 Graph Transformers
Graph Transformers
# Graph Transformers
# 介绍
GCN与Transformer的融合
没有位置编码层的 Transformer 是置换不变的,并且 Transformer 还具有良好的可扩展性,因此研究人员在近期开始考虑将 Transformers 应用于图中。大多数方法的重点是通过寻找最佳特征和最佳方式来表示图形,并改变注意力以适应这种新数据。
将 Transformer 用于图在很大程度上仍处于起步阶段,但就目前来看,其前景也十分可观,它可以缓解 GNN 的一些限制,例如缩放到更大或更密集的图,或是在不过度平滑的情况下增加模型大小。
图上不同的 transformers 的主要区别在于(1)如何设计 PE,(2)如何利用结构信息(结合 GNN 或者利用结构信息去修正 attention score, etc)。
参考资料:
一文带你浏览Graph Transformers - 知乎 (zhihu.com) (opens new window)
图机器学习无处不在,用 Transformer 可缓解 GNN 限制 | 雷峰网 (leiphone.com) (opens new window)
一文带你浏览Graph Transformers_PaperWeekly的博客-CSDN博客 (opens new window)
# 综述
Transformer for Graphs: An Overview from Architecture Perspective
A Bird’s-Eye Tutorial of Graph Attention Architectures
# 文献
# GTNs(2019 NeurIPS)
Graph Transformer Networks
用于学习异构图上的节点表示,方法是将异构图转换为由元路径定义的多个新图,这些元图具有任意边类型和任意长度,通过在学习的元路径图上进行卷积来表示节点。
(非Transformer)
# GTOS(2020 AAAI)
Graph Transformer for Graph-to-Sequence Learning
动机: 先前 的GNN的缺陷: (1)固有的局部传播更新自然而然地排除了一些有效的全局交互,不利于大规模的图或当两个结点距离很远的情况;
假设对一个图结构进行训练,迭代次数设置为L,因此对于每个结点其只能有机会与其在L 跳数之内的所有结点实现直接的信息交互,而超过范围的结点之间信息得不到显式的交互。这类似于在RNN及其相关变体中存在的梯度消失问题。
(2)尽管两个结点能够在一定距离范围内可达,而由于过长距离信息也会被削弱;
当然第一种情况可以避免,例如增加迭代次数,另外即便在一定跳数范围内信息得不到直接交互,但通过中间部分结点也可以实现简介的信息交互,但可想而知过长的距离使得这些信息变得非常的稀疏;
(3)Transformer:完全以Attention实现对不同成分之间的进行显式的信息交互,不受到长距离的限制。但现有的Transformer模型均只在序列模型上得以验证,而并没有在图结构上进行应用。
Transformer的思想是将每个结点抽象为一个全连接图,每个结点均可以与所有结点进行信息交互,但它们的交互并没有融入实际的结点与结点见的关系relation,特别是对于像依存句法树(Dependency Tree,DP)和抽象语义表示(Abstract Mean Representation,AMR)等富含边信息。因此需要模型能够显式地学习这些边的信息的同时,不受到距离约束的影响。
本文提出一种Graph Transformer模型,主要解决两个问题:
(1)先期GNN及其变种模型中没有解决的结点之间长距离信息交互问题,我们将输入的图抽象为一个全连接图,因此可以借助Transformer的特性来实现;因此每个结点都可以获得其他所有结点的信息,不会受到距离限制;
(2)先前图表征模型并没有对关系边信息进行表示,部分方法将边视为一个结点,但这依然不能全面的提取图的全局信息,因此我们需要引入对关系的表征来避免信息的稀疏性;由于有些结点之间并不是单跳内可达,因此为了能够表示任意两个结点之间的关系,使用最短路径来表示,因此引用GRU来实现关系的表征。
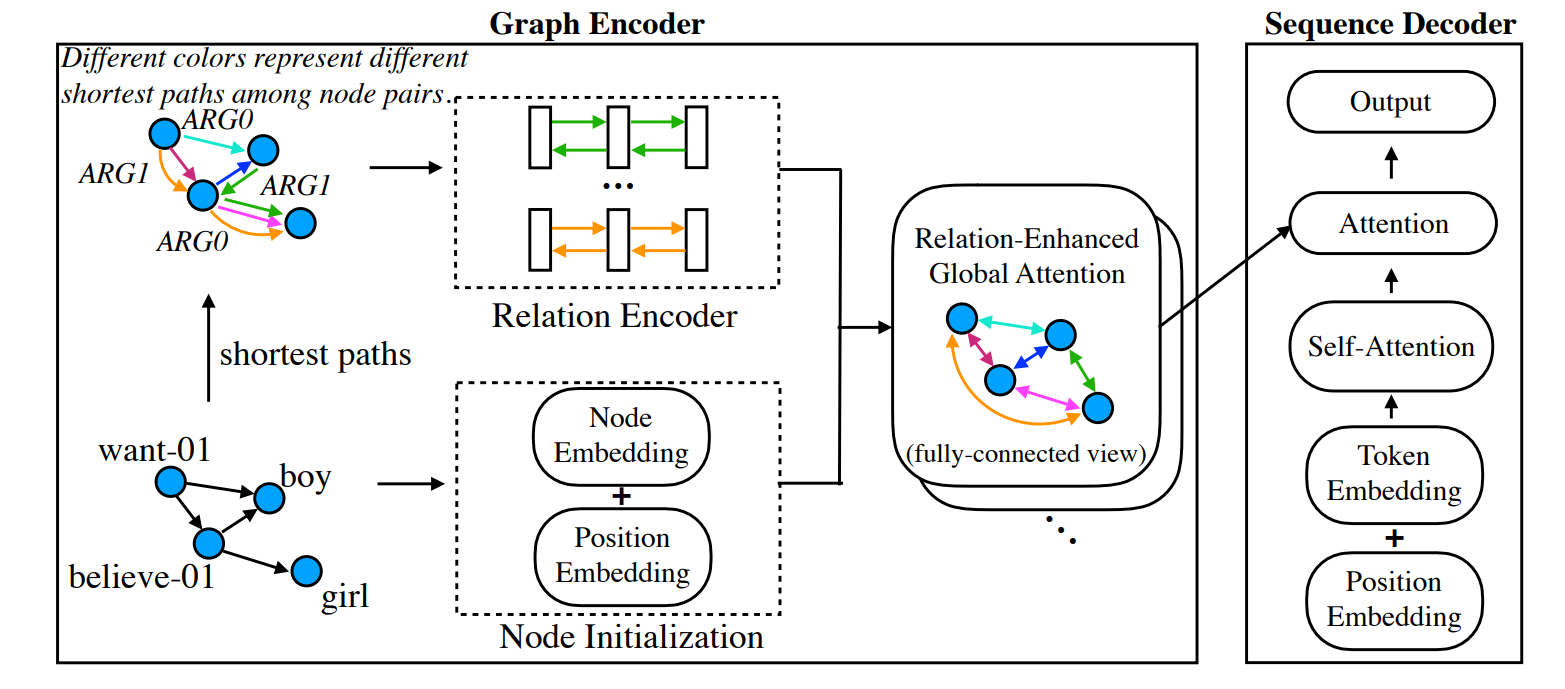
总结: 本文提出一种图表示方法,旨在解决先前的GNN-based方法只考虑到单跳(one-hop/first-order)范围内的结点的信息聚集,而忽略对长距离的结点信息交互的问题,提出的Graph Transformer方法则可以实现每个结点之间进行显式地信息交互,并将结点之间的最短路径关系表征作为保留图结构信息的依据。 缺点则在于不适用于大规模的图训练,因为Transformer之所以速度快是因为使用可并行处理的attention,而本文将关系路径使用GRU进行编码,直接破坏了attention带来的优势,使得计算量进一步增加。
# GT(2021 AAAI Workshop)
A Generalization of Transformer Networks to Graphs
Graph Transformer——合理灌水 - 知乎 (zhihu.com) (opens new window)
Laplacian PE - 知乎 (zhihu.com) (opens new window)
graph_transformer_edge_layer介绍详细参考代码:graphtransformer/graph_transformer_edge_layer.py at main · graphdeeplearning/graphtransformer (github.com) (opens new window)
作者提出了一种适用于任意图的transformer神经网络结构的推广方法。原始的transformer是建立在全连接的图上,这种结构不能很好地利用图的连通归纳偏置——arbitrary and sparsity,即把transformer推广到任意图结构,且表现较弱,因为图的拓扑结构也很重要,但是没有融合到节点特征中。 作者提出新的graph transformer,带有以下四个新特征:
在每个node的可连通临域做attention。
positional encoding用拉普拉斯特征向量表示。
用BN(batch normalization)代替LN(layer normalization),优点:训练更快,泛化性能更好。
将结构扩展到边特征表示.此架构简单而通用,作者相信它可以作为黑盒,应用在transformer和graph的application中。
# GraphTrans(2021 NeurIPS)
Representing Long-Range Context for Graph Neural Networks with Global Attention
# SAN(2021 NeurIPS)
Rethinking Graph Transformers with Spectral Attention
近年来,Transformer架构已被证明在序列处理中非常成功,但由于难以正确定义位置,它在其他数据结构(如图形)中的应用仍然有限。在这里,我们提出了光谱注意力网络(SAN),它使用学习的位置编码(LPE),可以利用全拉普拉斯谱来学习给定图中每个节点的位置。然后将此LPE添加到图形的节点特征中,并传递给完全连接的Transformer。
通过利用拉普拉斯算子的全谱,我们的模型在理论上在区分图方面是强大的,并且可以更好地从它们的共振中检测类似的子结构。此外,通过完全连接图形,Transformer不会遭受过度挤压(大多数GNN的信息瓶颈)的困扰,并能够更好地模拟物理现象,如热传递和电相互作用。

# Graphormer(2021 NeurIPS)
Do Transformers Really Perform Bad for Graph Representation?
KDD Cup 2021 | 微软亚洲研究院Graphormer模型荣登OGB-LSC图预测赛道榜首 (msra.cn) (opens new window)
# SAT(2022 ICML)
Structure-Aware Transformer for Graph Representation Learning
# GraphGPS(2022 NeurIPS)
Recipe for a General, Powerful, Scalable Graph Transformer
# GRPE(2022 ICLR Oral)
GRPE: Relative Positional Encoding for Graph Transformer
# NodeFormer (2022 NeurIPS)
NodeFormer: A Scalable Graph Structure Learning Transformer for Node Classification
# TokenGT(2022 NeurIPS)
Pure Transformers are Powerful Graph Learners
# EGT(2022 KDD)
Global Self-Attention as a Replacement for Graph Convolution
# ANS-GT(2022 NeurIPS)
Hierarchical Graph Transformer with Adaptive Node Sampling
# Matformer(2022 NeurIPS)
Periodic Graph Transformers for Crystal Material Property Prediction
# Relational Attention(2023 ICLR)
Relational Attention: Generalizing Transformers for Graph-Structured Tasks