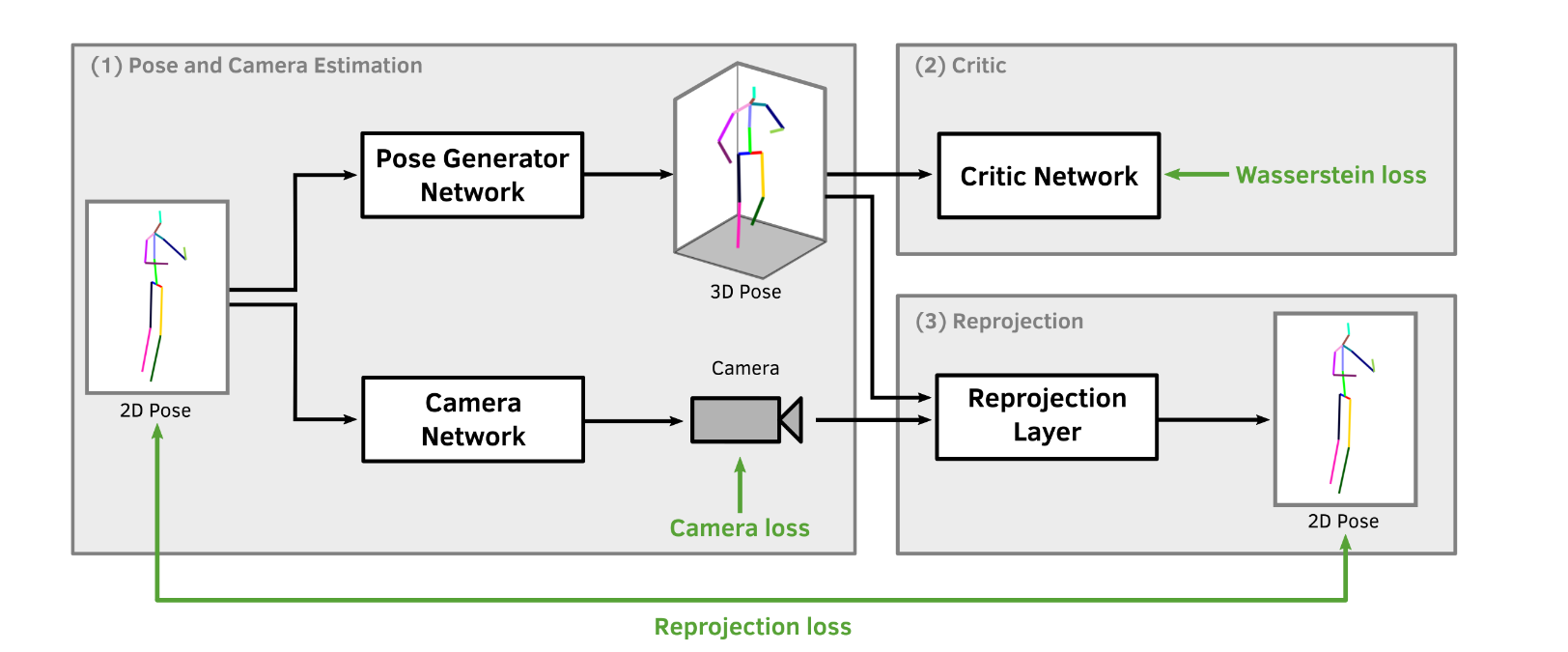
该方法的基本思想是,通过学习从输入分布(2D姿态)到输出分布(3D姿态)的映射,从2D观测值回归3D姿态。在标准生成性对抗网络(GAN)训练[9]中,发电机网络学习从输入分布到输出分布的映射,输出分布由另一个神经网络(称为鉴别器网络)评定。鉴别器经过训练,可以区分数据库中的真实样本和生成器网络中创建的样本。
当训练生成器创建鉴别器预测为真实样本的样本时,鉴别器参数是固定的。生成器和鉴别器交替训练,因此相互竞争,直到它们都收敛到最小值。在标准GAN训练中,输入是从高斯或均匀分布中采样的。这里,我们假设输入是从人体姿态的2D观测分布中采样的。采用Wasserstein GAN命名[3],我们在下面称之为鉴别器批评家。在不了解摄像机投影的情况下,该网络会生成随机但可行的人体3D姿态。然而,这些3D姿态很可能是输入2D观测值的错误3D重建。为了获得匹配的2D和3D姿态,我们提出了一个摄像机估计网络,然后是一个重投影层。如图2所示,提议的网络由三部分组成:姿态和摄像机估计网络(1)、对抗训练中使用的批评家(2)和再现部分(3)。如上所述,交替训练批评者和完整的对手模型。
我们在三个数据集Human3.6M、MPI-INF-3DHP和LSP上进行实验。Human3.6M是最大的基准数据集,包含与2D和3D对应的时间对齐图像。除非另有说明,否则我们使用Human3.6M训练集来训练我们的网络。为了在未发现的数据上显示定量结果,我们在MPIINF-3DHP上评估了我们的方法。对于不寻常的姿态和相机角度,主观结果显示在LSP上。匹配最具可比性的方法,我们使用堆叠沙漏网络对大多数实验中的输入图像进行二维联合估计。
# MultiPoseNet with Oracle(2019 ICCV)
Monocular 3D Human Pose Estimation by Generation and Ordinal Ranking
由于维度灾难和从二维提升到三维的不适定性,从静态图像进行单目三维人体姿态估计是一个具有挑战性的问题。在本文中,我们提出了一种基于深度条件变分自动编码器的模型,该模型以估计的2D姿态为条件,综合各种解剖上看似合理的3D姿态样本。我们表明,基于CVAE的3D姿态样本集与2D姿态一致,有助于解决2D到3D提升中固有的模糊性。我们提出了两种获得最终3D姿态的策略——(a)去排序关系,以对候选3D姿态进行评分和加权平均,称为OrdinalScore,以及(b)在Oracle的监督下(真实标签筛选)。我们使用OrdinalScore报告了两个基准数据集的最新结果,并使用Oracle报告了最新结果。我们还表明,我们的产品线在不使用成对图像到3D注释的情况下产生了具有竞争力的结果。
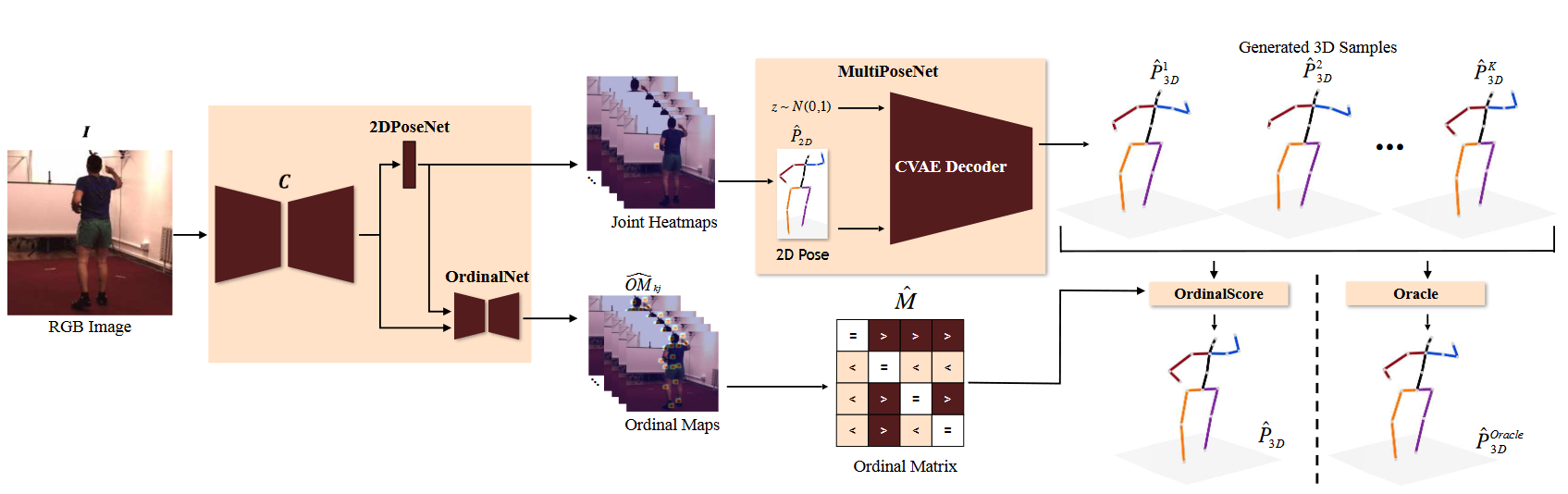
MultiPoseNet
如下是训练过程,测试过程去掉编码器
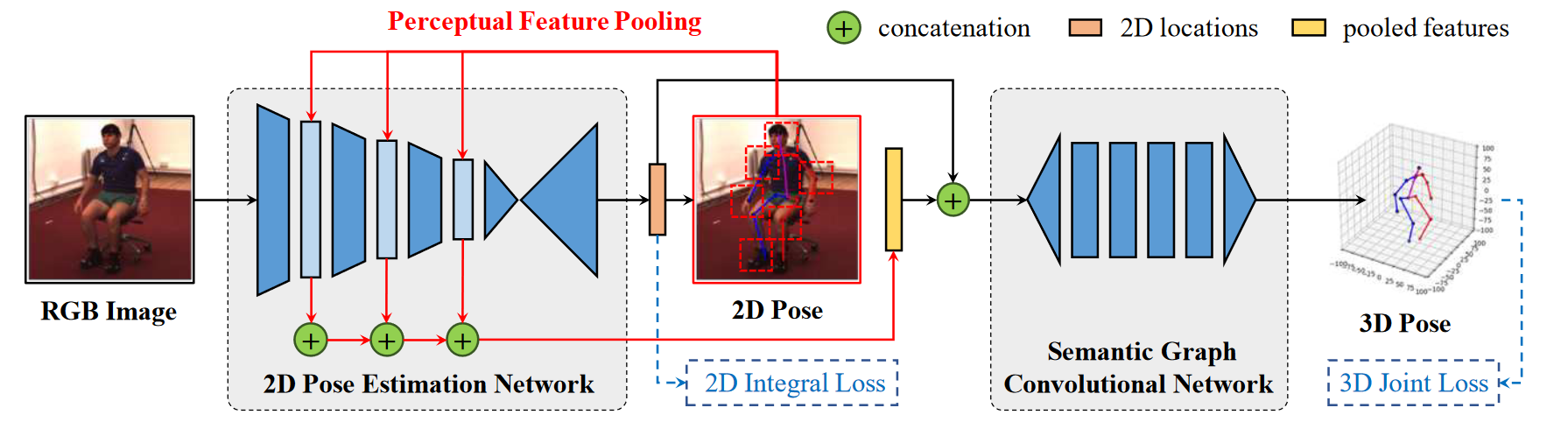
# In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations(2019 CVPR)
我们提出了一种新的深度学习结构,用于从单目彩色图像中估计三维人体姿态。它是为训练这两种图像而设计的,更多的真实图像带有地面真实3D姿态标签,而更多的野生图像只有2D姿态标签。我们的体系结构通过在潜在特征空间中显式分离的2D姿态表示和学习的3D-to-2D投影模型,增强了主干3D姿态推理网络。我们的算法在工作室内的H3.6M数据集上达到了最先进的性能,在更具挑战性的MPI-INF-3DHP基准测试中,与野生图像相比,明显优于相关工作。
我们使用CNN fRGB学习3D姿态特征,表示为2D热图位置h2D和潜在空间中的附加3D姿态提示d。这两个信息分别用于使用网络f3D和fc预测以根为中心的3D姿态p3D和视点参数c。最后,我们连接p3D和c来学习2D关键点信息h2D,即使3D标签不可用,网络也可以更新3D姿态信息。

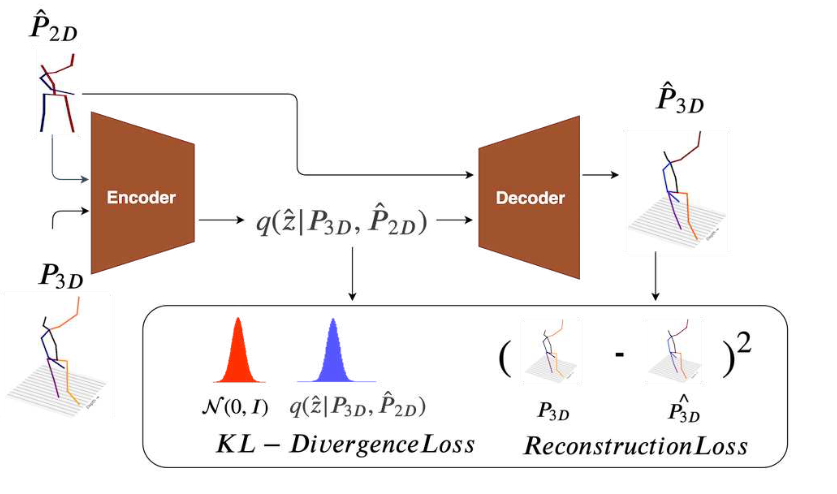
# SemGCN(2019 CVPR)📌
Semantic Graph Convolutional Networks for 3D Human Pose Regression
在本文中,我们研究了用于回归的图卷积网络(GCN)的学习问题。GCN的当前架构局限于卷积滤波器和每个节点的共享变换矩阵的小接收域。为了解决这些局限性,我们提出了语义图卷积网络(SemGCN),这是一种新的神经网络架构,它使用图结构数据处理回归任务。SemGCN学习捕获语义信息,如局部和全局节点关系,这些信息在图中没有明确表示。这些语义关系可以通过端到端的训练从实际情况中学习,而无需额外的监督或手工制定的规则。我们进一步研究了将SemGCN应用于三维人体姿态回归。我们的公式是直观和充分的,因为2D和3D人体姿态都可以表示为编码人体骨架中关节之间关系的结构化图形。我们进行了全面的研究以验证我们的方法。结果证明,SemGCN优于现有技术,同时使用的参数减少了90%。
Semantic Graph Convolutional Networks

# MDN(2019 CVPR)
Generating Multiple Hypotheses for 3D Human Pose Estimation With Mixture Density Network
由于深度模糊和关节遮挡,从单眼图像或2D关节进行3D人体姿态估计是一个不适定问题。我们认为,单目输入的3D人体姿态估计是一个逆问题,其中可能存在多个可行的解决方案。 在本文中,我们提出了一种新的方法来从2D关节生成3D姿态的多个可行假设。与基于单峰高斯分布最小化均方误差的现有深度学习方法相比,我们的方法能够基于多模态混合密度网络生成3D姿态的多个可行假设。我们的实验表明,通过我们的方法从2D关节的输入估计的3D姿态在2D重投影中是一致的,这支持了我们的论点,即2D到3D逆问题存在多个解。此外,我们在最佳假设和多视图设置下展示了Human3.6M数据集的最先进性能,并通过在MPII和MPI-INF-3DHP数据集上进行测试,展示了我们模型的泛化能力。我们的代码可在项目网站1上获得。
# SRNet(2020 ECCV)
SRNet: Improving Generalization in 3D Human Pose Estimation with a Split-and-Recombine Approach
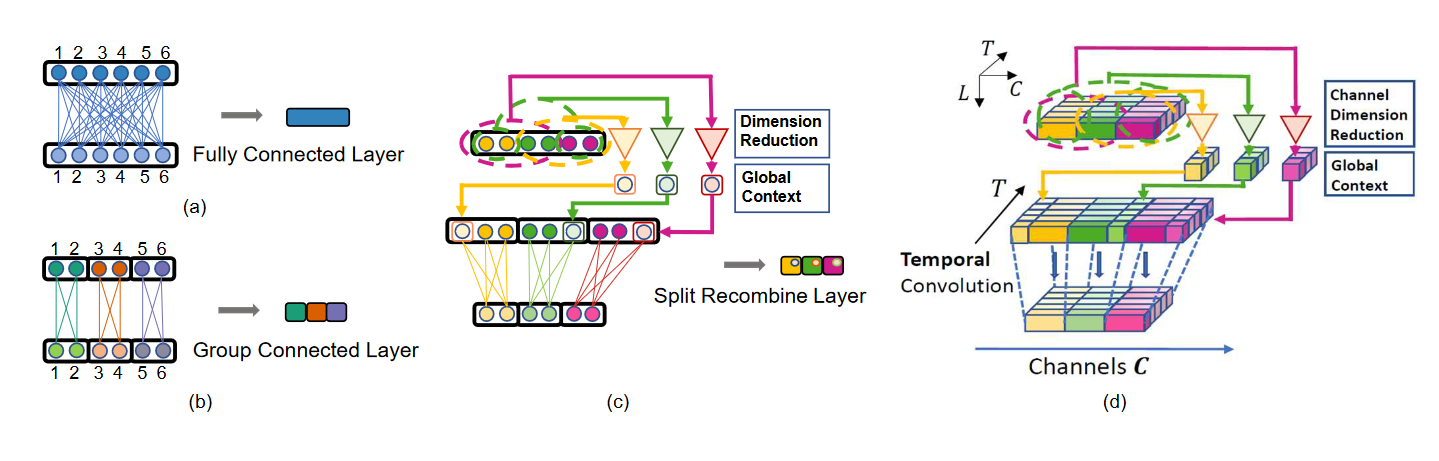
对于网络来说,在训练集中罕见或看不见的人类姿态很难预测。类似于视觉识别中的长尾分布问题,这种姿态的例子数量很少,限制了网络建模的能力。有趣的是,局部姿态分布较少受到长尾问题的影响,即,罕见姿态内的局部关节配置可能出现在训练集中的其他姿态内,使其不那么罕见。我们建议利用这一事实,更好地概括罕见和不可见的姿态。具体来说,我们的方法将身体分割成局部区域,并在单独的网络分支中处理它们,利用关节的位置主要取决于其局部身体区域内的关节的特性。 全局一致性是通过将来自身体其余部分的全局上下文作为低维向量重新组合到每个分支中来保持的。随着相关度较低的身体区域的维数降低,网络分支内的训练集分布更紧密地反映了局部姿态的统计信息,而不是全局身体姿态,而不牺牲对联合推断重要的信息。所提出的分割和重组方法,称为SRNet,可以很容易地适用于单图像和时间模型,并在罕见和不可见姿态的预测方面带来了显著的改进。
说明(a)完全连接层,(b)分组连接层,以及(c)我们的分裂和重组层(split-and-recombine layer),和(d)我们的时间模型卷积层。这四种类型的层可以堆叠形成不同的网络结构
# WAGAN(2020 BMVC)
Weakly Supervised Generative Network for Multiple 3D Human Pose Hypotheses
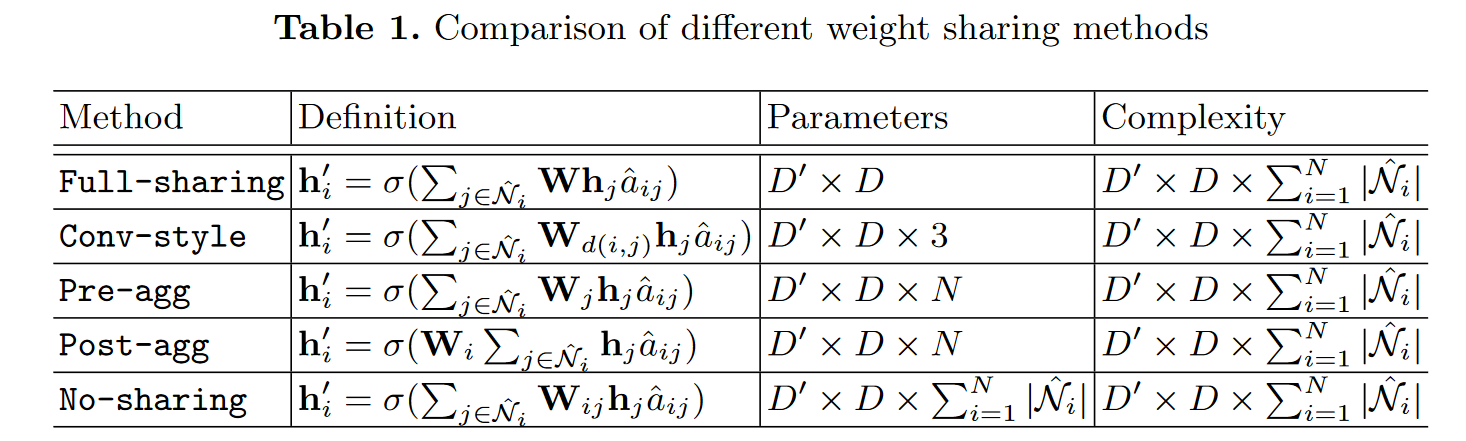
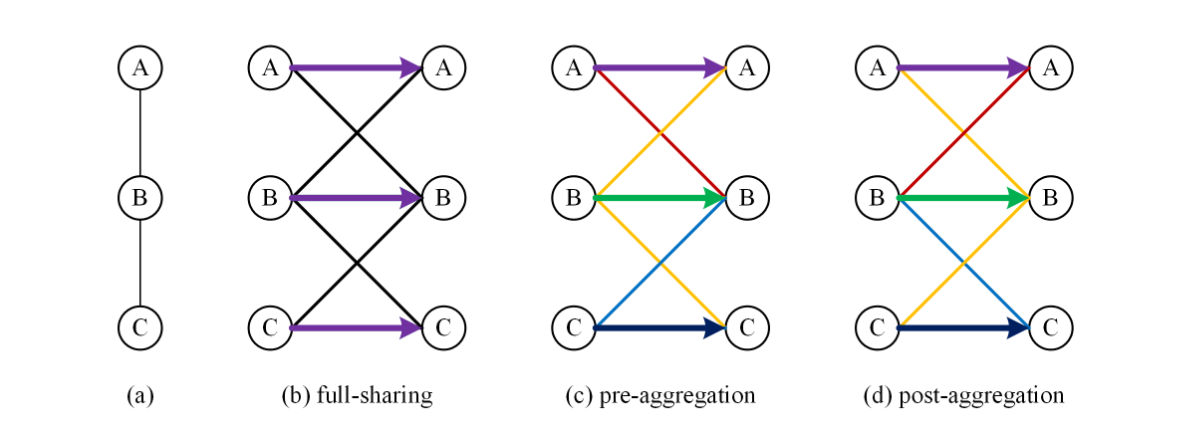
# A Comprehensive Study of Weight Sharing in Graph Networks for 3D Human Pose Estimation(2020 ECCV)
图卷积网络(GCN)已应用于二维人体关节检测的三维人体姿态估计(HPE),并显示出令人鼓舞的性能。vanilla图卷积的一个限制是,它通过共享权重矩阵来建模相邻节点之间的关系。由于不同身体关节之间的关系不同,这对于关节式车身建模来说是次优的。本文的目的是对3D HPE的GCN中的权重分配进行全面系统的研究。我们首先展示了两种不同的方式来解释GCN,这取决于特征转换是在特征聚合之前还是之后发生。这两种解释导致了五种不同的权重分担方法,通过将自连接与其他边解耦,可以得到另外三种变体。我们在受控环境下对这些体重分担方法进行了广泛的消融研究,并得出了有益于社区的新结论。
五种权重共享方法的图示。权重取消共享通过不同的颜色进行编码。对于卷积样式,我们假设节点的坐标定义为其到节点a的图形距离。
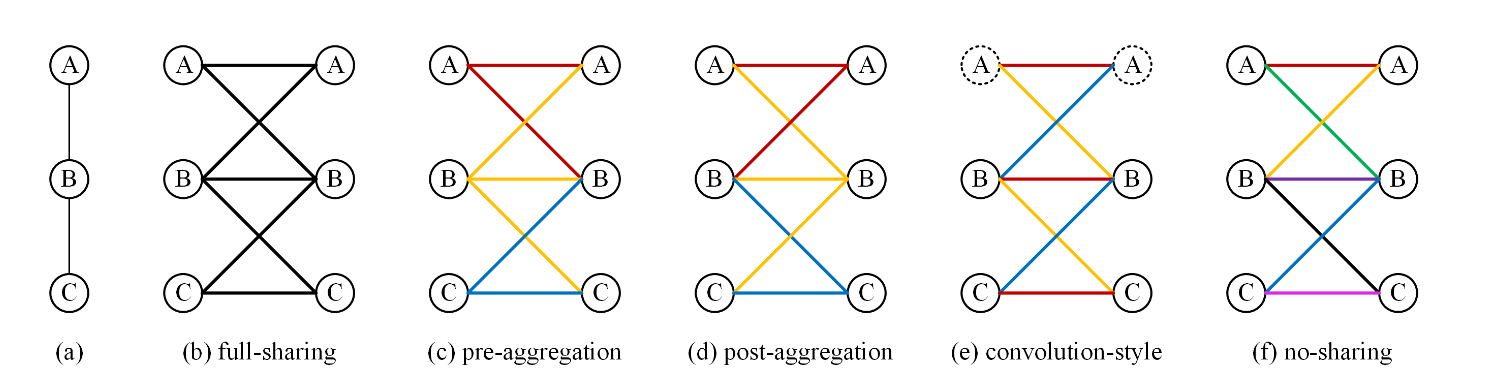
解耦自连接权重分配方法的图示。权重取消共享通过不同的颜色进行编码。箭头表示与自连接对应的权重
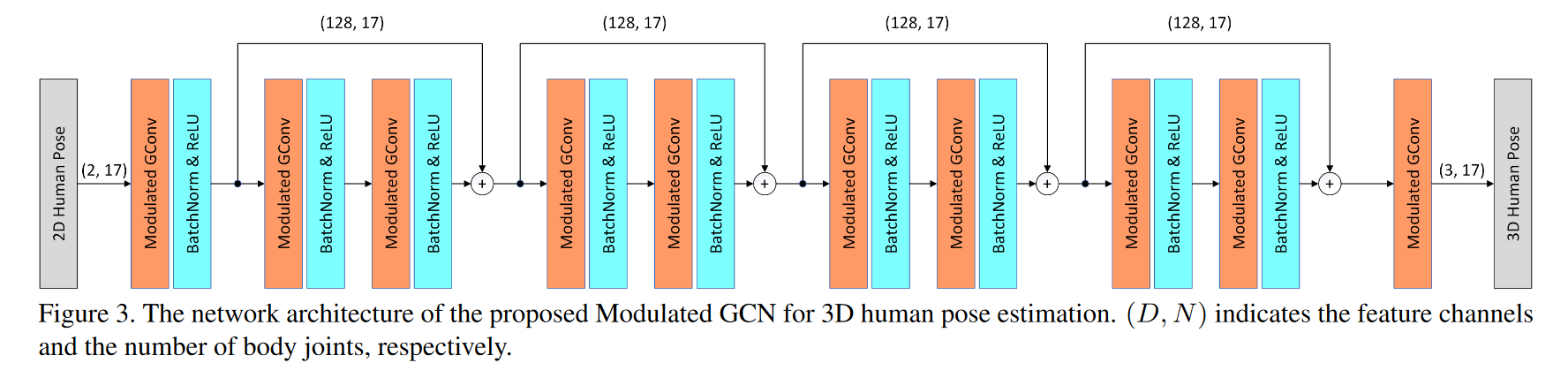
二维到三维姿态提升的GCN架构示例。构建块是由两个具有128个通道的图卷积层组成的剩余块。此块重复四次。每个图卷积层(最后一层除外)之后是一个批处理归一化层和一个ReLU激活。

本文对3D HPE的GCN中的权重分配进行了全面系统的研究。经过广泛的消融研究和基准比较,我们得出以下结论。(1) GCN中的权重分配方法对HPE性能有很大影响。更多的参数不一定会带来更好的性能。(2) 解耦自连接总是有益的。(3) 在本文讨论的所有图卷积变体中,预聚集是3D HPE的最佳权重分配方法。
# LCN(2020 TPAMI)
Locally Connected Network for Monocular 3D Human Pose Estimation
Optimizing Network Structure for 3D Human Pose Estimation(2019 ICCV)
人体姿态自然地表示为一个图形,其中关节是节点,骨骼是边。因此,应用图卷积网络(GCN)从二维姿态估计三维姿态是很自然的。在这项工作中,我们提出了一个通用公式,其中GCN和全连接网络(FCN)都是其特例。从这个公式中,我们发现GCN在用于估计3D姿态时具有有限的表示能力。我们通过引入本地连接网络(LCN)克服了这个限制,LCN是由这个通用公式自然实现的。它显著提高了GCN的表示能力。此外,由于每个关节只连接到其邻域中的几个关节,因此它具有很强的泛化能力。在公共数据集上的实验表明:(1)优于最先进的技术;(2) 与替代模型相比,数据需求更少;(3) 很好地概括为不可见的操作和数据集。
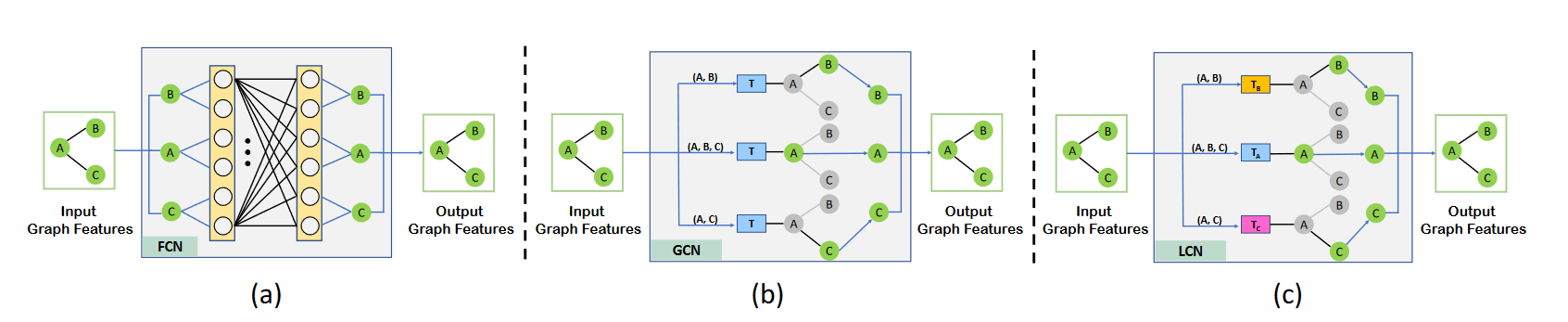
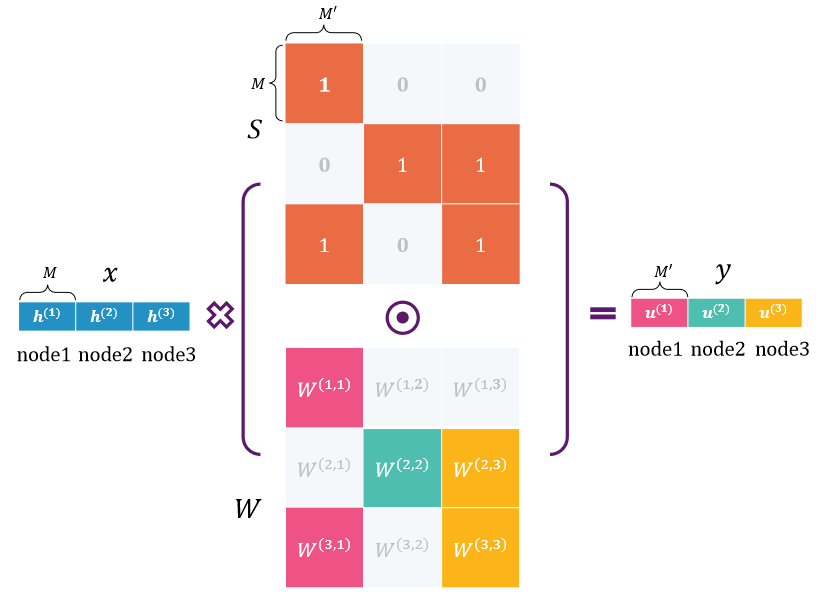
LCN layer
假设我们有3个节点,其特征用蓝色条表示。权重矩阵W和结构矩阵S∈ R3M×3M′平均分为3×3个区块。我们在结构矩阵的适当位置填充零,以消除相应关节对之间的相关性。例如,节点1的输出特征仅取决于节点1和3的输入特征。
对于三维姿态估计任务,我们构建了一个深度神经网络,它使用上述LCN层作为基本构建块。受Martinez等人[18]和Defferrard等人[6]提出的网络结构的启发,我们的LCN有几个级联块,每个块由两个LCN层组成,与BN、LeakyReLU和Dropout交错。每个块都包裹在一个剩余连接中。每个LCN层中的输出特征M′的数量设置为64。值得注意的是,不同层共享相同的结构矩阵,但具有不同的权重矩阵。 LCN网络的输入是人体关节的2D位置,输出是相应的3D位置。我们在输出和地面实况之间使用L2损失。网络可以端到端培训。

# TAG-Net(2020 CVPR)
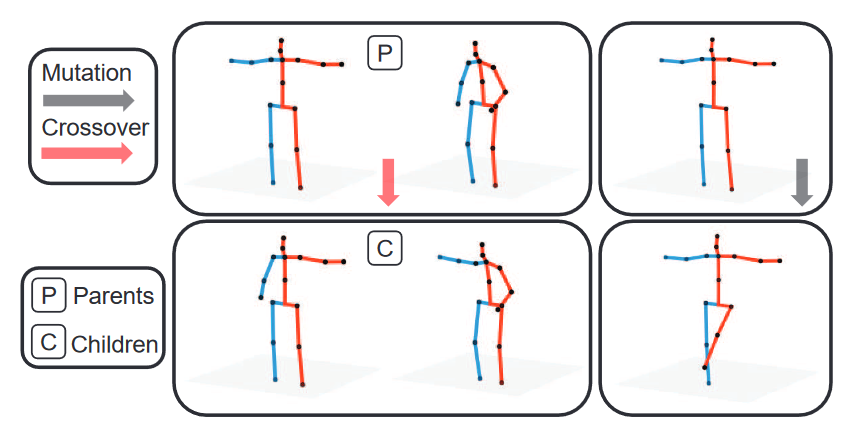
Cascaded Deep Monocular 3D Human Pose Estimation with Evolutionary Training Data
端到端深度表示学习对于单目3D人体姿态估计已经取得了显著的准确性,然而这些模型对于具有有限和固定训练数据的不可见姿态可能会失败。本文提出了一种新的数据增强方法,该方法:(1)可扩展,用于合成大量训练数据(超过800万个有效的3D人体姿态和相应的2D投影),用于训练2D到3D网络,(2)可以有效地减少数据集偏差。我们的方法进化了一个有限的数据集,以基于分层的人类表示和受先验知识启发的启发来合成看不见的3D人类骨骼。广泛的实验表明,我们的方法不仅在最大的公共基准上达到了最先进的精度,而且对看不见的和罕见的姿态的概括也明显更好。
应用进化算子的示例。交叉和突变分别取2个和1个随机样本合成新的人类骨骼。
级联3D姿态估计架构(TAG-Net)。顶部:我们的模型是一个两阶段模型,其中第一阶段是一个2D地标探测器,第二阶段是一种级联的3D坐标回归模型。底部:级联中的每个学习者都是一个前馈神经网络,其能力可以通过剩余块的数量来调整。为了拟合一个进化的数据集,我们为每个级联使用8个层(3个块),总共有24个层,级联有3个模型。
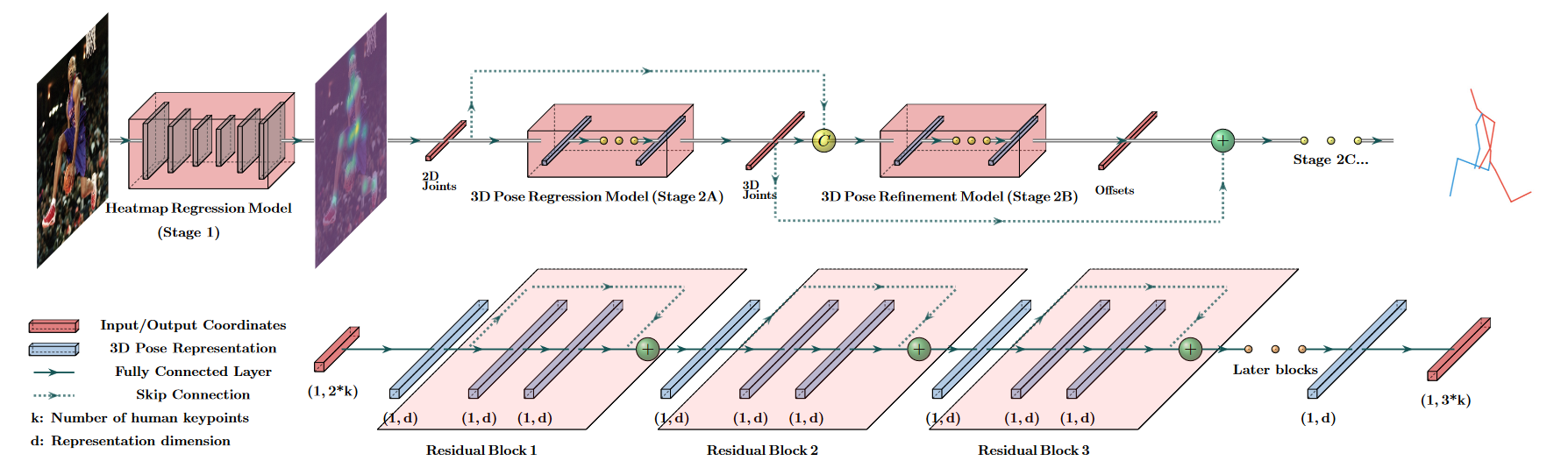
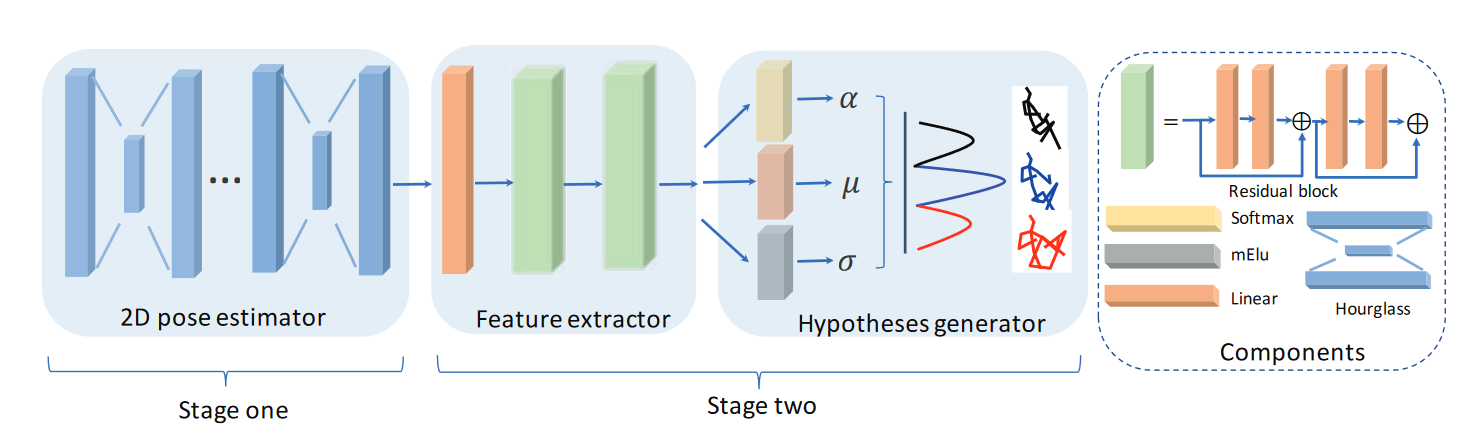
# Probabilistic MHPE(2021 ICCV)❤
Probabilistic monocular 3d human pose estimation with normalizing flows
由于深度模糊和遮挡,单目图像的3D人体姿态估计是一个高度不适定的问题。尽管如此,大多数现有的工作都忽略了这些歧义,只估计了一个单一的解决方案。相反,我们生成了一组不同的假设,这些假设代表了可行3D姿态的完全后验分布。为此,我们提出了一种基于标准化流的方法,该方法利用确定性三维到二维映射来解决二维到三维的模糊逆问题。 此外,通过将2D检测器的不确定性信息作为条件来有效地建模不确定性检测和遮挡。成功的另一个关键是事先学会的3D姿态和对best-of-M loss的概括。我们在两个基准数据集Human3.6M和MPI-INF-3DHP上评估了我们的方法,在大多数指标上优于所有可比方法。该实现在GitHub1上可用。
方法概述。我们使用由仿射耦合块[11]组成的归一化流来生成多个3D姿态假设。通过在3D姿态和2D姿态与潜在向量的连接之间构造双射,我们可以在训练期间利用3D到2D映射(前向路径)。模型在两个方向上都进行了优化,而在推断时,仅计算从2D到3D的路径(反向路径)。通过从已知分布重复采样潜在向量并计算逆路径,可以生成任意多个3D姿态假设。通过调节耦合块,以拟合高斯函数的形式结合2D检测器的不确定性信息。灰色框中显示了单个耦合块的结构。出于可视化目的,仅显示了耦合块的正向计算。
# CanonPose(2021 CVPR)
CanonPose: Self-supervised Monocular 3D Human Pose Estimation in the Wild
# GraphSH(2021 CVPR)
Graph Stacked Hourglass Networks for 3D Human Pose Estimation
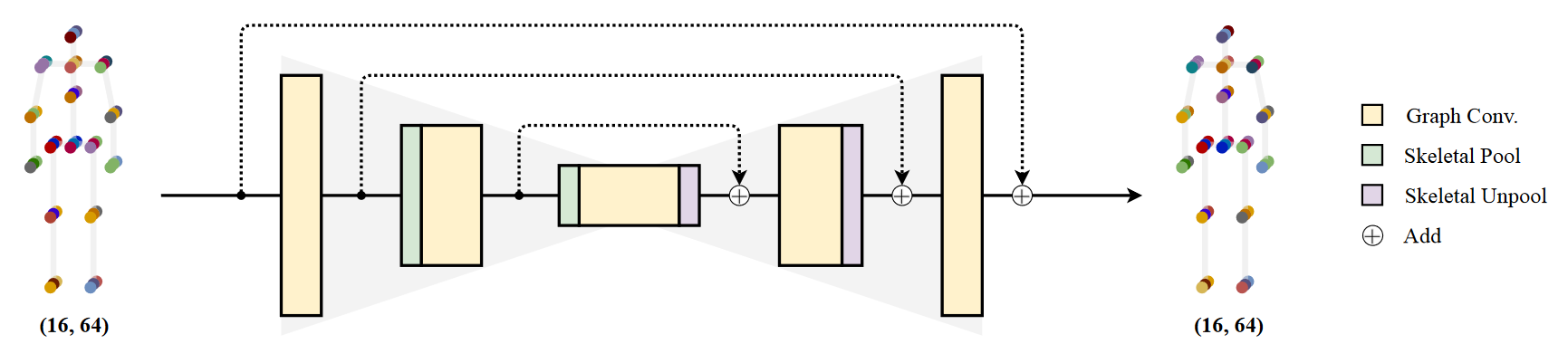
本文提出了一种新的图卷积网络结构——图堆积沙漏网络(Graph Stacked Hourglass Networks),用于二维到三维人体姿态估计任务。该架构由重复的编码器-解码器组成,其中图形结构特征在三种不同的人体骨骼表示尺度上进行处理。这种多尺度体系结构使模型能够学习局部和全局特征表示,这对于3D人体姿态估计至关重要。我们还介绍了一种使用不同深度中间特征的多级特征学习方法,并展示了利用多尺度、多级特征表示所带来的性能改进。为了验证我们的方法,进行了大量的实验,结果表明我们的模型优于最先进的模型。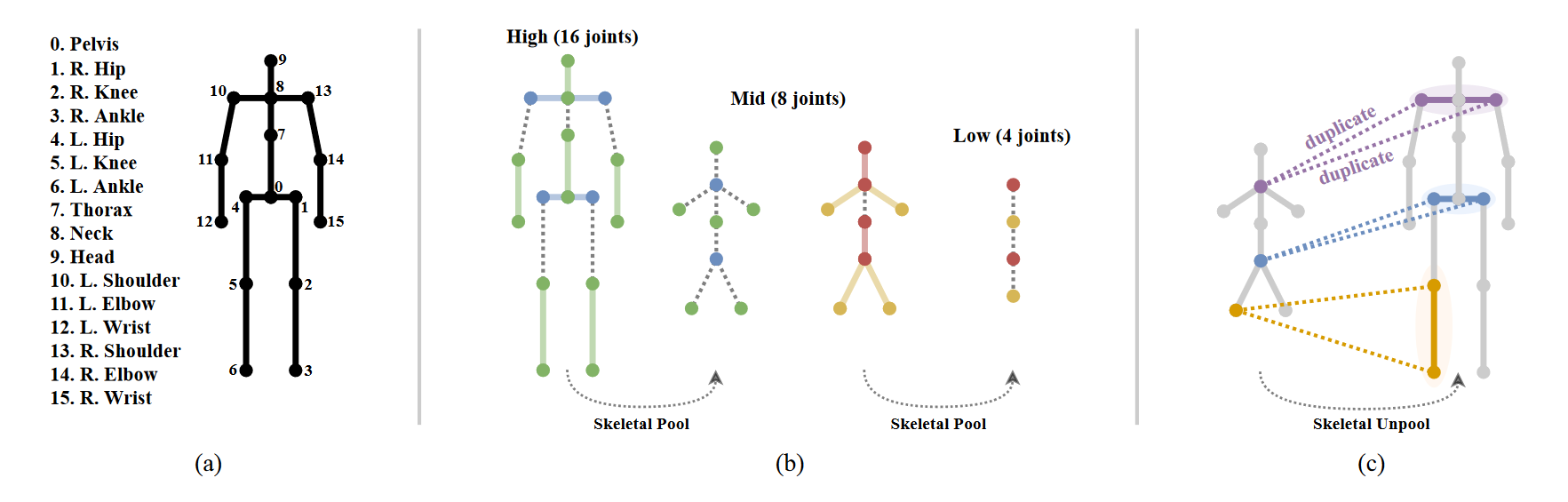 Graph Hourglass Module
Graph Hourglass Module
通过图形卷积和骨骼池减少骨骼尺度,达到最低尺度后通过骨骼非冷却进行上采样,最终恢复到原始骨骼尺度。随着骨骼鳞片的减少,我们增加了通道的数量(64→ 96→ 128(在我们的实验中)。每个图卷积层之后是批次标准化和ReLU激活。在每个比例的特征之间使用剩余连接。请注意,沙漏模块的输入和输出保持相同的形状。
总体架构
输入的2D关节在预处理的图形卷积层之后被送入沙漏模块,沙漏模块的输出既作为中间特征进行处理,也被送入后续的沙漏模块(最后一个除外)。将所有中间特征串联并输入SE块,然后将最终特征通过1x1卷积层输出最终3D姿态预测。卷积模块的编号表示输出的通道数。我们的网络采用4层方法。沙漏模块的输入和输出保持64通道的尺寸。请注意,图形结构在整个网络中保持不变。
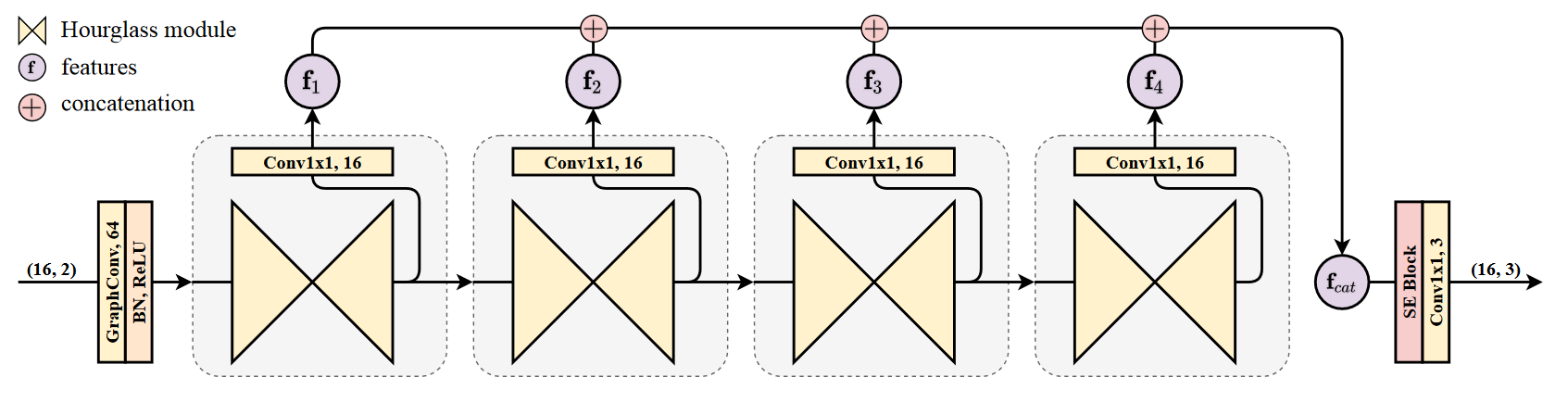
我们遵循挤压和激发块(SE块),以增强多级特征中的重要语义信息。SE块计算整个特征的信道权重,由于整个特征是由沿着信道轴的多级特征连接起来的,因此该块使模型能够在每个中间特征之间提取更有语义意义的特征表示。
结论
我们提出了一种新的二维到三维人体姿态估计体系结构,即图形堆积沙漏网络(GraphSH)。凭借我们独特的骨骼池和骨骼上采样方案,以及对图形结构数据具有强大的多尺度和多级特征提取能力的所提出的架构,我们的方法实现了优于最新技术的精确的2D-3D人体姿态估计。作为未来的工作,我们希望在我们的体系结构中引入时间多帧特性,以便进一步改进。
# PoseAug(2021 CVPR)
PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation
现有的3D人体姿态估计器对新数据集的泛化性能较差,这主要是由于训练数据中2D-3D姿态对的有限多样性。 为了解决这个问题,我们提出了PoseAug,这是一个新的自动增强框架,它学习如何增强可用的训练姿态,以获得更大的多样性,从而提高训练后的2D到3D姿态估计器的通用性。具体来说,PoseAug引入了一种新型的姿态增强器,它学习通过可微操作来调整姿态的各种几何因素(例如,姿态、身体大小、视点和位置)。利用这种可微容量,增强器可以与3D姿态估计器联合优化,并将估计误差作为反馈,以在线方式生成更多样和更难的姿态。 此外,PoseAug引入了一种新的部分感知运动链空间,用于评估局部关节角度合理性,并相应地开发了一个判别模块,以确保增强姿态的合理性。这些精心设计使得PoseAug能够生成比现有的离线增强方法更多样但更合理的姿态,从而更好地概括姿态估计器。PoseAug是通用的,易于应用于各种3D姿态估计器。大量实验表明,PoseAug在场景内和跨场景数据集上都有明显的改进。值得注意的是,在跨数据集评估设置下,它在MPI-INF-3DHP上实现了88.6%的3D PCK,比之前最好的基于数据增强的方法提高了9.1%。
PoseAug框架概述。增强子、估计器和鉴别器通过误差反馈训练策略进行端到端联合训练。因此,扩增器学习在估计器和鉴别器的指导下扩增数据。
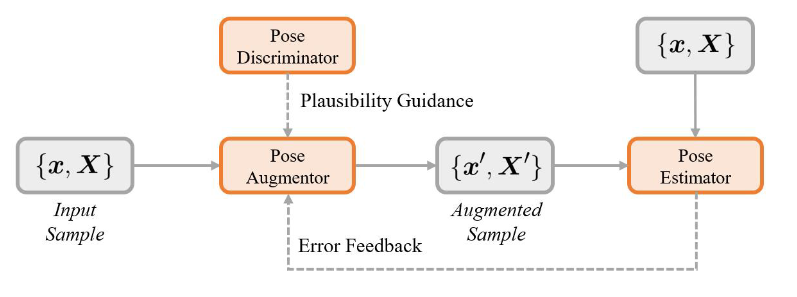
我们提出的框架旨在生成不同的训练数据,对姿态估计器有适当的困难,以提高模型泛化性能。因此,需要解决两个挑战:如何使增强数据多样化并有利于模型训练;以及如何使其自然和现实。 为了解决这些问题,我们提出了训练增强子的两个新想法。
用于在线姿态增强的误差反馈学习代替以离线方式执行随机姿态增强,所提出的姿态增强器A部署了可微分设计,该可微分设计使得能够与姿态估计器P进行在线联合训练。使用来自姿态估计员P的训练误差作为反馈,姿态增强器A学习生成最适合当前姿态估计器的姿态,由于在线增强,增强的姿态呈现出适当的困难和多样性,从而最大程度地有利于训练的3D姿态估计模型的泛化。
合理姿态增强的辨别学习纯粹追求误差最大化的增强可能会导致不合理的训练姿态,违反人体的生物力学结构,并可能损害模型性能。先前的增强方法主要依赖于用于确保合理性的预定义规则(例如,关节角度约束),然而,这将严重限制生成姿态的多样性。例如,一些更难但更合理的姿态可能无法通过基于规则的合理性检查,并且不会被用于模型训练。为了解决这个问题,我们在身体关节的局部关系上部署了一个姿态鉴别器模块,以帮助训练增强器,从而确保增强姿态的合理性,而不牺牲多样性。
# GraphMDN(2021 IJCNN)
GraphMDN: Leveraging graph structure and deep learning to solve inverse problems
# ModulatedGCN(2021 ICCV)
Modulated Graph Convolutional Network for 3D Human Pose Estimation
最近,图卷积网络(GCN)通过对人体各部位之间的关系建模,在三维人体姿态估计(HPE)方面取得了良好的性能。然而,大多数先前的GCN方法都有两个主要缺点。首先,它们为图卷积层中的每个节点共享一个特征变换。这会阻止他们学习不同身体关节之间的不同关系。第二,图形通常是根据人体骨骼定义的,是次优的,因为人类活动通常表现出超出人体关节自然连接的运动模式。
为了解决这些限制,我们为3D HPE引入了一种新型的调制GCN。它由两个主要部分组成:权重调制和亲和力调制。权重调制学习不同节点的不同调制向量,以便在保持较小模型尺寸的同时,分离不同节点的特征变换。亲和力调制调整GCN中的图形结构,以便它可以对人体骨架之外的其他边建模。我们研究了几种亲和力调制方法以及正则化的影响。严格的烧蚀研究表明,这两种调制方式都可以提高性能,但开销可以忽略不计。与用于3D HPE的最先进GCN相比,我们的方法要么显著减少了估计误差,例如大约10%,同时保留了较小的模型尺寸,要么大幅减少了模型尺寸,例如从4.22M减少到0.29M(减少14.5倍),同时实现了可比性能。两个基准测试的结果表明,我们的调制GCN优于一些最新技术。
Weight Modulation
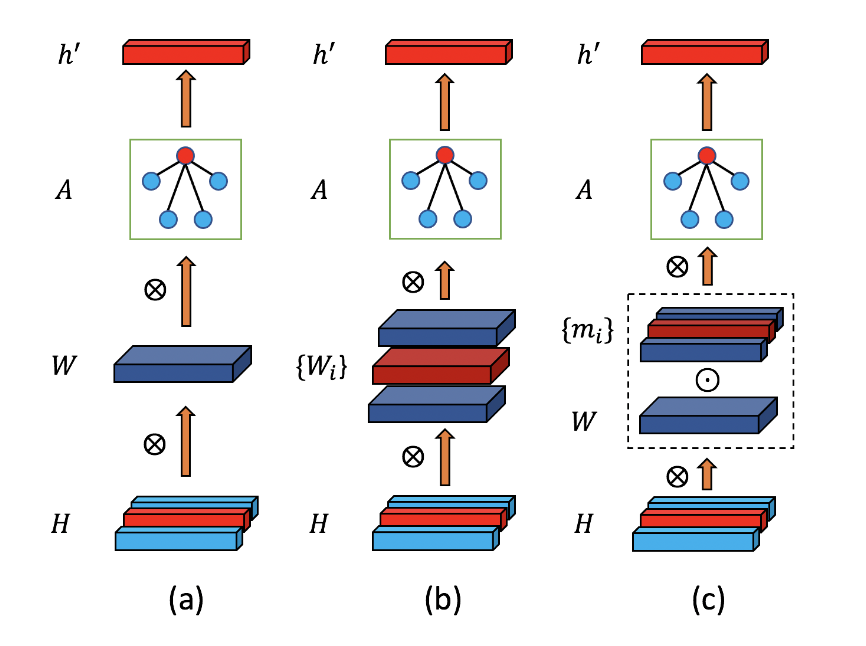
Affinity Modulation
三种亲和力调制

过多的自由度会导致过拟合,并损害GCN的泛化能力。通过探索不同正则化对亲和力调制的影响,对这一潜在问题进行了深入研究。具体来说,考虑三种正则化类型:对称、低秩和稀疏。
结论
通过广泛的烧蚀研究和基准实验,我们得出以下结论。(1) 权重调制可以解决不同节点共享特征变换带来的限制,同时保持较小的大小。(2) 亲和力调制对于良好的性能是必要的。骨架优先和学习骨架以外边缘的能力对于亲和力调制都很重要。(3) 具有无约束调制矩阵的亲和调制不会导致严重的泛化问题。只有对称正则化才能提高其性能。(4) 调制GCN集成了权重调制和亲和调制,在所有GCN方法中实现了性能和模型大小之间的最佳平衡。(5) 调制GCN在两个基准数据集上的表现优于一些最新技术。
# Jointformer (2022 ICPR)
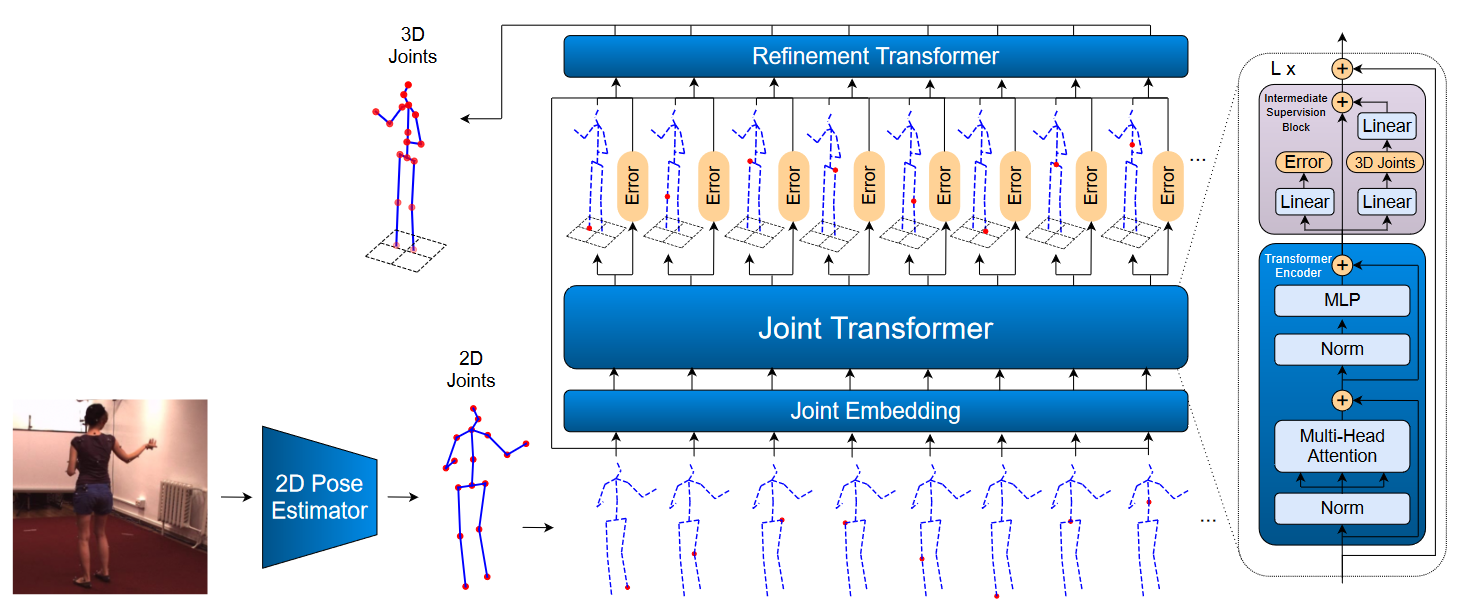
Jointformer: Single-Frame Lifting Transformer with Error Prediction and Refinement for 3D Human Pose Estimation
单目三维人体姿态估计技术有潜力极大地提高人体运动数据的可用性。单图像2D-3D提升的最佳模型使用图卷积网络(GCN),通常需要一些手动输入来定义不同身体关节之间的关系。我们提出了一种基于Transformer的新方法,该方法使用更通用的自我注意机制来学习代表关节的标记序列中的这些关系。我们发现,使用中间监控以及堆叠编码器之间的剩余连接有利于性能。我们还建议将错误预测作为多任务学习框架的一部分,通过允许网络补偿其置信水平来提高性能。我们进行了广泛的消融研究,以表明我们的每一项贡献都提高了性能。此外,我们还表明,在单帧3D人体姿态估计方面,我们的方法大大优于当前的技术水平。
按照之前的2D3D姿态提升方法,我们使用现成的模型从图像中生成2D姿态,并使用这些预测来估计相应的3D姿态。3D姿态在相机坐标中估计,并以骨盆关节为中心。虽然大多数以前的最先进技术都使用多层感知器(MLP)或GCNs,但我们使用Transformer分两部分预测和优化3D姿态。首先,我们的 Joint Transformer从单个帧的2D姿态估计3D姿态和预测误差。之后,我们的Refinement Transformer通过使用中间预测和预测误差进一步改进了这种预测。
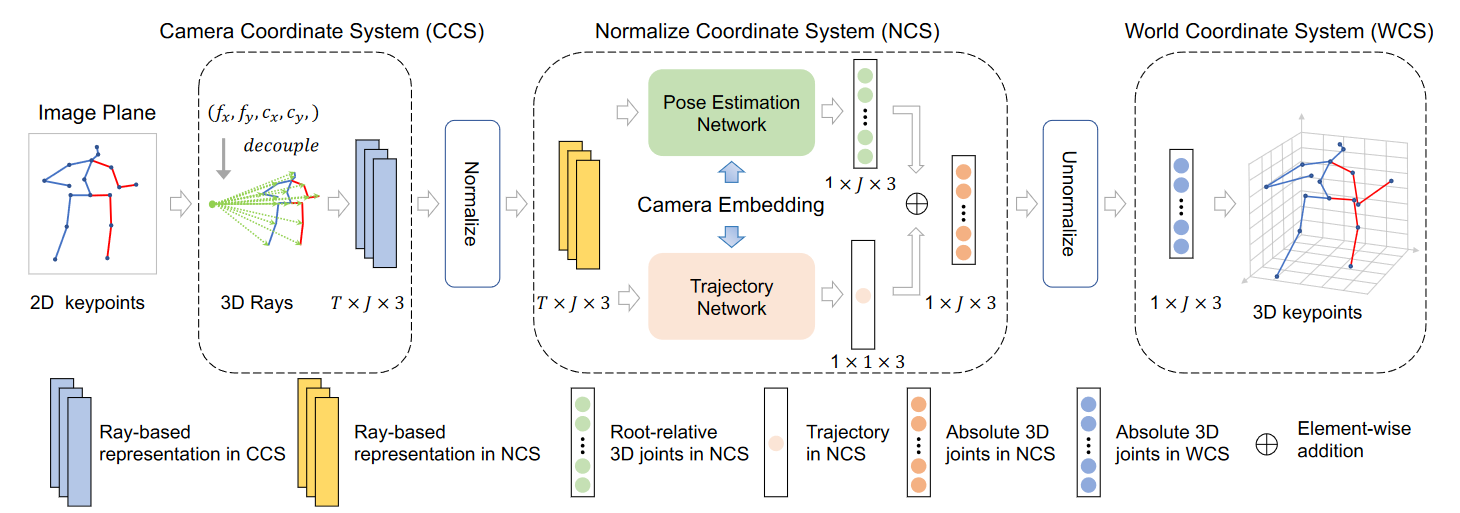
# Ray3D(2022 CVPR)use sequence
Ray3D: ray-based 3D human pose estimation for monocular absolute 3D localization
本文提出了一种新颖的单目绝对三维人体姿态估计方法Ray3D。这种方法通过一系列新颖的设计逐渐解决了固有的模糊性:从2D关键点转换为3D标准化光线;三维射线的时间融合;包括摄像机嵌入。因此,Ray3D在三个实际基准和一个合成基准上显著优于SOTA方法。
3D世界中的相机姿态可以由其3D位置、俯仰、偏航和滚动角度确定。俯仰θ表示相机光轴与地平面之间的角度。假设相机的偏航和侧滚值接近0,则相机的俯仰值和相机高度可以唯一指定相机的姿态,直到水平平移。
我们的Ray3D方法在三个真实基准和合成数据集的泛化性方面明显优于基线方法。这清楚地表明了Ray3D方法的鲁棒性。然而,当人体尺寸变化很大时,Ray3D的性能会下降。这主要是因为所有的训练身体姿态都是成人的。同时,我们的方法假设主体位于地平面上。如果受试者长时间离开地面(例如爬梯子),该模型可能会失败。此外,需要提供校准的摄像机参数,这限制了Ray3D的使用情况。
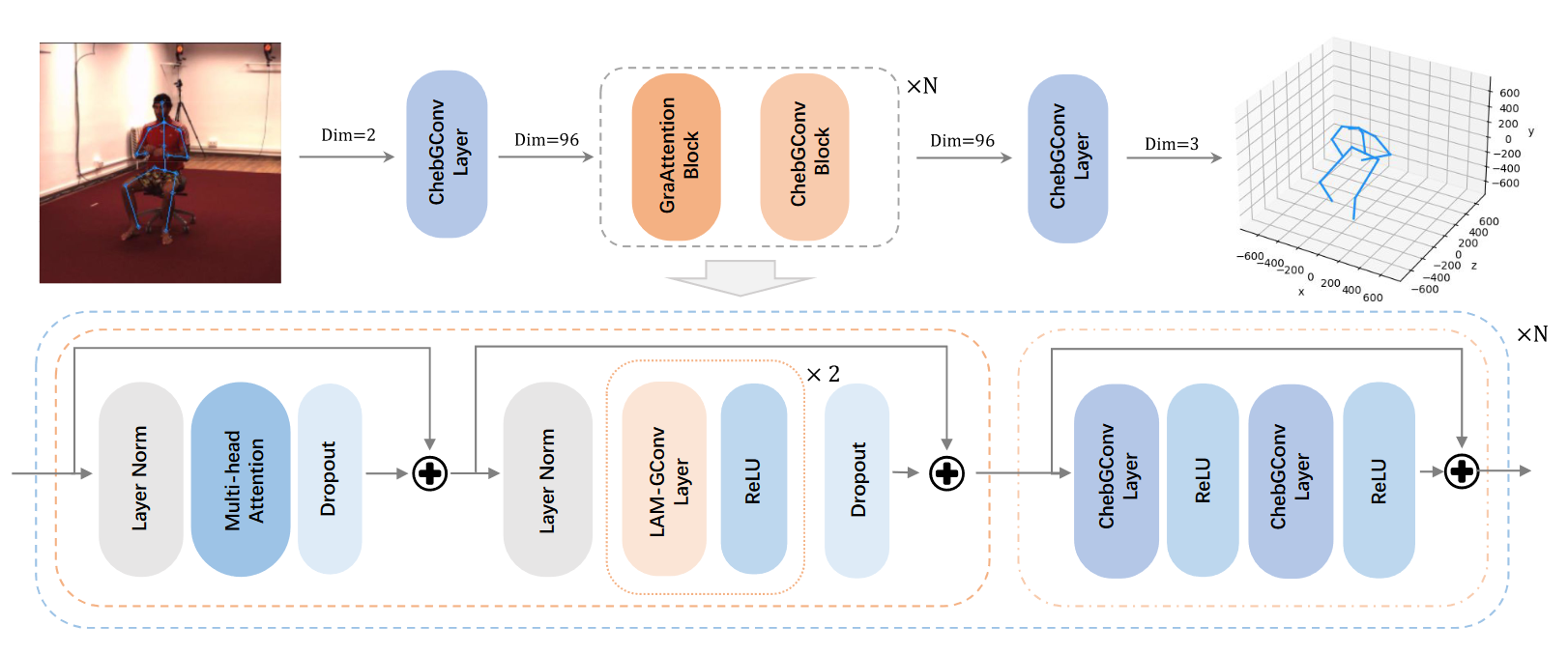
# GraFormer(2022 CVPR)
GraFormer: Graph-oriented Transformer for 3D Pose Estimation
在二维到三维的位姿估计中,利用二维关节的空间约束是很重要的,但它还没有很好的建模。为了更好地模拟关节的关系进行三维位置估计,我们提出了一个有效而简单的网络,称为GraFormer,其中一种新的Transformer的架构设计,通过嵌入图卷积层后多头注意块。建议的GraFormer是通过重复堆叠GraAttention块和ChebGConv块构建的。所提出的GraAttention块是一个新的Transformer块设计用于处理图结构的数据,它能够学习更好的特征,通过捕获全局信息的所有节点以及明确的邻接结构的节点。为了模拟非相邻节点之间的隐式高阶连接关系,引入了ChebGConv块来交换非相邻节点之间的信息,以获得更大的感受野。
# Decanus to Legatus(2022 ACCV zero-shot)
Decanus to Legatus: Synthetic training for 2D-3D human pose lifting
# ElePose(2022 CVPR)
ElePose: Unsupervised 3D Human Pose Estimation by Predicting Camera Elevation and Learning Normalizing Flows on 2D Poses
# MöbiusGCN(2022 ECCV)
3D Human Pose Estimation Using Möbius Graph Convolutional Networks
三维人体姿态估计是理解人类行为的基础。最近,图形卷积网络(GCN)取得了令人满意的结果,它实现了最先进的性能并提供了相当轻的架构。然而,GCN的一个主要限制是它们不能显式编码关节之间的所有转换。为了解决这个问题,我们提出了一种使用Möbius变换(MöbiusGCN)的新的光谱GCN。特别是,这允许我们直接和显式地编码关节之间的变换,从而产生更紧凑的表示。与迄今为止最轻的架构相比,我们的新方法需要的参数减少了90–98%,即我们最轻的MöbiusGCN仅使用0.042M可训练参数。 除了大幅减少参数外,显式编码关节变换也使我们能够获得最先进的结果。我们在两个具有挑战性的姿态估计基准Human3.6M和MPI-INF-3DHP上评估了我们的方法,展示了最先进的结果和MöbiusGCN的泛化能力
# AdaptPose(2022 CVPR)
AdaptPose: Cross-Dataset Adaptation for 3D Human Pose Estimation by Learnable Motion Generation
# DiffuPose(2023)
DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model
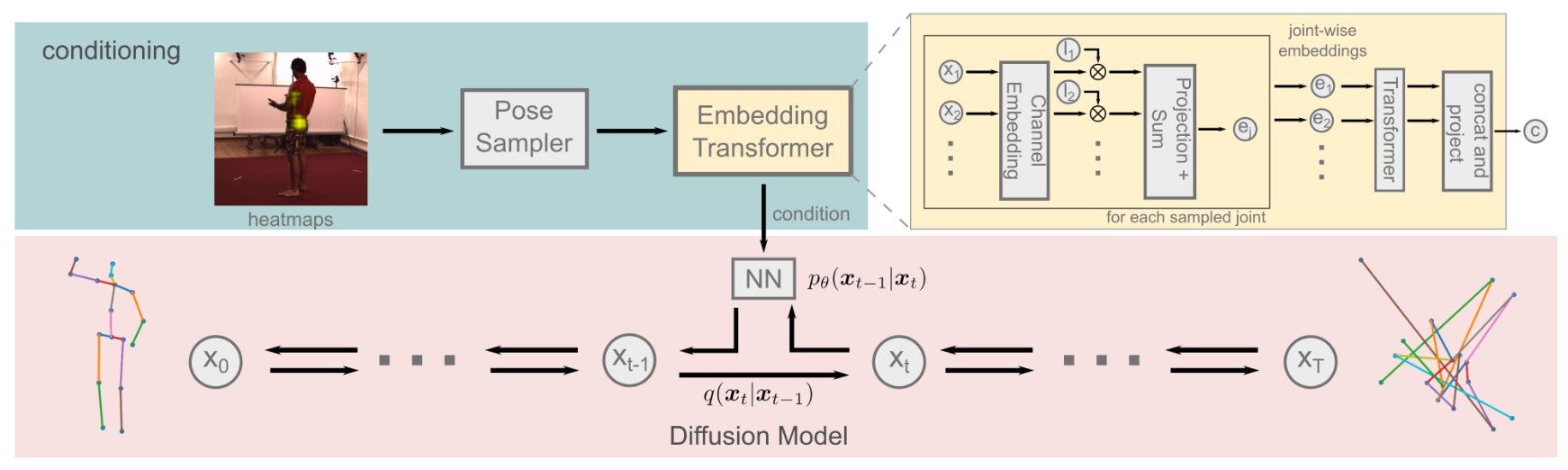
# DiffPose(2023)
DiffPose: Multi-hypothesis Human Pose Estimation using Diffusion Models
传统上,单眼3D人体姿态估计采用机器学习模型来预测给定输入图像的最可能的3D姿态。然而,单个图像可能是高度模糊的,并导致2D-3D提升步骤的多个可能的解决方案,这导致过度自信的3D姿态预测。为此,我们提出了DiffPose,一种条件扩散模型,它预测给定输入图像的多个假设。与类似方法相比,我们的扩散模型是直接的,避免了密集的超参数调谐、复杂的网络结构、模式崩溃和不稳定训练。此外,我们解决了一个常见的两步方法的问题,该方法首先通过关节热图估计2D关节位置的分布,并基于第一或第二矩统计连续地近似它们。由于热图的这种简化去除了关于可能正确但被标记为不可能的关节位置的有效信息,我们建议将热图表示为一组2D关节候选样本(使用热图中的完整2D输入信息)。为了从这些样本中提取关于原始分布的信息,我们引入了我们的嵌入变换器,该变换器调节扩散模型。在实验上,我们发现DiffPose略微改进了简单姿态的多假设姿态估计的技术水平,并在高度模糊的姿态下效果更好。
# POT-UGRN(2023 AAAI)
Pose-Oriented Transformer with Uncertainty-Guided Refinement for 2D-to-3D Human Pose Estimation
# HTNET(2023 ICASSP)
HTNET: HUMAN TOPOLOGY AWARE NETWORK FOR 3D HUMAN POSE ESTIMATION
# HopFIR(2023)
HopFIR: Hop-wise GraphFormer with Intragroup Joint Refinement for 3D Human Pose Estimation
# GFPose(2023 CVPR)
GFPose: Learning Gradient Field for Multi-Hypothesis 3D Human Pose Estimation
# Regular Splitting Graph Network for 3D Human Pose Estimation(2023 TIP)
# AMPose(2023 ICASSP)
AMPose: Alternatively Mixed Global-Local Attention Model for 3D Human Pose Estimation
# IGANet(2023 ICASSP)
Interweaved Graph and Attention Network for 3D Human Pose Estimation
# 基于序列
# Exploiting temporal information for 3D human(2018 ECCV)
在这项工作中,我们解决了从一系列2D人体姿态估计3D人体姿态的问题。尽管深网络最近的成功导致了许多用于3D姿态估计的最先进方法,以端到端训练深网络,表现最好的方法已经证明了将3D姿态估计任务划分为两个步骤的有效性:使用最先进的2D姿态估计器从图像中估计2D姿态,然后将其映射到3D空间。他们还表明,像一组关节的2D位置这样的低维表示可以具有足够的辨别能力,以高精度估计3D姿态。然而,由于每个帧中的独立误差导致抖动,单个帧的3D姿态估计导致时间上的不相干估计。因此,在本工作中,我们利用2D关节位置序列的时间信息来估计3D姿态序列。我们设计了一个由层归一化LSTM单元组成的序列到序列网络,该单元具有将输入连接到解码器侧输出的快捷连接,并在训练期间施加时间平滑性约束。 我们发现,时间一致性的知识将Human3.6M数据集的最佳报告结果提高了约12.2%,并有助于我们的网络在一系列图像上恢复时间一致的3D姿态,即使2D姿态检测器出现故障。
模型结构
这是一个在解码器侧具有剩余连接的序列对序列网络。编码器在其最终隐藏状态下对长度为t的2D姿态序列的信息进行编码。编码器的最终隐藏状态用于初始化解码器的隐藏状态。〈ST ART〉符号告诉解码器从编码器的最后一个隐藏状态开始预测3D姿态。解码器基本上学习在给定时间(t-1)的3D姿态的情况下预测时间t的3D姿态。 剩余连接有助于解码器从上一时间步学习扰动。

损失函数
损失函数给定2D关节位置序列作为输入,我们的网络预测相对于根节点(中心髋关节)的3D关节位置序列。我们在相机坐标空间中预测每个3D姿态,而不是像Martinez等人所建议的那样在任意全局帧中预测它们。我们对预测的3D关节位置施加时间平滑度约束,以确保一帧中每个关节的预测与其前一帧的预测相差不大。
由于2D姿态检测器在单个帧上工作,即使图像中对象的运动最小,连续帧的检测可能会有所不同,特别是对于运动速度快或易于遮挡的关节。因此,我们假设在帧速率足够高的情况下,对象在连续帧中不会移动太多。因此,我们在训练期间将3D关节位置的一阶导数相对于时间的L2范数添加到我们的损失函数中。该约束有助于我们可靠地估计3D姿态,即使2D姿态检测器在时间窗口内的几帧内失败。
经验上,我们发现,与其他关节相比,某些关节更难准确估计,例如手腕、脚踝、肘部。为了解决这个问题,我们根据关节对整体误差的贡献,将关节划分为躯干-头部、四肢-腿部和四肢-手臂三个不相交的集合。 我们观察到,与属于肢体的关节相比,连接到躯干和头部的关节(如臀部、肩部、颈部)的预测精度始终很高,因此将其放在设定的躯干头部中。四肢的关节,尤其是手臂上的关节,由于其运动范围大和闭塞,通常更难预测。我们把膝盖和脚踝放在固定的肢体腿上,肘部和手腕放在肢体臂上。我们将每组关节的导数乘以不同标量值,基于它们对总误差的贡献。
因此,我们的损失函数由两个独立项之和组成:N个不同的3D关节位置序列的均方误差(MSE);以及3D关节位置的N个序列相对于时间的一阶导数的L2范数的平均值,其中关节被划分为三个不相交集合。
η、ρ和τ是标量超参数,用于控制三组关节中每个关节的3D位置导数的重要性。将更高的权重分配给通常以更高的误差预测的关节组。
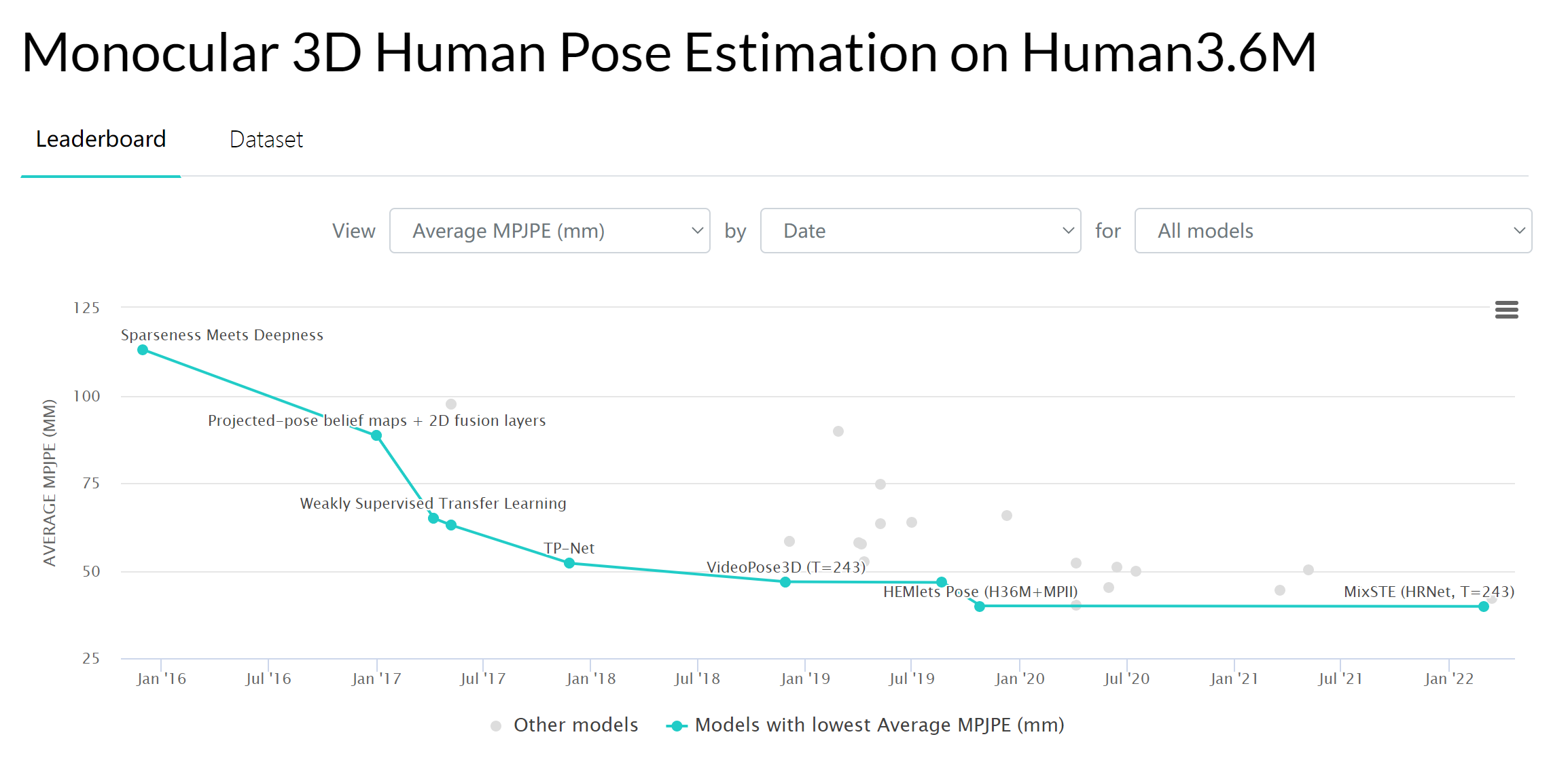
# VideoPose3D(2019 CVPR)
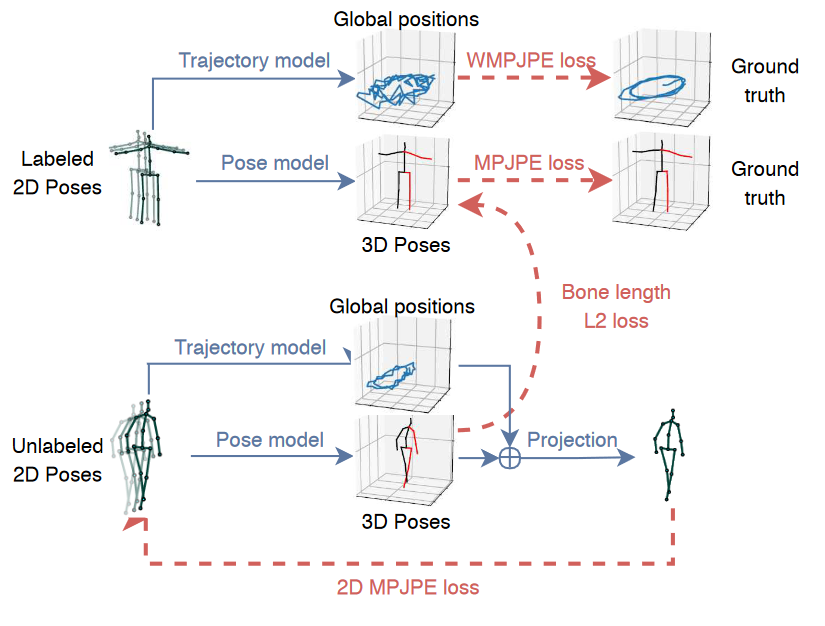
3D human pose estimation in video with temporal convolutions and semi-supervised training
本文提供了两个主要贡献。首先,我们提出了一种基于2D关键点轨迹上的扩展时间卷积的视频中3D人体姿态估计的简单有效方法。我们表明,在相同的精度水平上,我们的模型比基于RNN的模型更有效,无论是在计算复杂度还是模型参数的数量方面。其次,我们引入了一种半监督方法,该方法利用未标记的视频,并且在标记数据稀少时有效。具体来说,我们使用现成的2D关键点检测器预测未标记视频的2D重点,预测3D姿态,然后将其映射回2D空间。与以前的半监督方法相比,我们只需要相机内部参数,而不需要地面真实2D注释或具有外部相机参数的多视图图像。与现有技术相比,我们的方法在监督和半监督环境中都优于先前表现最佳的方法。我们的监督模型比其他模型表现更好,即使这些模型利用额外的标记数据进行训练。(Human3.6M与HumanEva-I实验数据集)
我时间卷积模型将2D关键点序列(底部)作为输入,并生成3D姿态估计作为输出(顶部)。我们使用扩张的时间卷积来捕获长期信息。
全卷积3D姿态估计架构。输入由243帧(B=4个块)的记录场的2D关键点组成,J=17个关节。卷积层为绿色,其中2J、3d1、1024表示2·J输入通道,大小为3的内核具有扩展1,1024个输出通道。我们还在括号中显示了样本1帧预测的张量大小,其中(243,34)表示243帧和34个通道。

使用3D姿态模型进行半监督训练,该3D姿态模型将可能预测的2D姿态序列作为输入。我们对人的3D轨迹进行回归,并添加一个软约束,以将未标记预测的平均骨骼长度与标记预测的骨骼长度相匹配。一切都是联合训练的。由于如果受试者离相机更远,回归精确轨迹变得越来越困难,我们优化了轨迹的加权平均每个关节位置误差(WMPJPE)损失函数:WMPJPE代表“加权MPJPE”。
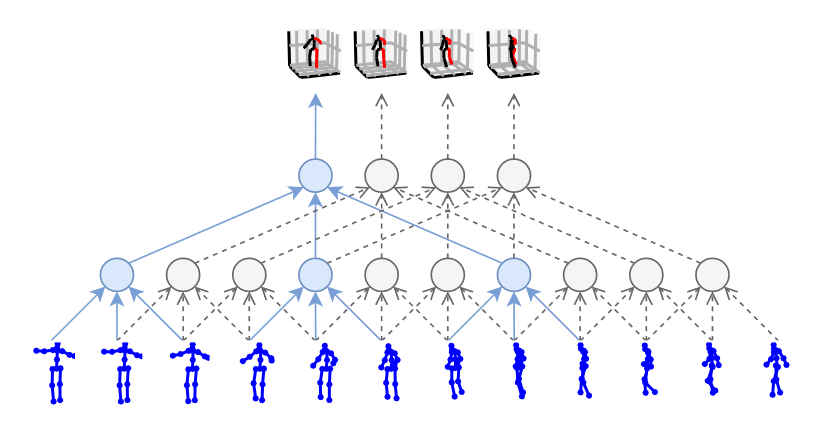
# STRGCN(2019 ICCV)
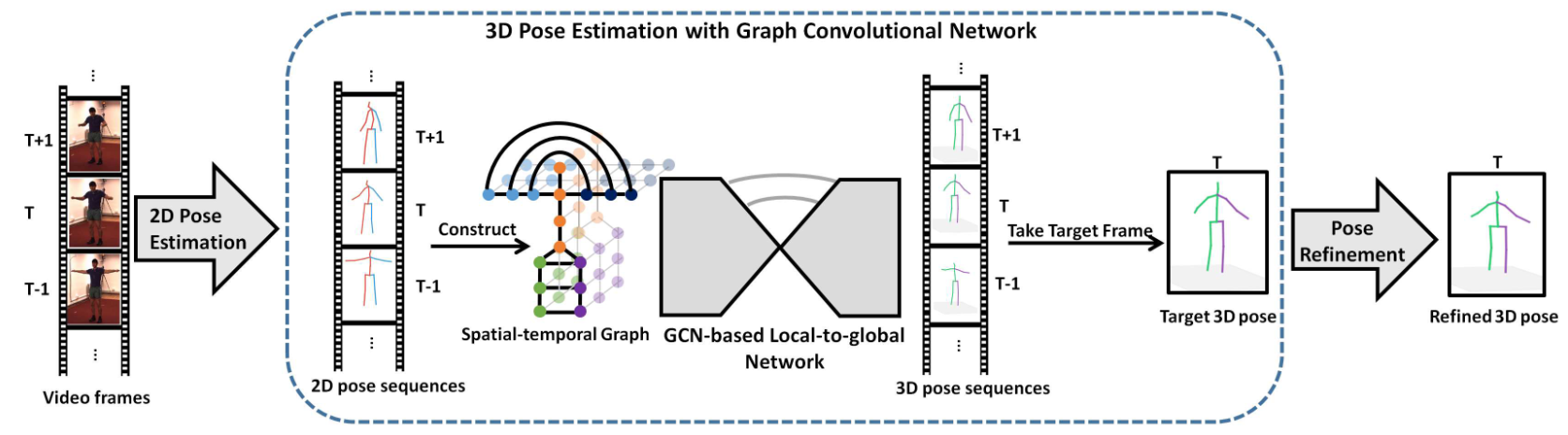
Exploiting Spatial-Temporal Relationships for 3D Pose Estimation via Graph Convolutional Networks
尽管在单视图图像或视频的三维姿态估计方面取得了很大进展,但由于深度模糊和严重的自遮挡,这仍然是一项具有挑战性的任务。为了有效地结合空间相关性和时间一致性来缓解这些问题,我们提出了一种新的基于图形的方法来解决从短序列的2D关节检测中进行3D人体和3D手姿态估计的问题。特别是,关于人手(身体)配置的领域知识被明确地纳入到图形卷积运算中,以满足3D姿态估计的特定需求。此外,我们引入了一种局部到全局的网络体系结构,它能够学习基于图的表示的多尺度特征。 我们在具有挑战性的基准数据集上评估了所提出的方法,用于3D手姿态估计和3D身体姿态估计。实验结果表明,我们的方法在两个任务上都达到了最先进的性能。
我们提出的基于连续2D姿态的3D姿态估计网络架构的示意图概述。输入是根据RGB图像估计的少量相邻2D姿态,输出是目标帧的3D关节位置。我们在骨架序列上构建了一个时空图,并设计了一个具有图卷积操作的分层“局部到全局”体系结构,以有效地处理和整合跨尺度的特征。为了进一步细化估计结果,应用了一个姿态细化过程,可以使用图卷积网络进行端到端的训练。请注意,该管道适用于3D人体和手的姿态估计,这里我们简单地以3D人体姿态估计为可视化示例。
A non-uniform graph convolutonal operation
在现有的图卷积中,基本上每个内核θ都由所有1跳相邻节点共享。这对稠密图很有用。然而,我们用于三维姿态估计的时空图是稀疏的,具有功能变化的图边(例如,表示不同相关性的空间边和时间边),因此不适合对相邻节点进行统一处理。
为了解决这个问题,受先前研究的启发,我对一般图的卷积运算进行了修改,这些研究采用了更大的核尺寸的卷积算子。特别是,我们根据相邻节点的语义进行分类,并对不同的相邻节点使用不同的核。如下图所示,根据直观的解释,相邻节点分为六类:1)中心节点本身;2) 物理连接的相邻节点,其比中心节点更靠近根节点;3) 物理连接的相邻节点,其距离根节点比中心节点远;4) 间接的“对称相关”相邻节点;5) 前向时间相邻节点;和6)向后时间相邻节点。
(a)人体和(b)人手的不同相邻节点的可视化。相邻节点根据其语义分为六类:中心节点(蓝色)、物理连接的节点,包括距离骨架根较近(紫色)和较远(绿色)的节点、间接“对称”相关节点(深蓝色)、向前时间节点(黄色)和向后时间节点(橙色)。

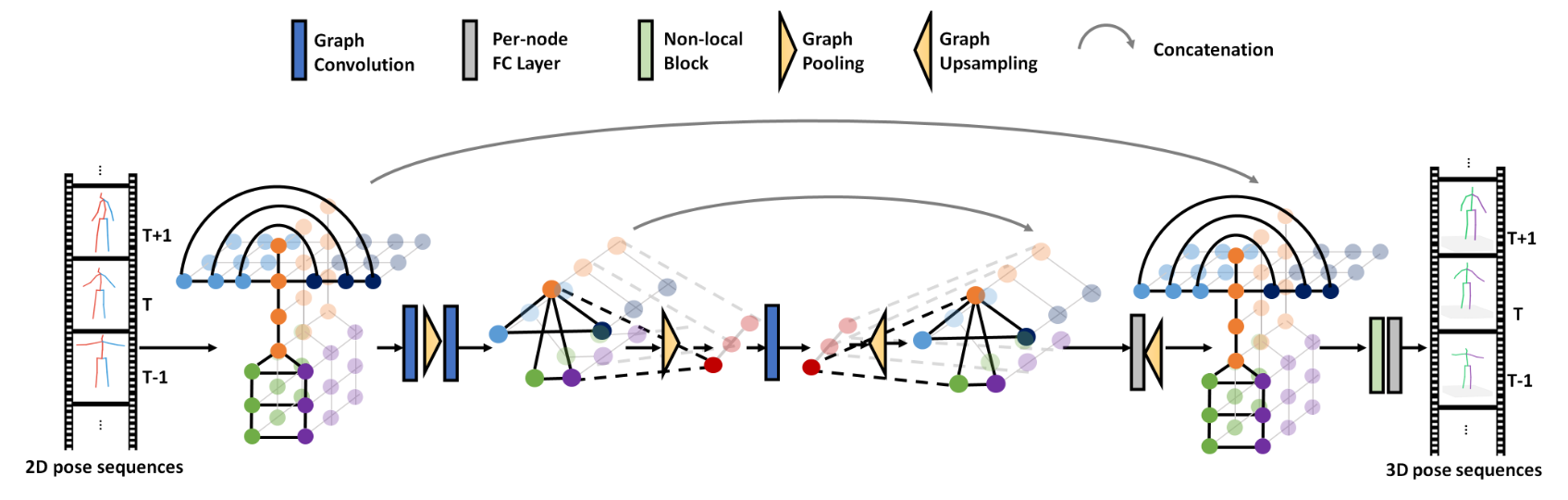
GCN-based Local-to-global Prediction
下图显示了所提出的分层“本地到全局”网络,它可以有效地处理和合并跨尺度的特征。在早期阶段,我们逐步执行图卷积和池操作,从原始比例到非常低的分辨率。此后,网络通过一系列上采样和跨尺度特征组合进行自上而下的过程。为了同时利用自下而上和自上而下的特性,我们对具有相同比例的特性执行元素级连接,然后按节点FC层更新组合的特性。此外,在生成3D姿态序列之前引入了一个非局部块(non-local block),以便于对全身进行整体处理。
上采样过程只是采取了与图池过程相反的步骤,其中较粗图中顶点的特征被复制到较细尺度的相应子顶点。
Pose Refinement
对于三维姿态估计任务,有两种广泛使用的三维姿态表示。第一种方法使用相机坐标系中关节的根相关3D坐标,而第二种方法涉及连接每个关节的预测深度和从2D探测器提取的UV坐标。这两种表示可以使用相机固有矩阵轻松地从一种转换为另一种。
对于相对精确的2D姿态,首选第二种表示法,因为它可以保证预测的3D姿态和图像平面上的2D投影之间的一致性。然而,对于较差的2D姿态,保持投影和3D姿态之间的一致性通常会导致物理无效的3D姿态结构;这里,第一种表示更好,因为它更能生成有效的3D姿态结构。为了在这两种情况之间取得平衡,我们设计了一个简单的两层全连接网络来进行姿态优化,该网络将两种表示中的3D姿态估计结果(其中第二种表示的深度值直接从第一种表示中计算)作为输入,并输出两组结果的置信值。最后,将优化后的三维关节位置计算为两组估计结果的置信加权和。
# Spatio-Temporal Network(2020 AAAI)
3D Human Pose Estimation using Spatio-Temporal Networks with Explicit Occlusion Training
尽管近年来取得了重大进展,但从单眼视频中估计3D姿态仍然是一项具有挑战性的任务。通常,当目标人物太小/太大,或者运动相对于训练数据的规模和速度太快/太慢时,现有方法的性能会下降。此外,据我们所知,这些方法中的许多都没有在严重遮挡情况下明确设计或训练,从而影响了它们处理遮挡的性能。 为了解决这些问题,我们引入了一种用于鲁棒三维人体姿态估计的时空网络。由于视频中的人类可能以不同的尺度出现并具有不同的运动速度,我们在每个单独的帧中应用多尺度空间特征来预测2D关节或关键点,并使用多步长时间卷积网络(TCN)来估计3D关节或关键点。此外,我们设计了基于身体结构和肢体运动的时空鉴别器,以评估预测的姿态是否形成有效的姿态和有效的运动。在训练过程中,我们明确地屏蔽了一些关键点,以模拟各种遮挡情况,从轻微到严重遮挡,这样我们的网络可以更好地学习,并对不同程度的遮挡变得鲁棒。由于3D地面实况数据有限,我们进一步利用2D视频数据为网络注入半监督学习能力。在公共数据集上的实验验证了我们方法的有效性,我们的消融研究显示了我们网络各个子模块的优势。
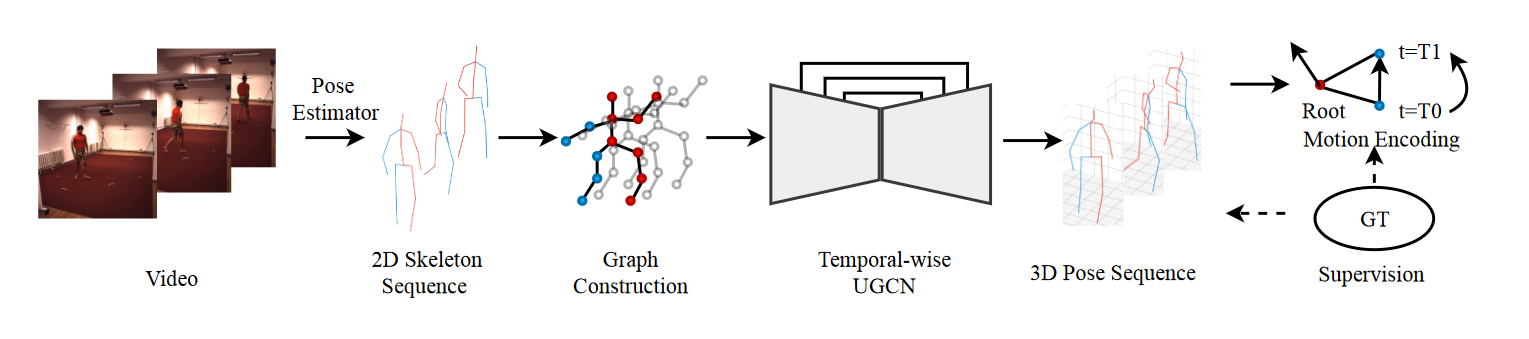
# UGCN(2020 ECCV)
Motion Guided 3D Pose Estimation from Videos
ST-GCN
我们提出了一种新的损失函数,称为运动损失,用于监控视频中单目3D人体姿态估计的模型。它通过将预测的运动模式与地面真实关键点轨迹进行比较来工作。在计算运动损失时,我们引入了成对运动编码,这是一种简单而有效的关键点运动表示。
我们设计了一种新的图卷积网络结构,U-shaped GCN(UGCN)。它捕获了短期和长期运动信息,以充分利用运动损失的监控。我们在两个大规模基准测试上实验了使用运动损失训练UGCN:Human3.6M和MPI-INF-3DHP。
运动损失函数出发点
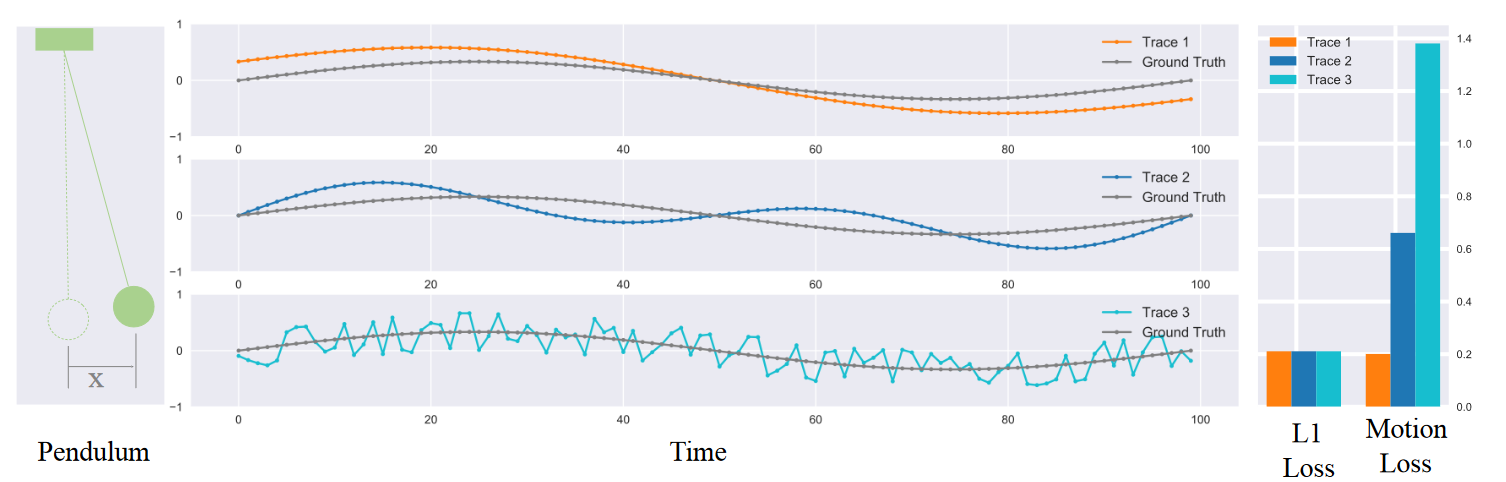
在大多数现有的工作中,监督3D姿态估计模型的常见损失函数是Minkowski Distance,例如1-loss和2-loss。它独立计算3D空间中预测关键点相对于地面真实位置的总体位置误差。然而,Minkowski距离有一个关键限制。它没有考虑估计姿态序列和地面真实之间的时间结构相似性。
我们通过一个玩具样品来说明这个问题,即摆运动的轨迹估计。它类似于姿态估计,但只包括一个“关节”。我们在图1中比较了摆运动的三个估计轨迹。第一个轨迹函数的形状类似于基本事实。第二种趋势不同,但仍保持平稳。最后一条曲线只是围绕地面真相随机波动。它们与地面真相的平均距离相同,但具有不同的时间结构。由于Minkowski距离是针对每个时刻独立计算的,因此它无法检查轨迹的内部相关性。
姿态序列中的关键点描述了人类的运动,尤其是在时间上,这些关键点之间有很强的相关性。在Minkowski距离作为损失的监督下,与上述玩具样本一样,模型很难从地面真实关键点轨迹中的运动信息中学习,因此由于高维解空间,很难在模型的预测中获得自然关键点运动。我们通过提出运动损失来解决这个问题,这是一个新的损失函数,它明确地将运动建模纳入到学习中。运动损失的工作原理是,除了重建关键点的3D位置外,还需要模型重建关键点运动轨迹。
概述我们提出的从连续2D姿态估计3D姿态的管道。我们通过时空图构建2D骨架,并通过U形图卷积网络(UGCN)预测3D位置。该模型在运动编码空间中进行监督。
Motion Loss
运动损失。通过将不同时间间隔的同一关节坐标向量之间的两两叉积向量串联起来,构造了姿态序列的多尺度运动编码。运动损失需要模型重建此编码。它明确地涉及到学习中的运动建模。

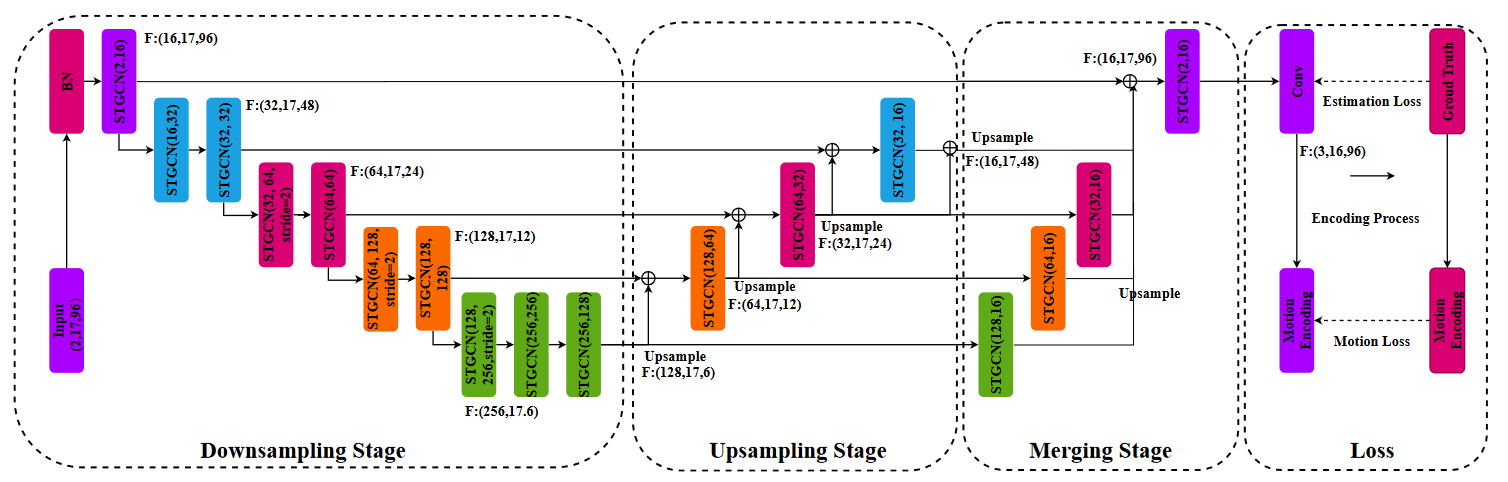
U-shaped Graph Convolutional Networks
我们提出了一种U形图卷积网络(UGCN)作为姿态估计模型的主干,以高分辨率融合局部和全局信息。该网络由三个阶段组成:下采样、上采样和合并。网络首先通过下采样阶段的临时池操作聚合远程信息。然后通过上采样层恢复分辨率。为了保留低级信息,还通过一些快捷方式将下采样阶段的功能添加到上采样分支。最后,将多尺度特征图合并到预测的三维骨骼关节中。这样,UGCN融合了短期和长期信息,非常适合监控运动损失。
# Attention Mechanism Exploits Temporal Contexts: Real-time 3D Human Pose Reconstruction(2020 CVPR )
我们提出了一种新的基于注意力的框架,用于从单眼视频中估计3D人体姿态。尽管端到端深度学习范式取得了普遍的成功,但我们的方法基于两个关键观察结果:(1)时间不相干和抖动通常来自于单帧预测;(2) 通过增加视频中的感受野可以显著降低错误率。因此,我们设计了一种注意力机制,以自适应地识别每个深度神经网络层的重要帧和张量输出,从而实现更优化的估计。为了获得大的时间感受野,采用多尺度扩张卷积来建模帧之间的长程依赖关系。该体系结构易于实现,可以灵活地用于实时应用。任何现成的2D姿态估计系统,例如Mocap库,都可以很容易地以特殊方式集成。
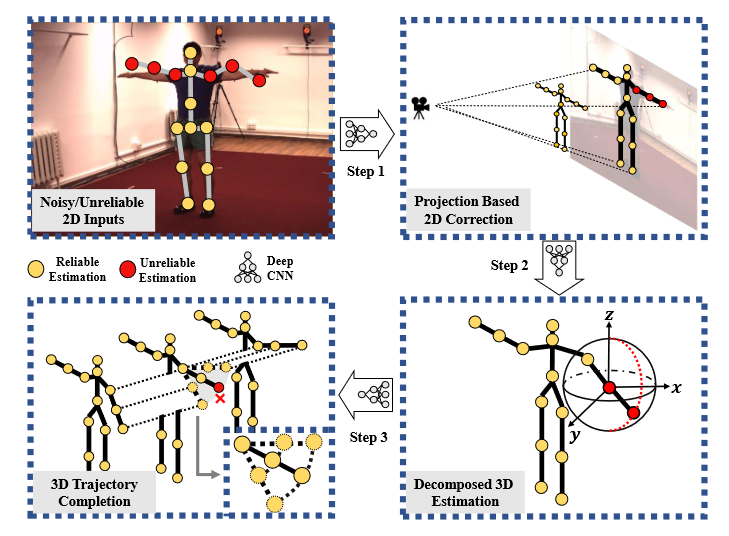
# Deep Kinematics Analysis for Monocular 3D Human Pose Estimation(2020 CVPR )
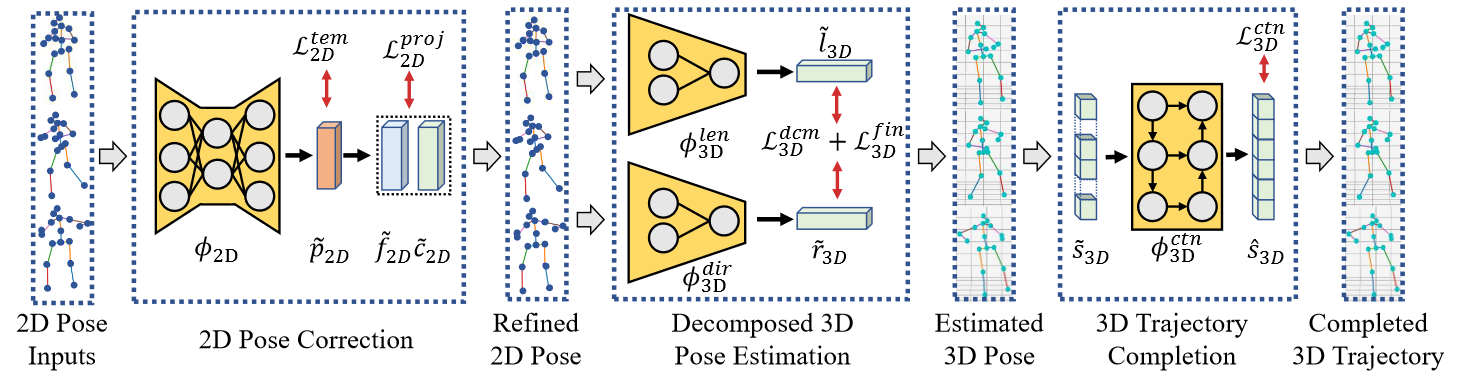
对于基于2D检测的单眼3D姿态估计,噪声/不可靠输入是该任务中的关键障碍。试图解决这一问题的简单结构约束,例如对称性损失和关节角度限制,只能提供边际改进,在以前的研究中通常被视为辅助损失。在这项任务中充分利用人类的先验知识仍然具有挑战性。在本文中,我们建议从系统的角度来解决上述问题。首先,我们表明优化噪声2D输入的运动学结构对于获得精确的3D估计至关重要。其次,基于校正后的2D关节,我们进一步明确地将关节运动与人体拓扑进行分解,这导致更紧凑的3D静态结构更易于估计。最后,我们提出了一个时间模块来细化3D轨迹,从而获得更合理的结果。以上三个步骤无缝集成到深度神经模型中,形成了一个深度运动学分析管道,同时考虑2D输入和3D输出的静态/动态结构。
框架概述。我们的模型追求结构更合理、输出空间更紧凑的三维姿态估计,将运动学分析纳入深度模型。步骤1:使用透视投影校正噪声/不可靠的2D输入(表示为红点)。步骤2:在更紧凑的空间内以分解的方式进一步估计3D姿态。步骤3:从先前的输出(用红色十字表示)中排除不可靠估计的3D姿态,最终将其细化为完成任务
核心在于通过损失函数之间约束
# CamDistHumanPose3D(2021 ICCV)
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning
在无失真数据集上训练的现有3D人体姿态估计算法在应用于具有特定相机失真的新场景时性能下降。 在本文中,我们提出了一种简单而有效的视频中3D人体姿态估计模型,该模型可以通过利用MAML(一种具有代表性的基于优化的元学习算法)快速适应任何失真环境。我们将特定失真中的2D关键点序列视为MAML的单个任务。然而,由于在失真环境中没有大规模数据集,我们提出了一种从未失真的2D关键点生成合成失真数据的有效方法。对于评估,我们假设两种实际测试情况,具体取决于运动捕捉传感器是否可用。特别是,我们提出了使用骨骼长度对称性和一致性的推理阶段优化。
# Skeletal GNN(2021 ICCV)
Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation
已经提出了各种深度学习技术来解决单视图2D到3D姿态估计问题。尽管多年来平均预测精度已得到显著提高,但在具有深度模糊、自遮挡、复杂或罕见姿态的硬姿态上的性能仍远不能令人满意。 在这项工作中,我们针对这些硬姿态,提出了一种新的骨架GNN学习解决方案。具体而言,我们提出了一种跳感知分层信道压缩融合层(hop-aware hierarchical channel-squeezing fusion layer),以有效地从相邻节点提取相关信息,同时抑制GNN学习中的不期望噪声。 此外,我们提出了一种时间感知的动态图构建过程(temporal-aware dynamic graph construction procedure),该过程对于3D姿态估计是鲁棒和有效的。在Human3.6M数据集上的实验结果表明,我们的解决方案实现了10.3%的平均预测准确率提高,并大大改善了最先进技术的硬姿态。我们进一步将所提出的技术应用于基于骨架的动作识别任务,并实现了最先进的性能。
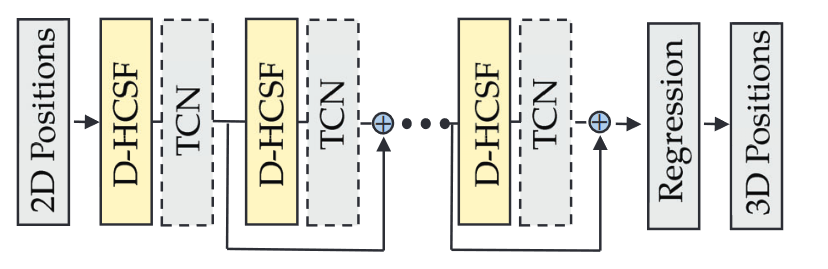
动态分层信道压缩融合(D-HCSF)层在k跳下的架构。每个虚线框由两个流组成:一个基于固定物理边(蓝色线)的加权图学习分支和一个基于节点特征自适应更新图的动态图学习分支(橙色线)
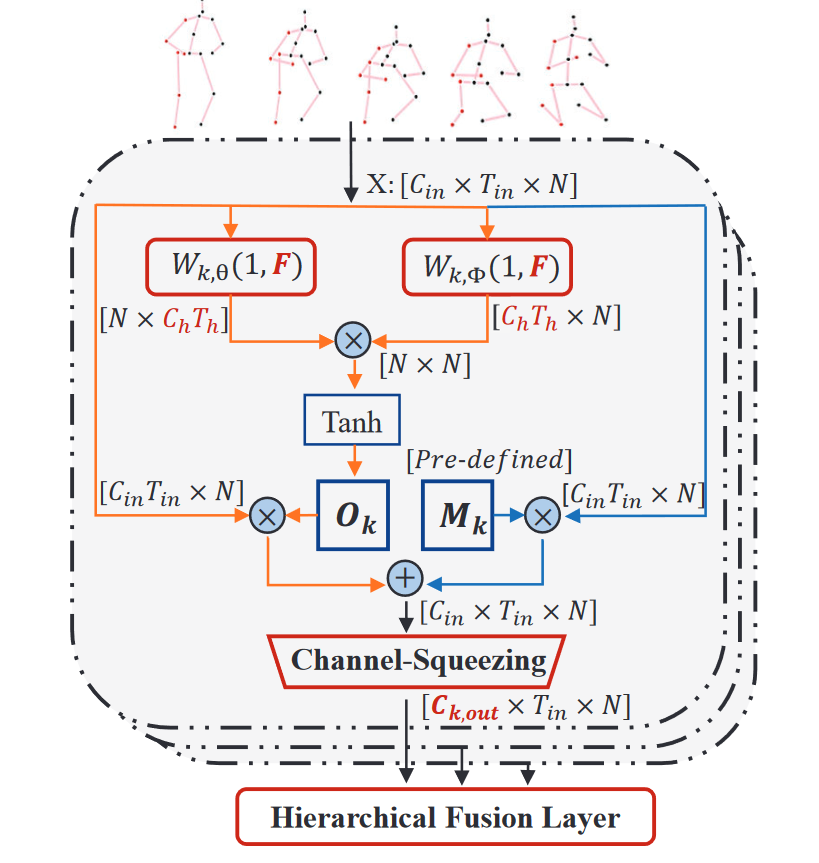
(a)图卷积网络(GCN)、(b)局部连接网络(LCN)和 (c)分层信道压缩融合(HCSF)的架构
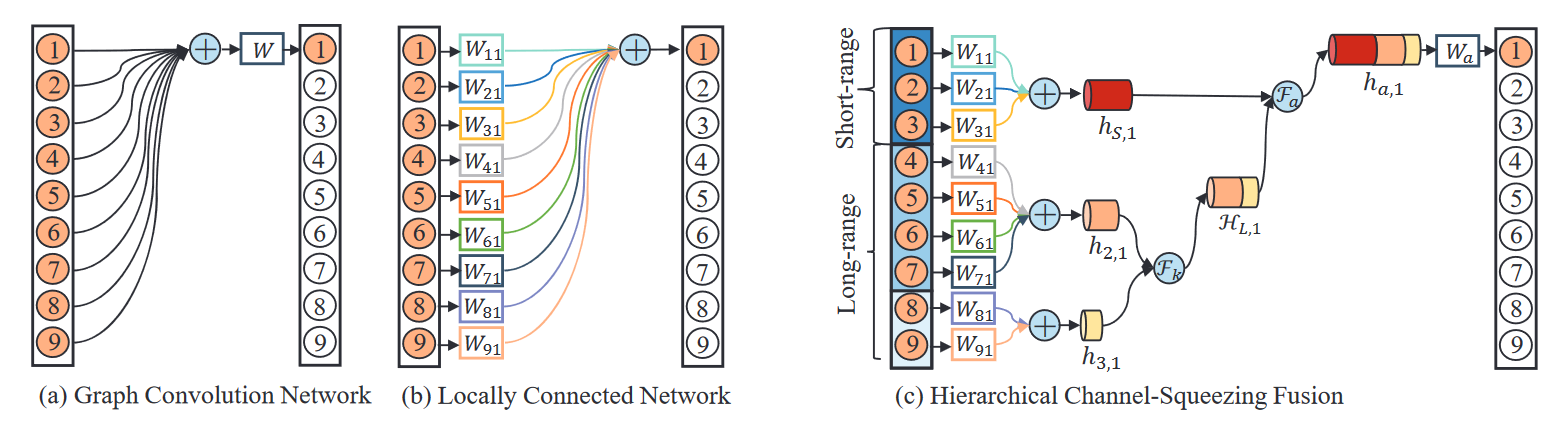
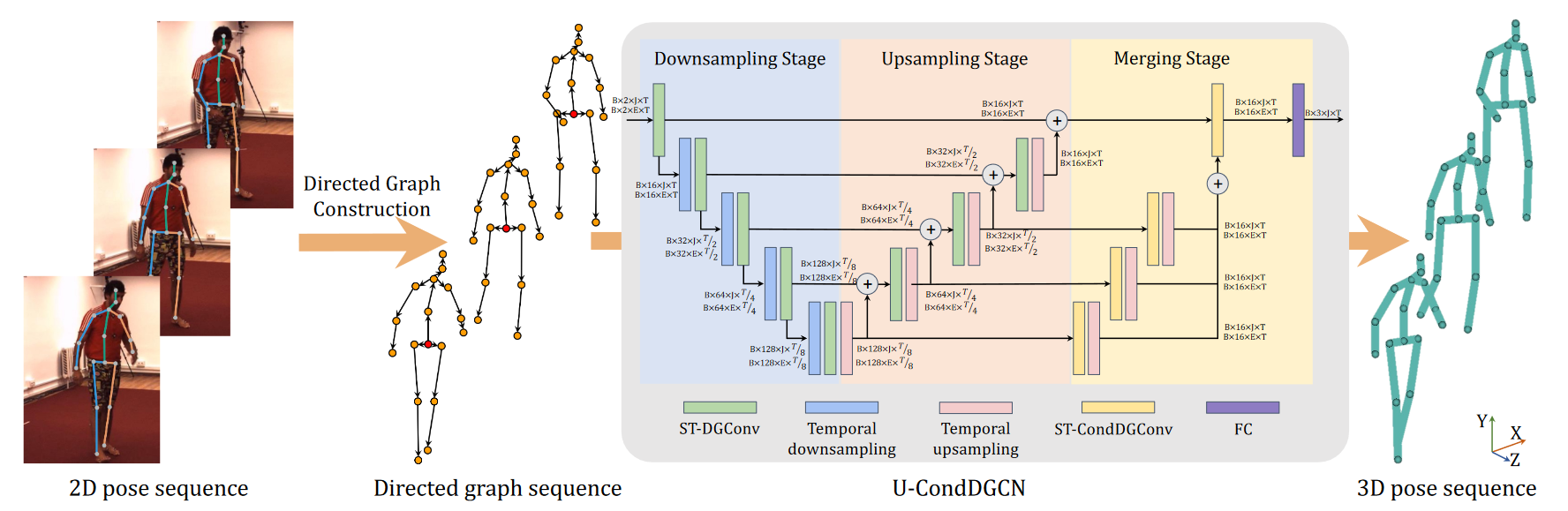
# U-CondDGCN(2021 ACM MM)
Conditional Directed Graph Convolution for 3D Human Pose Estimation
图卷积网络通过将人体骨架表示为无向图,显著改进了3D人体姿态估计。然而,由于关节之间的层次顺序没有明确表示,这种表示无法反映人体骨骼的关节特征。在本文中,我们建议将人体骨骼表示为一个有向图,其中关节作为节点,骨骼作为从父关节指向子关节的边。这样,边的方向可以明确反映节点之间的层次关系。 基于这种表示,我们进一步提出了一种时空条件有向图卷积,通过将图拓扑调整为输入姿态,来利用不同姿态的不同非局部相关性。 总之,我们形成了一个U形网络,称为U形条件有向图卷积网络,用于单目视频中的三维人体姿态估计。为了评估我们的方法的有效性,我们在两个具有挑战性的大型基准上进行了广泛的实验:Human3.6M和MPI-INF-3DHP。定量和定性结果都表明,我们的方法达到了最佳性能。此外,消融研究表明,与无向图相比,有向图可以更好地利用人类关节骨骼的层次结构,并且条件连接可以产生适用于不同姿态的自适应图形拓扑。
在将二维姿态表示为一系列有向图之后,我们可以使用时空有向图卷积(ST-DGConv)来提取特征。然而,ST-DGConv在各种姿态之间共享相同的图形拓扑,这可能不是最优的,因为节点之间存在非局部相关性,并且不同姿态的非局部相关性变化很大。例如,当人们走路时,“左手”和“右脚”关节之间的依赖性明显显著(因为这个姿态可以帮助保持平衡)。相反,吃东西时,“手”和“头”关节之间的依赖性很高。受条件卷积的启发,该卷积允许不同的数据样本使用不同的卷积核,我们提出了时空条件有向图卷积(ST CondDGConv),以调节有向图在输入姿态上的连接,以便不同种类的姿态可以采用适当的连接,以最佳地利用非局部依赖性。
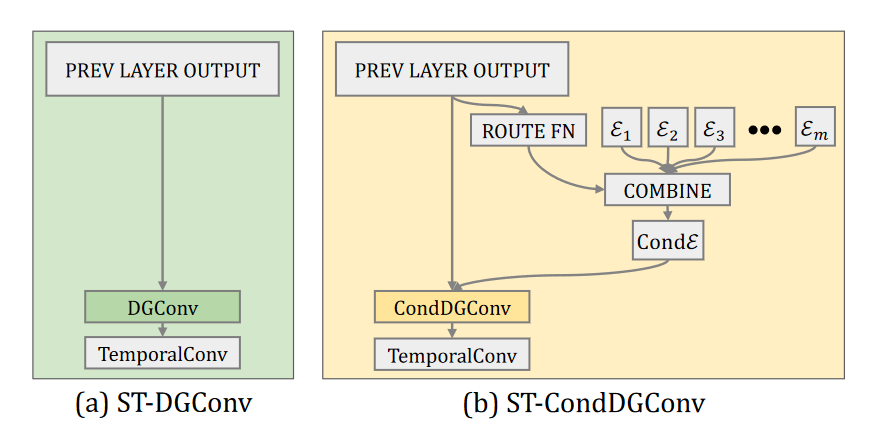
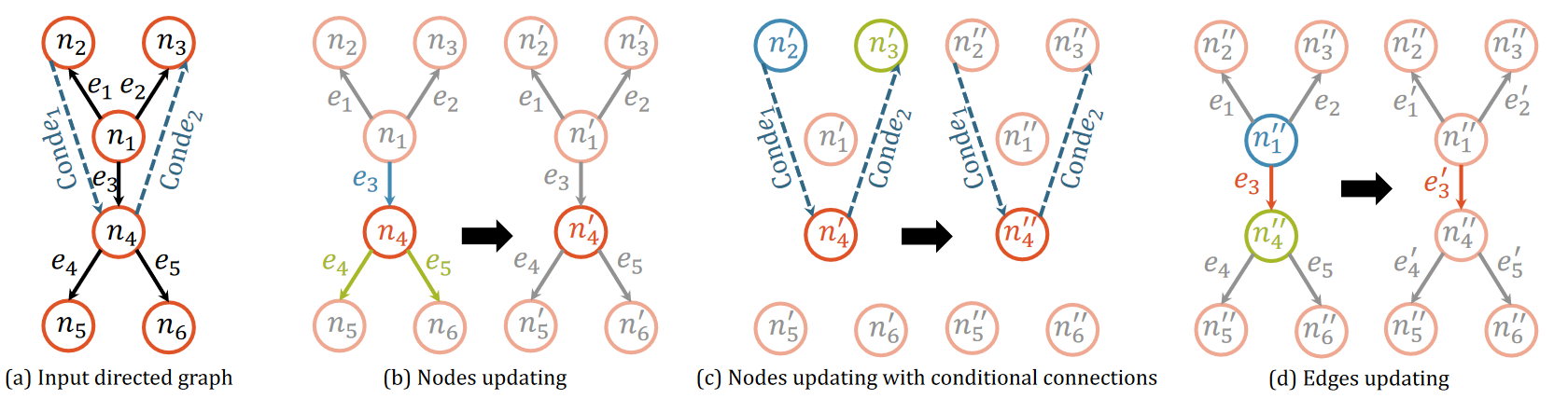
条件有向图卷积(CondDGConv)
部分(a)是具有预定义连接的输入有向图(𝑒𝑖 ) 和预测的条件连接(Cond𝑒𝑖 ). 第(b)、(c)和(d)部分是CondDGConv的三个步骤。
# RIE(2021 ACM MM)
Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation
大多数现有的3D人体姿态估计方法主要集中于预测根关节和其他人体关节之间的3D位置关系(局部运动),而不是人体的整体轨迹(全局运动)。尽管这些方法取得了巨大的进步,但它们对全局运动不鲁棒,并且缺乏在小运动范围内准确预测局部运动的能力。为了缓解这两个问题,我们提出了一种产生位置和时间增强表示的相对信息编码方法。首先,我们利用二维姿态的相对坐标对位置信息进行编码,以增强输入和输出分布之间的一致性。具有不同绝对2D位置的相同姿态可以映射到公共表示。有利于抵抗全局运动对预测结果的干扰。第二,我们通过建立同一个人在一段时间内的当前姿态和其他姿态之间的联系来编码时间信息。将更多地关注当前姿态前后的运动变化,从而在较小的运动范围内对局部运动具有更好的预测性能。 消融研究验证了所提出的相对信息编码方法的有效性。此外,我们将多阶段优化方法引入到整个框架中,以进一步利用位置和时间增强表示。
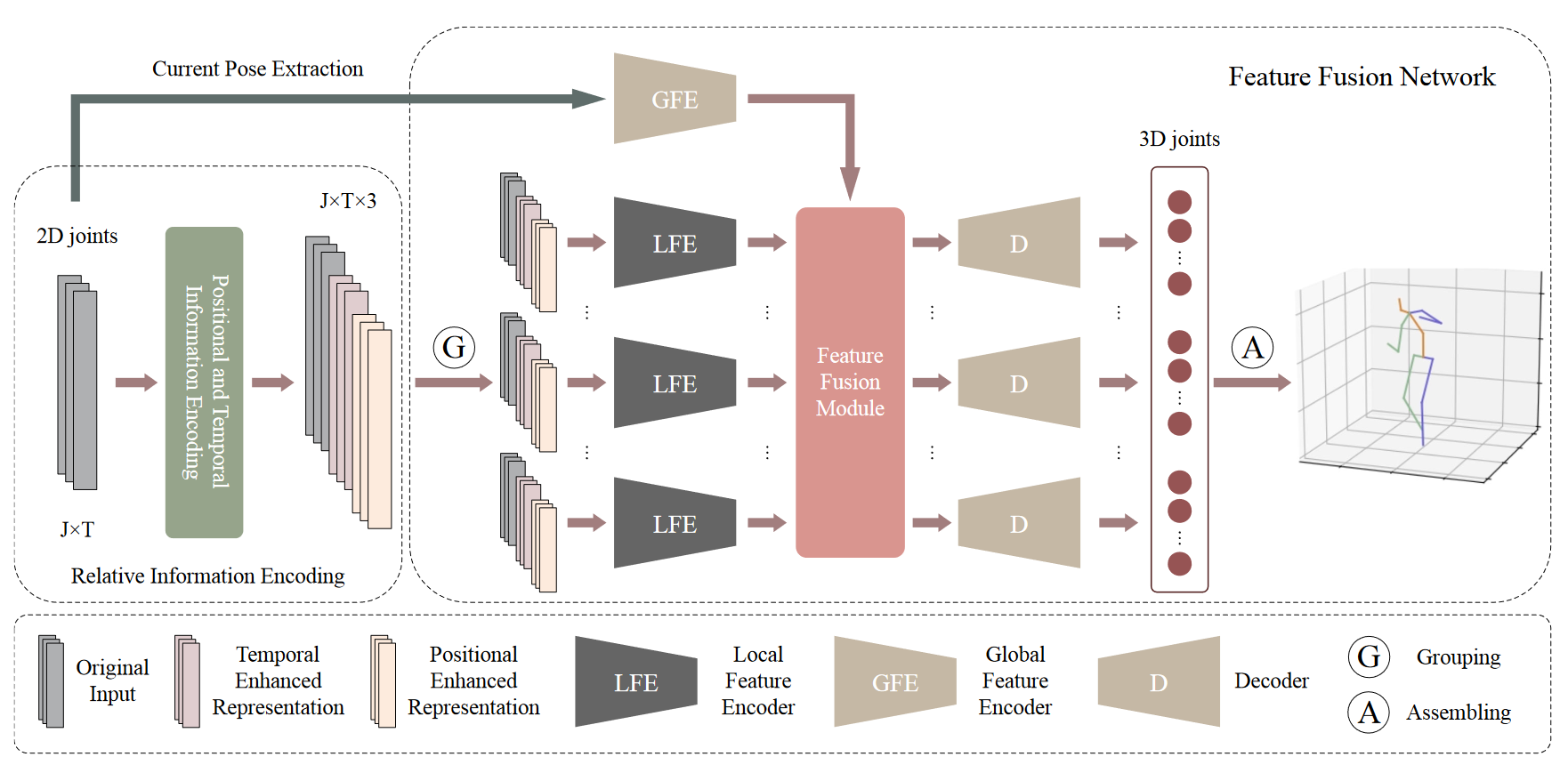
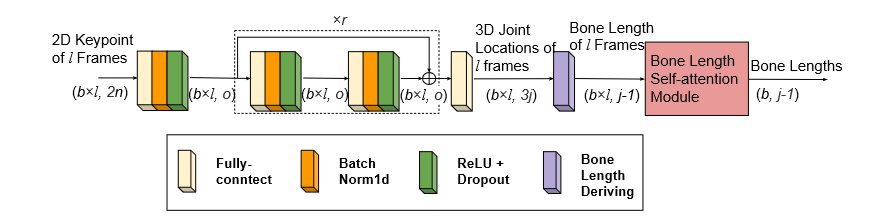
# Anatomy3D (2021 TCSVT)
Anatomy-Aware 3D Human Pose Estimation With Bone-Based Pose Decomposition
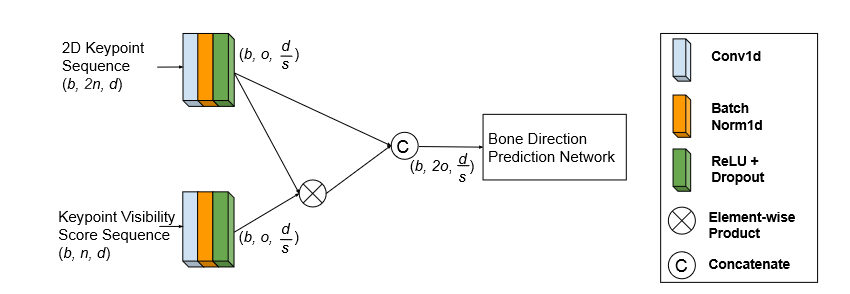
在这项工作中,我们提出了一种视频中3D人体姿态估计的新解决方案。我们不是直接回归3D关节位置,而是从人体骨骼解剖结构中获得灵感,并将任务分解为骨骼方向预测和骨骼长度预测,从中可以完全导出3D关节位置。我们的动机是人类骨骼的骨骼长度在时间上保持一致。 这促使我们开发有效的技术来利用视频中所有帧的全局信息来进行高精度的骨骼长度预测。此外,对于骨骼方向预测网络,我们提出了一种具有长跳跃连接的完全卷积传播架构。本质上,它可以分层预测不同骨骼的方向,而不使用任何耗时的内存单元(例如LSTM)。进一步引入了一种新的关节移位损失来桥接骨长度和骨方向预测网络的训练。最后,我们使用隐式注意机制将2D关键点可见性分数作为额外指导反馈到模型中,这显著减轻了许多挑战性姿态中的深度模糊。我们的完整模型在Human3.6M和MPI-INF-3DHP数据集上优于之前的最佳结果,综合评估验证了我们模型的有效性。
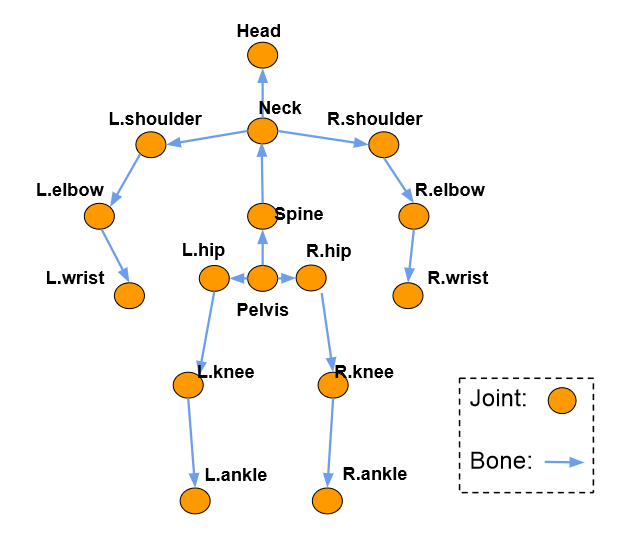
建议的解剖感知框架
它分别使用整个视频中的连续局部帧和随机采样帧来预测当前帧的骨骼方向和骨骼长度。
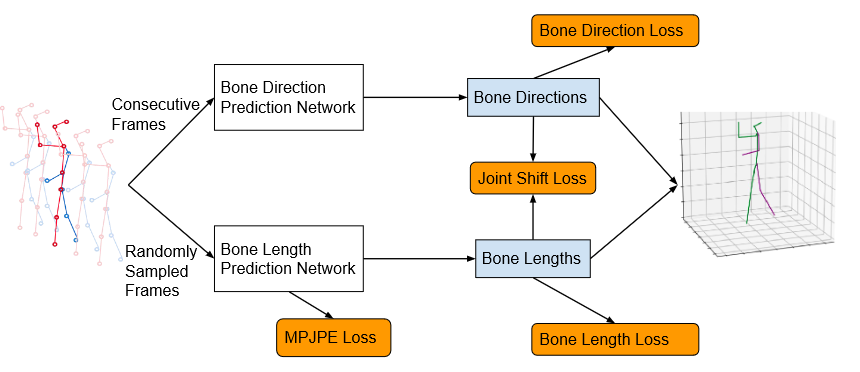
骨骼方向预测网络的架构
在相邻子网络之间添加长跳转连接。我们说明了每个输入/输出的维度。b是批次大小。o是完全连接层的输出通道号。s是网络中1D卷积层的步长(s=3)。n是2D关键点集的大小。d是底层子网络的输入帧号。
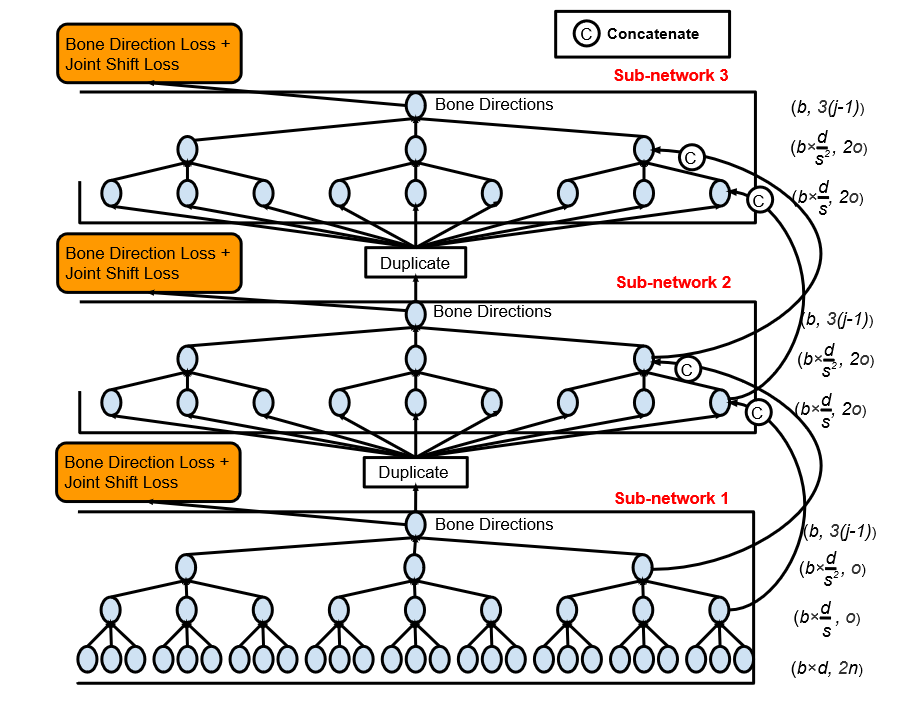
骨骼长度预测网络的结构
r是残差块的数目。
提供可见性分数的网络结构
d是骨方向预测网络的输入帧号,s和o分别是1D卷积层的步幅和输出信道号。
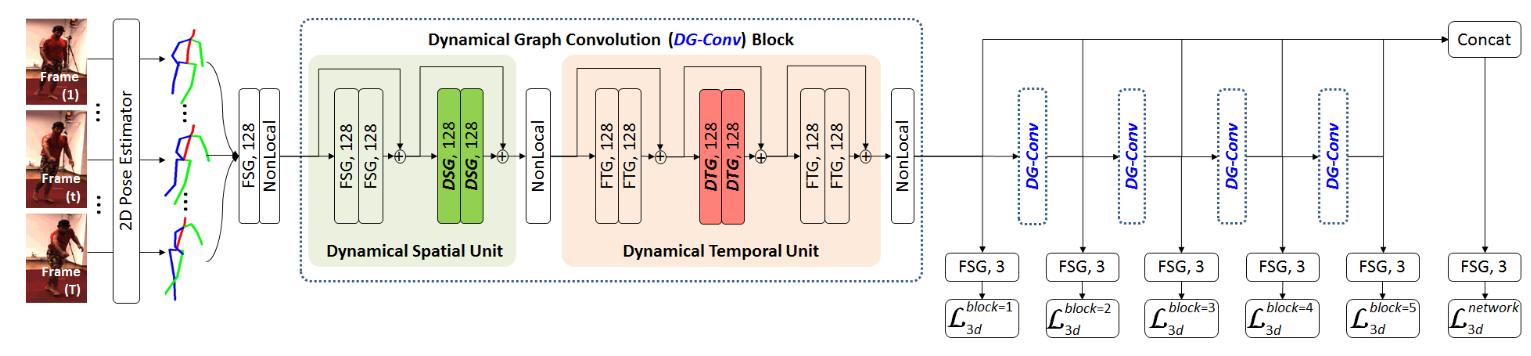
# DG-Net(2021 TIP)
Learning Dynamical Human-Joint Affinity for 3D Pose Estimation in Videos
图卷积网络(GCN)已成功地用于视频中的3D人体姿态估计。然而,根据人类骨骼,它通常建立在固定的人类关节亲和力上。这可能会降低GCN处理视频中复杂时空姿态变化的适应能力。为了缓解这一问题,我们提出了一种新的动态图网络(DG-Net),该网络可以动态识别人体关节亲和力,并通过从视频中自适应学习空间/时间关节关系来估计3D姿态。与传统的图卷积不同,我们引入了动态空间/时间图卷积(DSG/DTG)来发现每个视频样本的空间/时间人类关节亲和力,这取决于视频中人类关节之间的空间距离/时间运动相似性。因此,他们可以有效地了解哪些关节在空间上更接近和/或具有一致的运动,从而在将2D姿态提升为3D姿态时减少深度模糊和/或运动不确定性。
通过KNN算法找到邻近节点作为额外连接
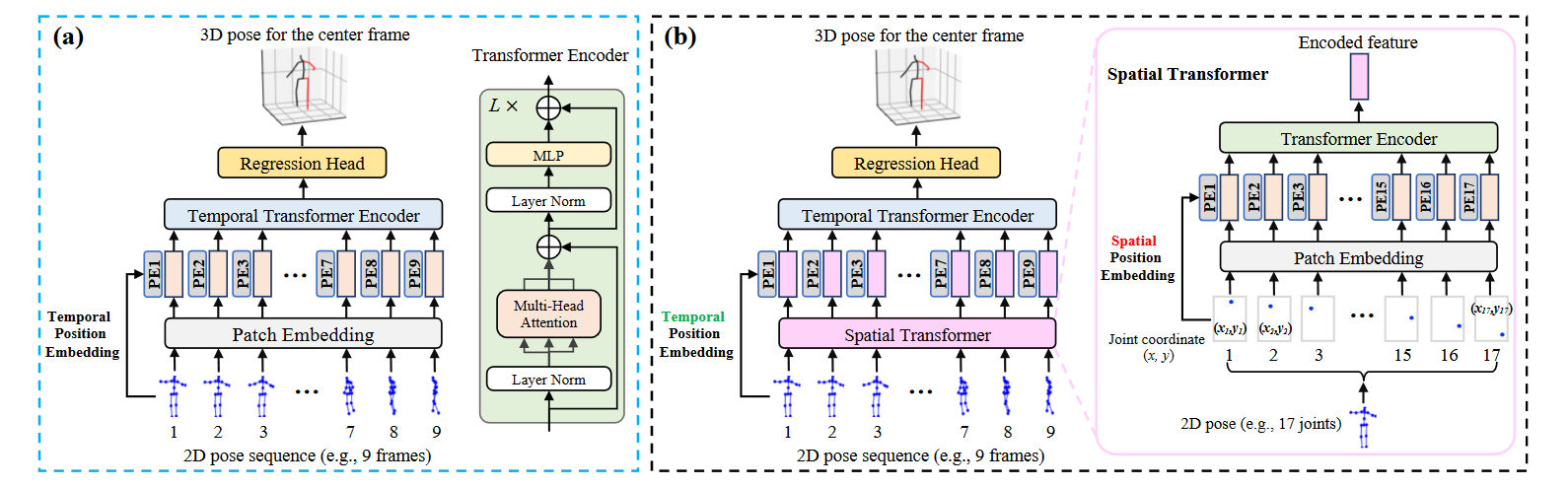
# PoseFormer(2021 ICCV)📌
3D Human Pose Estimation with Spatial and Temporal Transformers
Transformers架构已成为自然语言处理中的首选模型,现在正被引入计算机视觉任务,如图像分类、对象检测和语义分割。然而,在人体姿态估计领域,卷积结构仍然占主导地位。在这项工作中,我们提出了PoseFormer,这是一种纯基于Transformers的方法,用于视频中的3D人体姿态估计,不涉及卷积结构。受视觉变换器最新发展的启发,我们设计了一种Spatial and Temporal Transformers结构,以全面建模每个帧内的人体关节关系以及帧间的时间相关性,然后输出中心帧的精确三维人体姿态。我们在两个流行的标准基准数据集上定量和定性地评估了我们的方法:Human3.6M和MPI-INF-3DHP。大量实验表明,PoseFormer在两个数据集上都达到了最先进的性能。
# MHFormer(2022 CVPR)
MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation
由于深度模糊和自遮挡,从单目视频中估计3D人体姿态是一项具有挑战性的任务。大多数现有的作品试图通过利用空间和时间关系来解决这两个问题。然而,这些工作忽略了一个事实,即存在多个可行解(即假设)的情况下,这是一个逆问题。为了缓解这一限制,我们提出了一种多假设变换器(MHFormer),该变换器学习多个合理姿态假设的时空表示。为了有效地建模多假设依赖性并在假设特征之间建立强大的关系,任务被分解为三个阶段:(i)生成多个初始假设表示;(ii)对自我假设沟通进行建模,将多个假设合并为一个单一的融合表示,然后将其划分为几个发散的假设;(iii)学习跨假设通信并聚合多假设特征以合成最终3D姿态。通过以上过程,最终的表示得到了增强,合成的姿态更加准确。
出发点
最近,针对逆问题提出了两种方法,它们可以生成多个假设。他们通常依赖于一对多映射,通过使用共享特征提取器将多个输出头添加到现有架构中,而无法建立不同假设的特征之间的关系。这是一个重要的缺点,因为这种能力对于提高模型的表现力和性能至关重要。鉴于3D HPE的模糊逆问题,我们认为先进行一对多映射,然后使用各种中间假设进行多对一映射更为合理,因为这样可以丰富特征的多样性,并为最终的3D姿态生成更好的合成。
网络架构
a) 提出的多假设变压器(MHFormer)概述。(b) 多假设生成(MHG)模块提取每个帧内人体关节的固有结构信息,并生成多个假设表示。N是输入帧的数量,T是矩阵转置。(c) 自假设细化(SHR)模块用于细化单假设特征。(d) SHR之后的交叉假设交互(CHI)模块支持多假设特征之间的交互。
该框架更有效地建模多假设依赖性,同时也在假设特征之间建立更强的关系。
第一阶段,构建多假设生成(MHG)模块,以对人体关节的固有结构信息进行建模,并在空间域中生成多个多层次特征。这些特征包含从浅到深的不同深度的不同语义信息,因此可以被视为多个假设的初始表示。接下来,我们提出了两个新的模块来建模时间一致性,并增强时间域中的粗糙表示,这两个模块尚未被现有的生成多个假设的工作所探索。
第二阶段,提出了一个自假设细化(SHR)模块来细化每个假设特征。SHR由两个新块组成。第一个块是多假设自我关注(MH-SA),它独立地对单个假设依赖性建模,以构建自我假设通信,从而使每个假设中的信息传递能够用于特征增强。第二个块是假设混合多层感知器(MLP),其在假设之间交换信息。将多个假设合并为单个收敛表示,然后将该表示划分为多个发散假设。尽管SHR对这些假设进行了细化,但由于SHR中的MH-SA仅传递假设内信息,因此不同假设之间的联系不够强。为了解决这个问题,
最后阶段,一个跨假设交互(CHI)模块对多假设特征之间的交互进行建模。它的关键组成部分是多假设交叉注意(MH-CA),它捕获相互多假设相关性以建立交叉假设通信,使信息能够在假设之间传递,从而更好地进行交互建模。随后,使用假设混合MLP来聚合多个假设以合成最终预测。
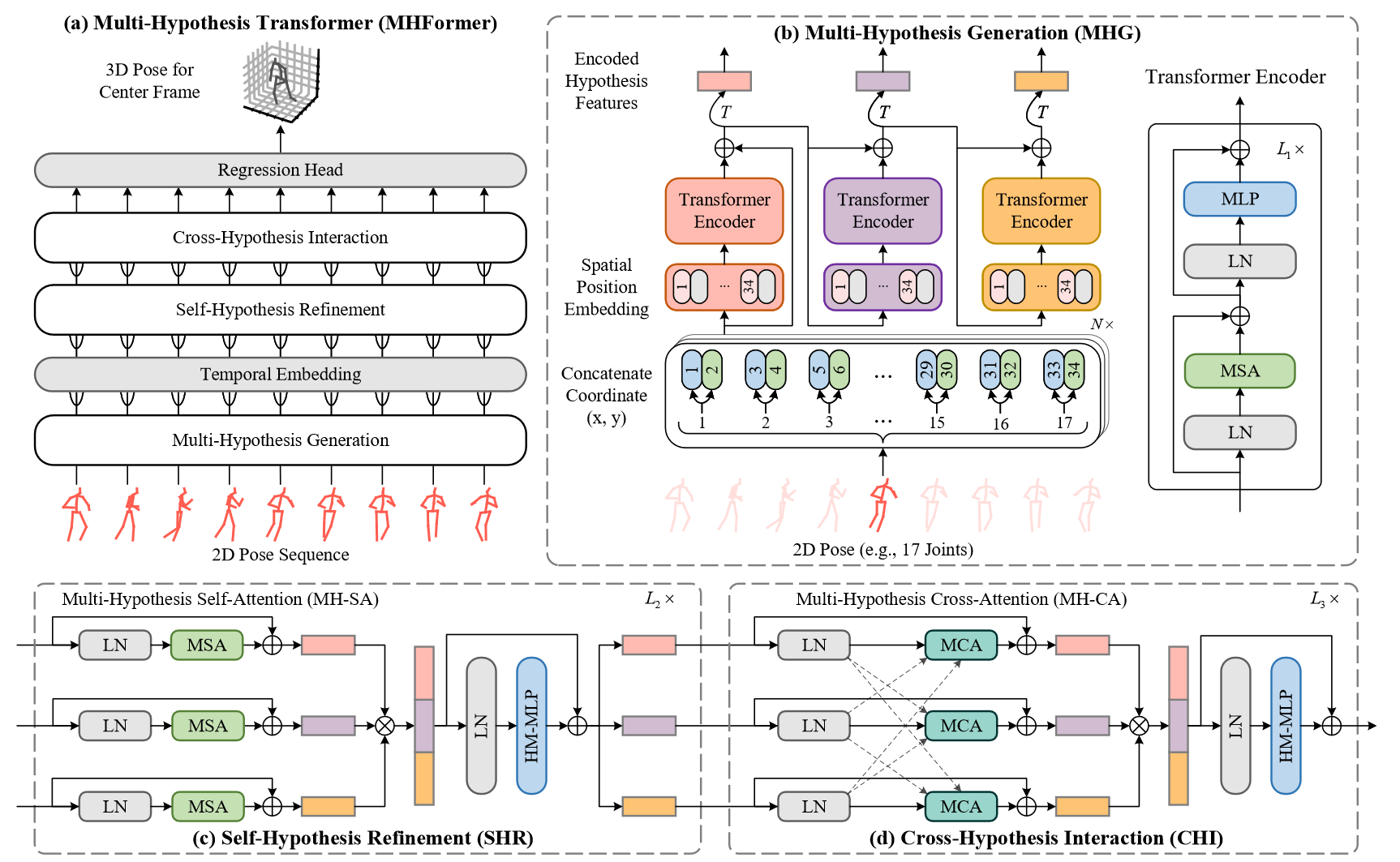
限制
这个方法的一个限制是相对较大的计算复杂度。《Transformer》的优异性能是以高昂的计算成本为代价的。
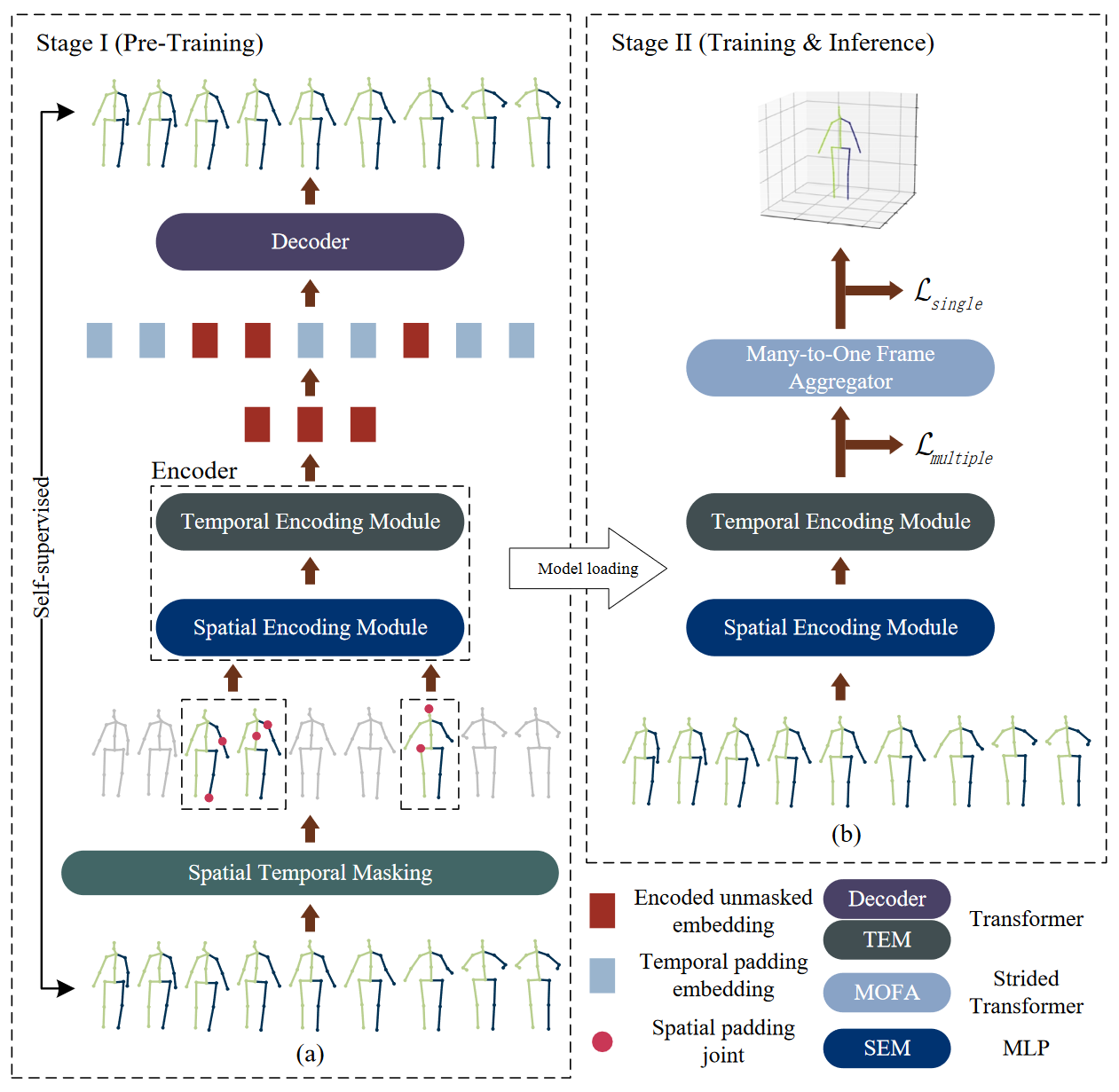
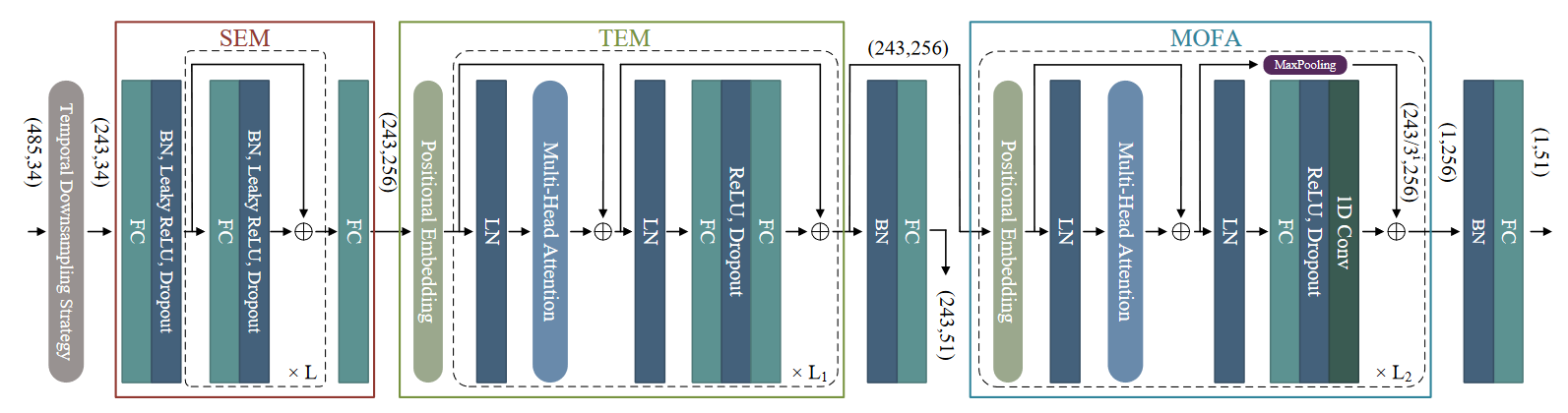
# P-STMO(2022 ECCV)
P-STMO: Pre-Trained Spatial Temporal Many-to-One Model for 3D Human Pose Estimation
介绍了一种用于2D到3D人体姿态估计任务的新型预训练时空多对一(P-STMO)模型。为了减少捕捉空间和时间信息的难度,我们将此任务分为两个阶段:预训练(第一阶段)和微调(第二阶段)。在第一阶段,提出了一个自我监督的预训练子任务,称为掩蔽姿态建模。输入序列中的人体关节在空间域和时间域中都被随机屏蔽。利用一般形式的去噪自动编码器来恢复原始2D姿态,并且编码器能够以这种方式捕获空间和时间相关性。在第二阶段,将预先训练的编码器加载到STMO模型并进行微调。编码器之后是多对一帧聚合器(MOFA),以预测当前帧中的3D姿态。特别是,在STMO中使用MLP块作为空间特征提取器,其性能优于其他方法。此外,还提出了一种时间下采样策略来减少数据冗余。在两个基准上的大量实验表明,我们的方法以更少的参数和更少的计算开销优于最先进的方法。
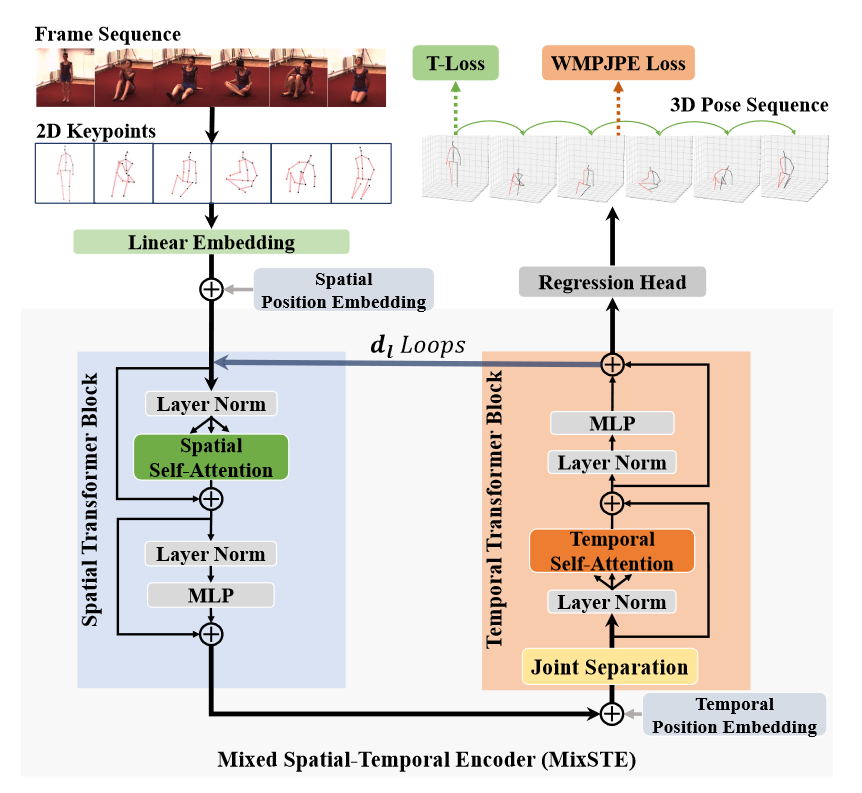
# MixSTE(2022 CVPR)📌
MixSTE:Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video
目前这个方向单目数据最优的工作(2022-10-05)
最近引入了基于Transformer的解决方案,通过全局考虑所有帧中的身体关节来学习时空相关性,从而从2D关键点序列估计3D人体姿态。我们观察到不同关节的运动明显不同。然而,以往的方法不能有效地对每个关节的实体帧间对应关系进行建模,导致时空相关性学习不足。我们提出了混合时空编码器(Mixed Spatio Temporal Encoder,简称MixSTE),它有一个时间变换块来分别建模每个关节的时间运动,还有一个空间变换块来学习关节间的空间相关性。这两个块被交替使用以获得更好的时空特征编码。此外,网络输出从中心帧扩展到输入视频的整个帧,从而提高输入和输出序列之间的一致性(Seq2seq)。在三个基准(即Human3.6M、MPI-INF-3DHP和HumanEva)上进行了广泛的实验。
# StridedTransformer(2022 TMM)
Exploiting Temporal Contexts with Strided Transformer for 3D Human Pose Estimation
在这项工作中,我们研究了将基于Transformer的网络应用于基于视频的3D人体姿态估计任务的适用性。从提出的带有Strided Transformer Encoder(STE)的Strided Transformer和full-to-single监控方案中,我们展示了如何从冗余序列中学习具有代表性的单姿态表示。关键是在Transformer架构中合理地使用跨卷积,以分层的全局和局部方式将长距离信息聚合为单个矢量姿态。同时,可以显著降低计算成本。此外,我们的全到单监督方案增强了时间平滑度,并进一步细化了目标帧的表示。在两个基准数据集上的综合实验表明,与最先进的方法相比,我们的方法实现了优越的性能。
网络架构
该网络包含一个Vanilla Transformer Encoder(VTE)和一个Strided Transformer Encoder(STE),后者在全序列和单目标帧标度下以全到单预测方案进行训练。具体而言,VTE首先用于对长距离信息进行建模,并由全序列尺度进行监督,以增强时间平滑性。然后,所提出的STE聚合信息以生成一个目标姿态表示,并由单个目标帧尺度监督以产生更准确的估计。
在VTE的FFN中现有的完全连接(FC)层中,它总是以高计算成本在所有层上保持完整的隐藏表示序列。它包含基于视频的姿态估计的显著冗余,因为附近的姿态非常相似。然而,为了更准确地重建目标帧的3D人体关节,必须从整个姿态序列中提取关键信息。因此,它需要选择性地聚合有用的信息。 为了解决这个问题,我们对通用FFN进行了修改,使用跨步卷积。
STE它通过逐渐减少序列长度来重建目标3D身体关节。输入由2D关键点组成,用于27帧的接收场,J=17个关节。卷积前馈网络为蓝色,其中(3,3,256)表示具有跨距因子3和256个输出通道的大小为3的内核。张量大小在括号中显示,例如,(27,34)表示27个帧和34个通道。由于交叉卷积,最大池运算应用于残差以匹配后续张量的形状。

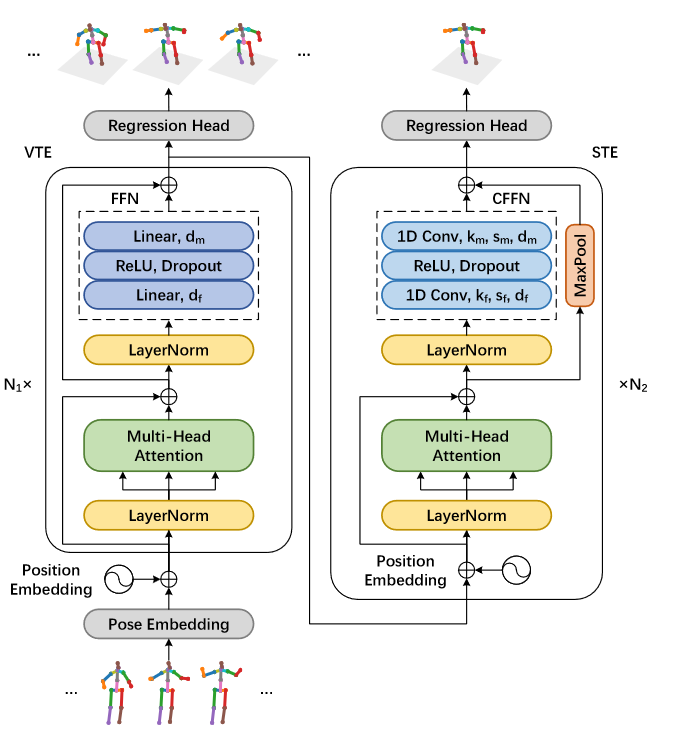
# CrossFormer(2022)
CrossFormer: Cross Spatio-Temporal Transformer for 3D Human Pose Estimation
3D人体姿态估计可以通过编码身体部位之间的几何依赖性并实施运动学约束来处理。最近,Transformer被用于对空间域和时间域中关节之间的长距离相关性进行编码。虽然他们在长期依赖性方面表现出色,但研究表明需要改善视觉Transformer的局部性。在这个方向上,我们提出了一种新颖的姿态估计变换器,其特征在于身体关节的丰富表示,这对于捕捉帧间的细微变化至关重要(即,特征间表示)。具体来说,通过两个新颖的交互模块;Cross-Joint Interaction and CrossFrame Interaction,模型显式编码身体关节之间的局部和全局依赖关系。
提出的架构基于PoseFormer。由两个主要模块组成:空间变换器和交叉关节交互模块(CJI),以及时间变换器和提出的交叉帧交互模块(CFI)。
# DH-AUG(2022 ECCV)
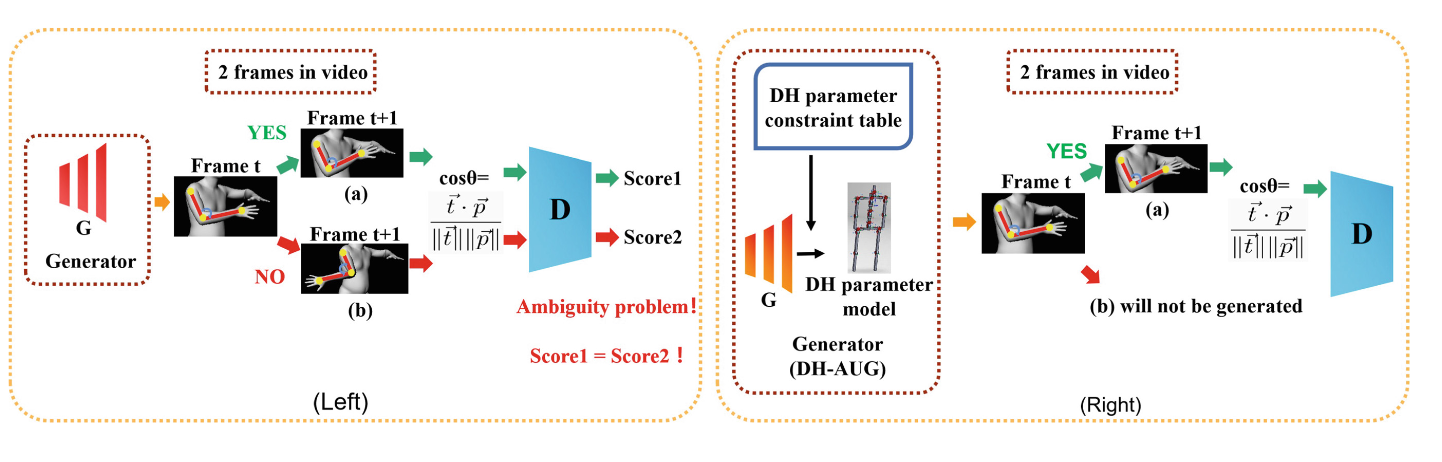
DH-AUG: DH Forward Kinematics Model Driven Augmentation for 3D Human Pose Estimation
由于数据集缺乏多样性,姿态估计器的泛化能力较差。为了解决这个问题,我们提出了一种通过DH正向运动学模型的姿态增强解决方案,我们称之为DH-AUG。我们观察到,先前的工作都是基于单帧姿态增强,如果将其直接应用于视频姿态估计,将存在几个先前被忽略的问题:(i)骨骼旋转中的角度模糊(多个解决方案);(ii)生成的骨架视频缺乏运动连续性。为了解决这些问题,我们提出了一种基于DH正向运动学模型的特殊生成器,称为DH生成器。大量实验表明,DH-AUG可以大大提高视频姿态估计器的泛化能力。此外,当应用于单帧3D姿态估计器时,我们的方法优于先前的最佳姿态增强方法。
角度模糊(多个解决方案)。左图:普通GAN框架的姿态增强。右:DH-AUG。(a) :弯头正常旋转(角度约为90◦). (b) :弯头旋转异常(角度约为−90◦). 虽然(a)和(b)的旋转方向不同,但向量内积计算的余弦角值是相同的。两者都会使鉴别器输出相同的分数,从而产生歧义。为了削弱模糊问题,我们通过添加DH正向运动学模型(DH参数模型)和约束来改进生成器。t和p是一对相邻的骨向量。SMPL[25]仅用于可视化。
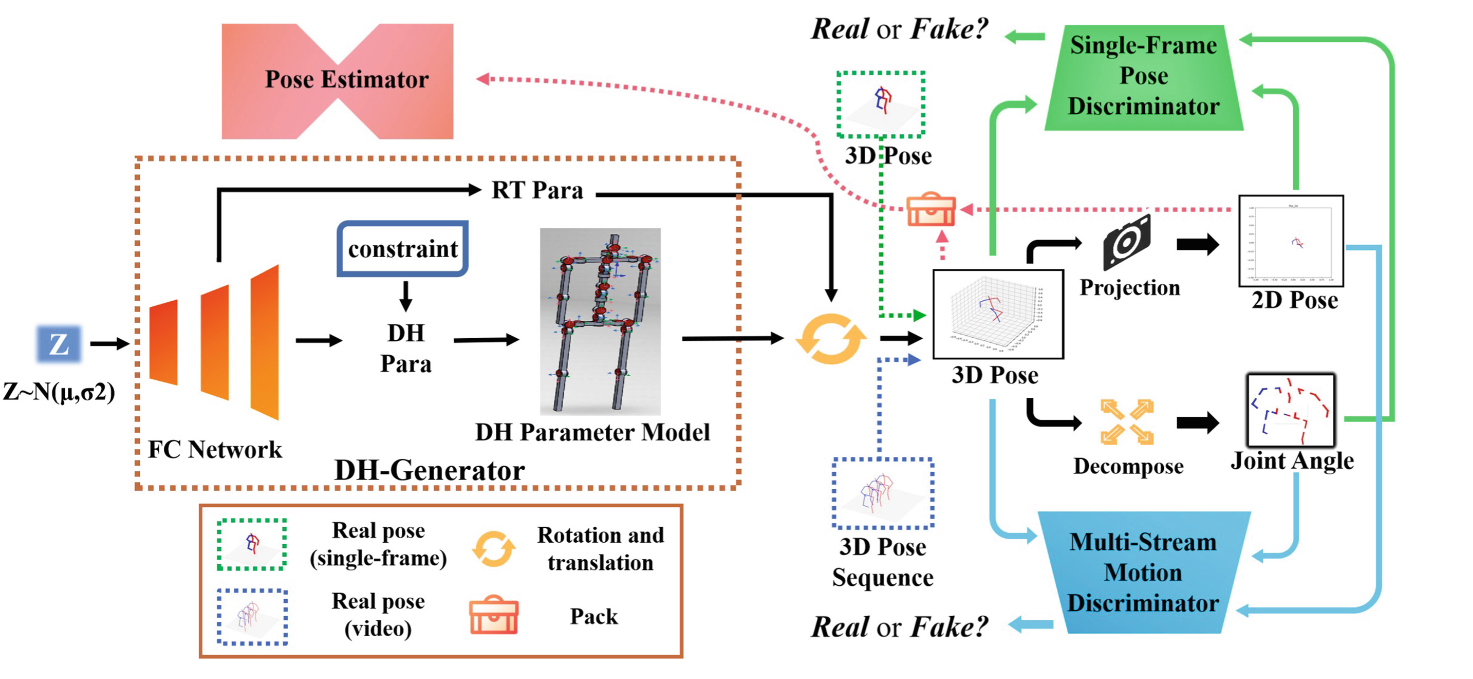
DH-AUG总体框架概述
从正态分布中采样128维向量并输入到完全连接的网络中以获得DH参数、全局旋转和平移参数。然后,通过DH参数模型获得三维姿态。1) 单帧:3D姿态、2D姿态和关节角度被传输到单帧姿态鉴别器进行训练。2) 视频:将3D姿态序列、2D姿态序列、骨骼旋转轨迹(关节角度)输入到单帧姿态鉴别器和多流运动鉴别器中。最后,新生成的2D-3D数据对被打包成新的数据集,并被传输到姿态估计器以进行训练。
# Multi-hypothesis 3D human pose estimation metrics favor miscalibrated distributions(2022 arxiv)
由于深度模糊和遮挡,将2D姿势提升到3D姿势是一个非常不适定的问题。经过良好校准的可能姿态分布可以使这些模糊性变得明确,并为下游任务保留由此产生的不确定性。 这项研究表明,以前的尝试,通过多个假设的生成来解释这些模糊性,会产生错误校准的分布。我们发现,错误校准可归因于使用基于样本的度量,如minMPJPE。在一系列模拟中,我们表明,像通常做的那样,最小化最小MPJPE应该收敛到正确的平均预测。然而,它未能正确地捕捉不确定性,从而导致分配错误。 为了缓解这个问题,我们提出了一个精确且校准良好的模型,称为条件图归一化流Conditional Graph Normalizing Flow(cGNF)。我们的模型结构合理,单个cGNF可以在同一模型中估计条件密度和边际密度,有效解决了零样本密度估计问题。我们在人类3.6M数据集上评估了cGNF,并表明cGNF提供了一个校准良好的分布估计,同时在总体minMPJPE方面接近现有技术。此外,cGNF在闭塞关节方面优于以前的方法,同时保持良好的校准。
# SPGNet(2022 arxiv)
SPGNet: Spatial Projection Guided 3D Human Pose Estimation in Low Dimensional Space
# Uncertainty-Aware HPE(2022 ACM MM)
Uncertainty-Aware 3D Human Pose Estimation from Monocular Video
在本文中,我们分别提出了一种不确定性感知方法来优化𝑑𝑒𝑝𝑡ℎ 和𝑥 −𝑦 三维人体姿态估计的坐标。所采用的证据深度学习能够量化深度模糊的不确定性。此外,探索的2D概率表示可以有效地建模2D检测输入的分布不确定性并校准其偏差。基于GCN Transformer的高效编码器使我们的模型能够在关键点序列中为不确定性估计提供有效的空间和时间相关性。重要的是,这项工作为从单眼视频中进行3D人体姿态估计开辟了一条新的不确定性学习基线。大量实验表明,我们的方法达到了最先进的性能。
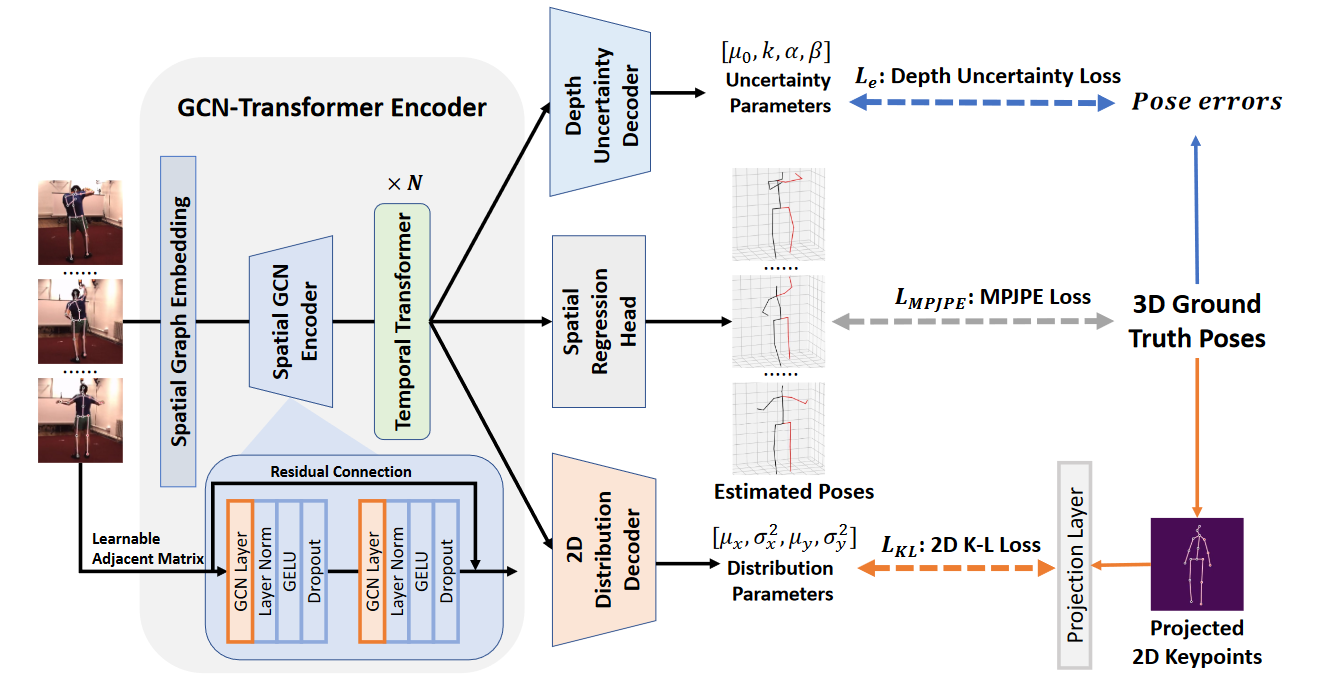
# OCR-Pose(2022 ACM MM)
OCR-Pose: Occlusion-aware Contrastive Representation for Unsupervised 3D Human Pose Estimation
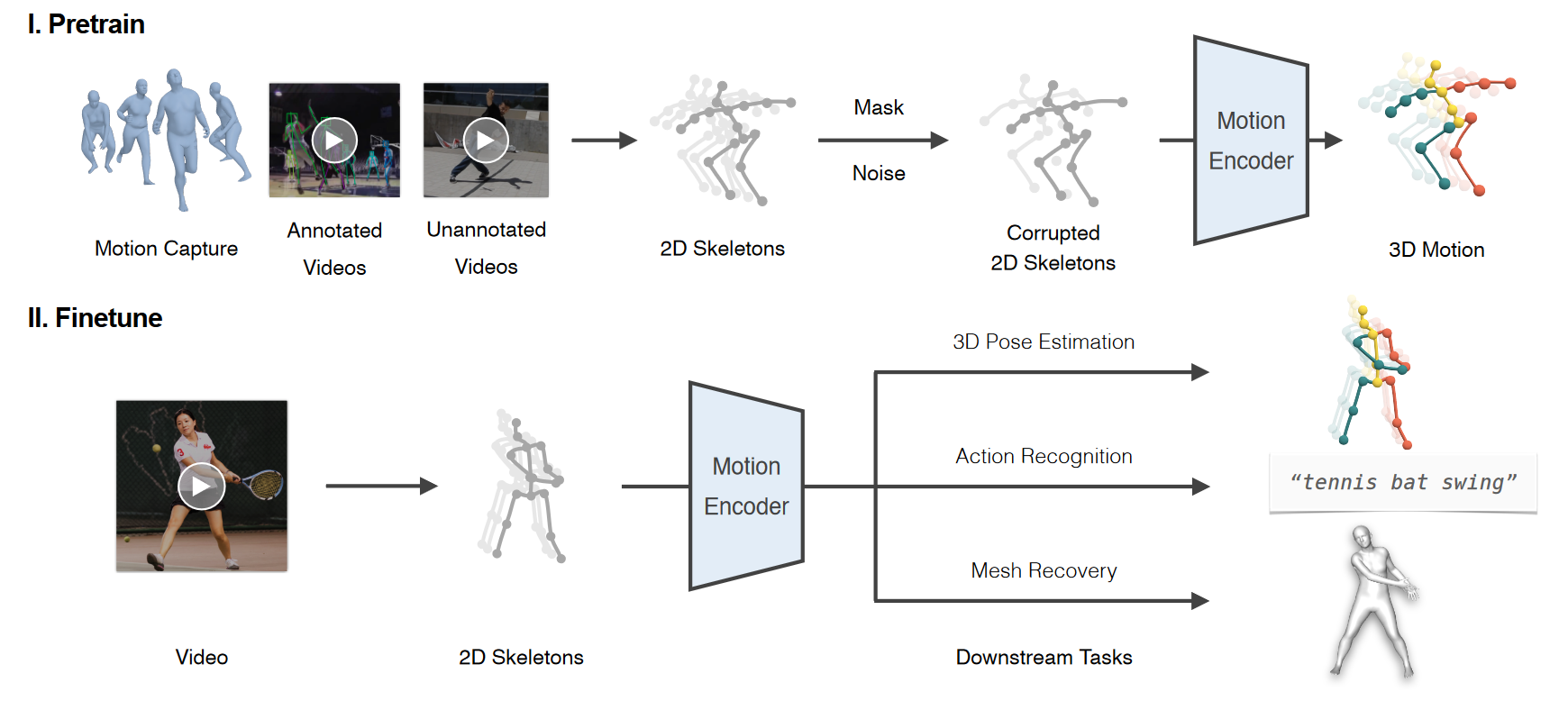
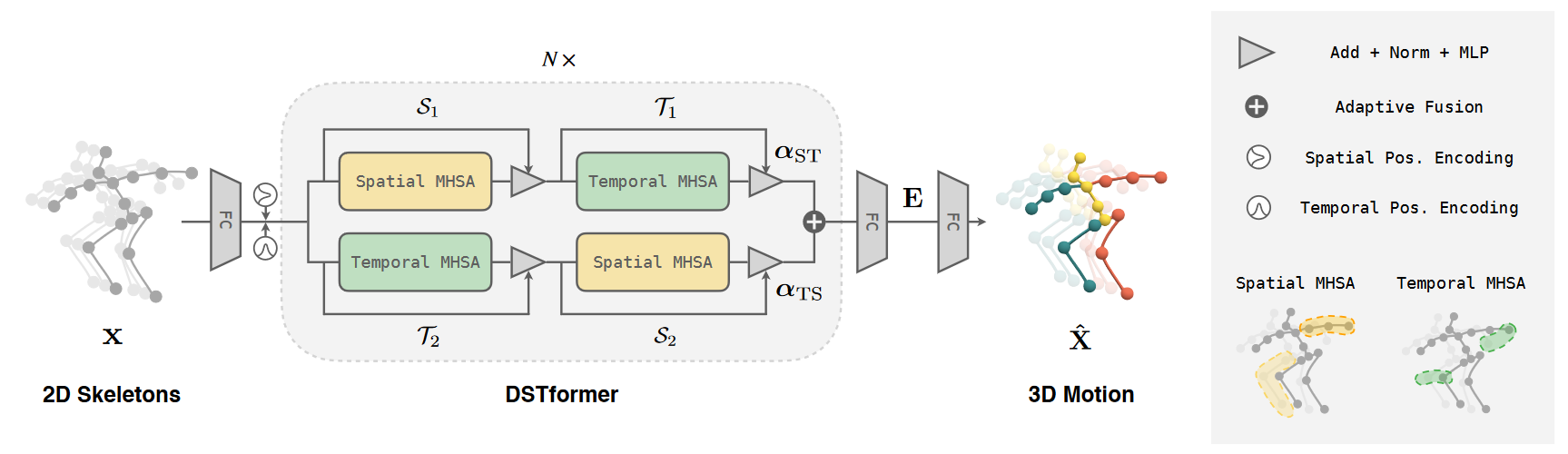
# MotionBERT(2022 arxiv)📌
MotionBERT: Unified Pretraining for Human Motion Analysis
我们提出MotionBERT,一个统一的预训练框架,用于处理人体运动分析的不同子任务,包括3D姿态估计、基于骨架的动作识别和网格恢复。所提出的框架能够利用各种人类运动数据资源,包括运动捕捉数据和野生视频。在预训练期间,pretext任务要求运动编码器从有噪声的部分2D观察中恢复基础3D运动。因此,预训练的运动表示获得了关于人类运动的几何、运动学和物理知识,因此可以容易地转移到多个下游任务。我们用一种新颖的双流时空Transformer(DSTformer)神经网络实现了运动编码器。它可以全面和自适应地捕捉骨骼关节之间的长距离时空关系,从零开始训练时的3D姿态估计误差是迄今为止最低的。更重要的是,通过简单地用1-2个线性层微调预训练的运动编码器,所提出的框架在所有三个下游任务上实现了最先进的性能,这证明了学习的运动表示的通用性。
框架概述。拟议框架包括两个阶段。在预训练阶段,我们从各种运动数据源中提取2D骨架序列。然后,我们通过应用随机掩码和噪声来破坏2D骨架,从中训练运动编码器以恢复3D运动。在微调阶段,我们通过联合优化预训练的运动编码器和几个线性层,使学习的运动表示适应不同的下游任务。
模型架构。我们提出了双流时空变换器(DSTformer)作为人体运动分析的通用主干。DSTformer由N个双流融合模块组成。每个模块包含空间或时间MHSA和MLP的两个分支。空间MHSA对时间步长内不同关节之间的连接进行建模,而时间MHSA对一个关节的运动进行建模。
在设计统一的预训练框架时,我们解决了两个关键挑战:1)如何使用通用pretext任务学习强大的运动表示。2) 如何利用各种格式的大规模但异构的人体运动数据。对于第一个挑战,我们遵循语言和视觉建模中的预训练模型来构建监督信号,即屏蔽部分输入并使用编码表示来重建整个输入。注意,这种“完形填空”任务自然存在于人体运动分析中,即从2D视觉观察中恢复丢失的深度信息,即3D人体姿态估计。受此启发,我们利用大规模3D mocap数据,设计了一个2D到3D提升借口任务。我们首先通过正交投影3D运动来提取2D骨架序列x。然后,我们通过随机屏蔽和添加噪声来破坏x,以产生破坏的2D骨架序列,这也类似于2D检测结果,因为它包含遮挡、检测失败和错误。 关节级别和帧级别遮罩都以一定的概率应用。我们使用前面提到的运动编码器来获得运动表示E并重建3D运动X。然后,我们计算了X和GT 3D运动X之间的关节损失L3D。
对于第二个挑战,我们注意到2D骨架可以作为通用媒体,因为它们可以从各种运动数据源中提取。我们进一步将野生RGB视频合并到2D到3D提升框架中,以进行统一的预训练。对于RGB视频,2D骨架x可以通过手动注释或2D姿态估计器给出,并且提取的2D骨架的深度通道本质上是“掩蔽的”。类似地,我们添加额外的掩码和噪声来降低x(如果x已经包含检测噪声,则只应用掩码)。由于3D运动GT X不适用于这些数据,我们应用加权2D重投影损失。
# Uplift and Upsample(2023 WACV)
Uplift and Upsample: Efficient 3D Human Pose Estimation with Uplifting Transformers
视频中单目3D人体姿态评估的最新技术是由2D到3D姿态提升的范式主导的。虽然提升方法本身相当有效,但真正的计算复杂性取决于每帧2D姿态估计。在本文中,我们提出了一种基于Transformer的姿态提升方案,该方案可以对时间稀疏的2D姿态序列进行操作,但仍然生成时间密集的3D姿态估计。我们展示了屏蔽令牌建模如何用于Transformer块内的时间上采样。这允许将输入2D姿态的采样率与视频的目标帧速率解耦合,并且显著降低了总计算复杂性。此外,我们还探讨了对大型运动捕捉档案进行预训练的操作,这一操作迄今为止一直被忽视。我们在两个流行的基准数据集上评估了我们的方法:Human3.6M和MPI INF-3DHP。在MPJPE分别为45.0mm和46.9mm的情况下,我们提出的方法可以与现有技术相比,同时将推断时间减少了12倍。这使得固定和移动应用中的可变消费硬件能够实现实时吞吐量。
# HDFormer(2023)
HDFormer: High-order Directed Transformer for 3D Human Pose Estimation
# HSTFormer(2023)
HSTFormer: Hierarchical Spatial-Temporal Transformers for 3D Human Pose Estimation
基于变换器的方法已被成功地提出用于从2D姿态序列进行3D人体姿态估计(HPE),并实现了最先进的(SOTA)性能。然而,当前的SOTA在同时建模不同级别关节的时空相关性方面存在困难。这是由于姿态的时空复杂性。姿态以各种速度临时移动,各种关节和身体部位在空间上移动。因此,切块变压器是不适应性的,很难满足“野外”的要求。为了缓解这一问题,我们提出了分层时空变换器(HSTFormer),以从局部到全局逐渐捕捉多层次关节的时空相关性,从而实现精确的3D HPE。HSTFormer由四个变压器编码器(TE)和一个融合模块组成。据我们所知,HSTFormer是第一个研究多层次融合的分层TE的公司。在三个数据集(即Human3.6M、MPI-INF-3DHP和HumanEva)上进行的大量实验表明,HSTFormer在各种规模和困难的基准上实现了具有竞争力和一致性的性能。具体而言,它通过高度通用的系统方法,在具有挑战性的MPI-INF-3DHP数据集和小规模HumanEva数据集上超越了最近的SOTA。
# DiffPose(2023 CVPR)2️⃣
DiffPose: Toward More Reliable 3D Pose Estimation
效果优于MixSTE
# D3DP(2023)
Diffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation
# StridedPoseGraphFormer(2023 IJCNN)
Occlusion Robust 3D Human Pose Estimation with StridedPoseGraphFormer and Data Augmentation
# PoseFormerV2(2023 CVPR)
PoseFormerV2: Exploring Frequency Domain for Efficient and Robust 3D Human Pose Estimation
# 其他
ConvFormer: Parameter Reduction in Transformer Models for 3D Human Pose Estimation by Leveraging Dynamic Multi-Headed Convolutional Attention(2023)
Monocular 3D Human Pose Estimation for Sports Broadcasts using Partial Sports Field Registration(2023)
Global Adaptation meets Local Generalization: Unsupervised Domain Adaptation for 3D Human Pose Estimation(2023)
SportsPose - A Dynamic 3D sports pose dataset(2023)
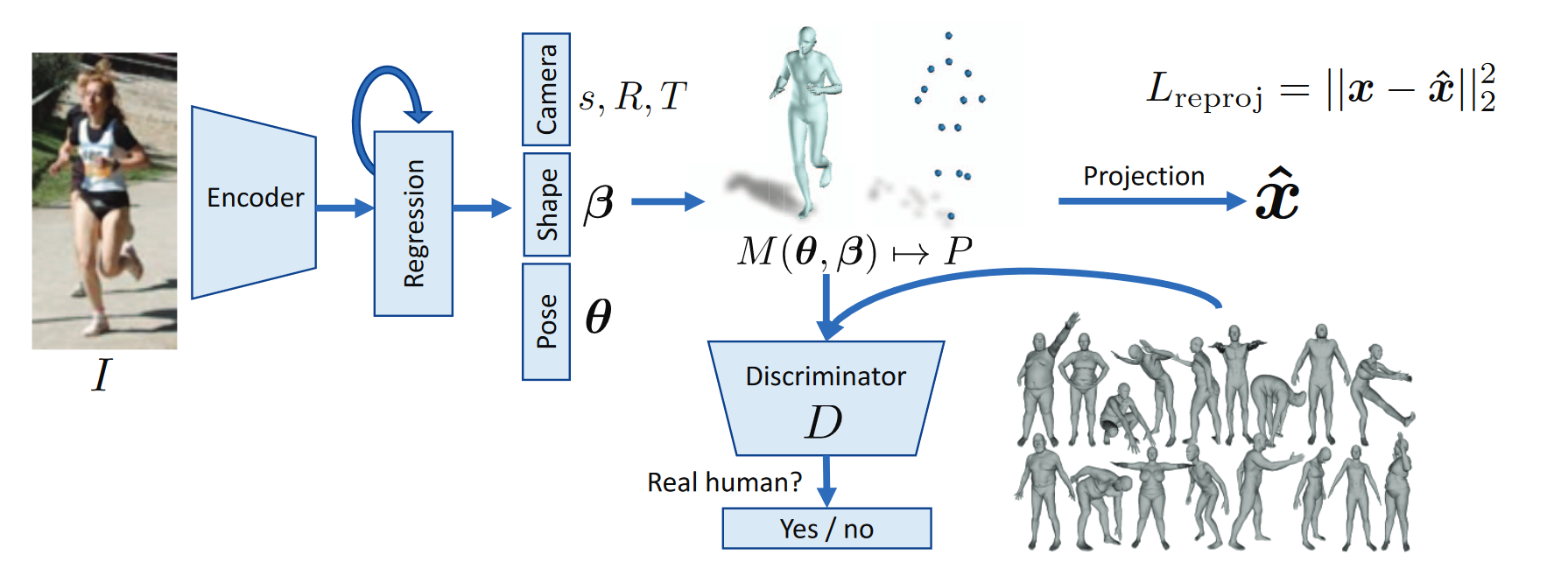
# Human Mesh Recovery (HMR)
# End-to-end recovery of human shape and pose(2018 CVPR)
# 人体骨骼先验约束
# Pose-Conditioned Joint Angle Limits for 3D Human Pose Reconstruction(2015 CVPR)
# A Kinematic Chain Space for Monocular Motion Capture(2018 ECCV)
# 3D-HPE数据集
# Human3.6M✔
Human3.6M 数据集介绍及下载_Xavier Jiezou的博客-CSDN博客_h36m数据集 (opens new window)
# 1. 介绍
Human3.6M是最广泛使用的单人3D人体姿态基准。使用4台RGB摄像机、1台飞行时间传感器和10台运动摄像机在4m×3m的室内空间中捕获数据集。它包含360万个3D人体姿态和15种场景中的相应视频(50 FPS),如讨论、坐在椅子上、拍照等。视频分辨率为1000×1000像素。特别是,人体24个关键点的3D位置和角度都可用。目前,由于隐私问题,只有7名受试者的数据可用。为了评估,视频通常按第5/64帧进行下采样,以消除冗余。
方法通常根据两种常用方案进行评估,以进行比较。
protocol #1:是对5名受试者(S1、S5、S6、S7、S8)进行训练,并对受试者S9和S11进行测试。在根部(中央髋关节)关节对齐后,我们报告了所有关节和相机坐标下的真实值与预测值之间的平均误差(毫米)。
protocol #2:共享相同的训练/测试集,但增加了刚体变换的后处理操作,将预测骨骼与真实值先对齐再计算误差。
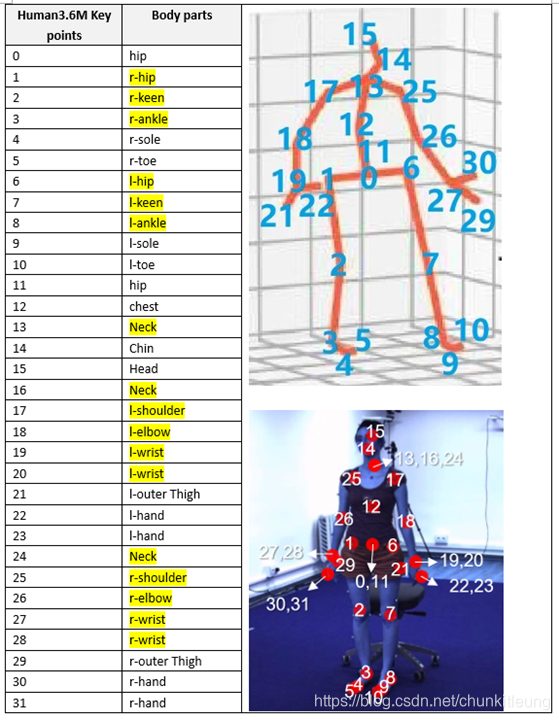
一共32个关键节点,只使用其中17个


# 2. 获取
在官网 (opens new window)下载的话需要使用教育邮箱注册账号并等待审核,审核速度非常慢。
https://github.com/MendyD/human36m.git 里面是h5类型的文件
SemGCN/data at master · garyzhao/SemGCN (github.com) (opens new window)
其他推荐方式下载:
# Download H36M annotations
mkdir data
cd data
wget http://visiondata.cis.upenn.edu/volumetric/h36m/h36m_annot.tar
tar -xf h36m_annot.tar
rm h36m_annot.tar
# Download H36M images
mkdir -p h36m/images
cd h36m/images
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S1.tar
tar -xf S1.tar
rm S1.tar
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S5.tar
tar -xf S5.tar
rm S5.tar
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S6.tar
tar -xf S6.tar
rm S6.tar
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S7.tar
tar -xf S7.tar
rm S7.tar
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S8.tar
tar -xf S8.tar
rm S8.tar
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S9.tar
tar -xf S9.tar
rm S9.tar
wget http://visiondata.cis.upenn.edu/volumetric/h36m/S11.tar
tar -xf S11.tar
rm S11.tar
cd ../../..
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 3. 进展
# MPI-INF-3DHP✔

上面提到,Human3.6M 尽管数据量大,但场景单一。为了解决这一问题,MPI-INF-3DHP 在数据集中加入了针对前景和背景的数据增强处理。具体来说,其训练集的采集是借助于多目相机在室内绿幕场景下完成的,对于原始的采集数据,先对人体、背景等进行分割,然后用不同的纹理替换背景和前景,从而达到数据增强的目的。测试集则涵盖了三种不同的场景,包括室内绿幕场景、普通室内场景和室外场景。因此,MPI-INF-3DHP 更有助于评估算法的泛化能力。

在评价标准方面,除了 MPJPE,该数据集也把 2D HPE 中广泛使用的 Percentage of Correct Keypoints (PCK) 和 Area Under the Curve (AUC) 扩展到了 3D HPE 中。其中 PCK 是误差小于一定阈值(150 mm)的关键点所占的百分比,AUC 则是 PCK 曲线下的面积。
MPI-INF-3DHP是在14摄像机工作室中使用商用无标记运动捕捉设备捕捉的,用于获取地面真实三维姿态。它包含8名演员(4名男性和4名女性),执行8项活动。从广泛的视点记录RGB视频。从所有14台摄像机捕获了超过130万帧,覆盖了广泛的视点。除了安装在胸部或更高位置的周围10个摄像机外,三个摄像机具有自顶向下的视图,最后一个摄像机位于膝盖高度,向上倾斜。除了一个人的室内视频外,他们还提供了MATLAB代码,通过混合分割的前景人像来生成多人数据集MuCo-3DHP。通过提供的身体部位分割,研究人员还可以使用额外的纹理数据交换衣服和背景。
训练测试设置:之前工作在14个关节骨架上,考虑了训练集中的所有8个演员,并从总共8个摄像机视图中选择序列(5个胸前高摄像机、2个头高摄像机和1个膝盖高摄像机)进行训练。评估是在独立的MPIINF-3DHP测试集上执行的,该测试集与训练集具有不同的场景、相机视图和相对不同的操作。此设计隐式涵盖了跨数据集评估。
MPI-INF-3DHP测试集提供了三种不同场景的图像:带绿色屏幕的工作室(GS)、无绿色屏幕的studio(noGS)和室外场景(户外)。我们使用这个数据集来测试我们提出的架构的泛化能力。(在Human3.6M训练)
另一种使用该数据集的方式是仅使用其测试集来评估模型的泛化性,例如在Human3.6M下训练的模型测试
PoseAug/DATASETS.md at main · jfzhang95/PoseAug (github.com) (opens new window)
chenxuluo/OriNet-demo: The testing code for OriNet (github.com) (opens new window)🉑
# HumanEva-I
HumanEva Dataset (mpg.de) (opens new window)
HumanEva-I是一个小型数据集,包含3个对象(S1、S2、S3),与Human3.6M相比,具有3个摄像头视图(在场景的前部、左侧和右侧)和更少的动作。这是一个标准的三维姿态估计数据集,用于以前的工作中的基准测试。
根据协议,我们在HumanEva-I上评估了我们的模型。训练使用不同视角和动作序列(慢跑和步行)的受试者S1、S2、S3,同时对所有三个受试者的验证序列进行测试,作为测试数据。所有模块均使用HumanEva-I进行训练。