 大模型应用
大模型应用
# 大模型应用
“AI时代就是大模型时代”
“AGI(Artificial General Intelligence)是指一种能够像人类一样具有广泛认知能力的人工智能技术。与弱人工智能只能解决特定问题不同,AGI能够处理各种不同的任务,并具有学习、推理、判断和自我改进等能力,类似于人类的智能。尽管AIGC和AGI都是人工智能领域中的重要概念,但它们之间存在着明显的区别。AIGC通常专注于某个特定的任务或领域,而AGI具有更广泛的应用范围和更强的认知能力。”
# 基础知识
AI两种期待:
专用模型:对预训练模型改造(finetune、Adapter:减少微调参数)
通用模型:
hard prompt:通过范例学习(In-context Learning)、Instruction-tuning、CoT-Prompting(范例提供推理过程)Few-shot-CoT、Zero-shot-CoT(不够例子,Let's think step by step)、人类反馈的强化学习(RLHF)
soft prompt:可学习参数
将大型语言模型(LLMs)的范围扩大到文本生成之外,当代研究已经研究了两种主要方法:
一些工作设计了统一的多模态语言模型,如BLIP-2,它利用Q-former来协调语言和视觉语义,以及Kosmos-1,它将视觉输入纳入文本序列以合并语言和视觉输入。
其他研究集中在外部工具或模型的整合上:
首创的Toolformer在文本序列中引入了外部API标签,促进LLM对外部工具的访问。因此,许多工作都将LLMs扩展到了视觉模态中。
Visual ChatGPT将视觉基础模型,如BLIP和ControlNet,与LLMs融合。
视觉编程和ViperGPT通过采用编程语言将LLMs应用于视觉对象,将视觉查询解析为以Python代码表达的可解释步骤。
研究人员还努力使这些LLM适用于专门的视觉任务。例如,Prophet和ChatCaptioner分别将LLMs纳入视觉问答和图像字幕任务。
# 大型语言模型应用(LLMs)
# ChatGPT
# AutoGPT
AutoGPT:安装 - AutoGPT中文 (opens new window)
AutoGPT 运行原理解析 - 郑海波的文章 - 知乎 https://zhuanlan.zhihu.com/p/625094476
不过ChatGPT的API都是无状态的,没有对话管理的功能。
手把手教会你如何通过ChatGPT API实现上下文对话 - 知乎 (zhihu.com) (opens new window)
AutoGPT 运行原理解析 - 知乎 (zhihu.com) (opens new window)
详解下最近被吹爆的 AutoGPT - 知乎 (zhihu.com) (opens new window)
Auto-GPT 是一个实验性的开源应用程序,展示了 GPT-4 语言模型的功能。该程序由 GPT-4 驱动,将 LLM“思想”链接在一起,以自主实现您设定的任何目标。作为 GPT-4 完全自主运行的首批示例之一,Auto-GPT 突破了 AI 可能的界限。
- 🌐用于搜索和信息收集的互联网接入
- 💾长期和短期记忆管理
- 🧠用于文本生成的 GPT-4 实例
- 🔗访问热门网站和平台
- 🗃️使用 GPT-3.5 进行文件存储和摘要
- 🔌插件的可扩展性
# HuggingGPT
(HuggingFace+ChatGPT)
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face(2023)
HuggingGPT: 用ChatGPT和它的朋友在HuggingFace中解决AI任务 - 知乎 (zhihu.com) (opens new window)
利用LLM(如ChatGPT)来连接机器学习社区(如Hugging Face)中各种人工智能模型以解决人工智能任务,HuggingGPT的整个过程可以分为四个阶段:
一个LLM(如ChatGPT)首先解析用户请求,将其分解为多个任务,并根据其知识规划任务顺序和依赖性;
为了提示大语言模型进行有效的任务规划,HuggingGPT在其提示设计中同时采用了基于规范的指令(将任务规范作为高级指令提供给大语言模型,用于分析用户的请求并相应地解析任务)和基于演示的解析法(通过在提示中注入几个演示使大型语言模型能够更好地理解任务规划的意图和标准)。
LLM根据Hugging Face中的模型描述将解析后的任务分配给专家模型;
将任务和模型的分配视为单项选择问题,其中潜在的模型在给定的上下文中被作为选项提出。
专家模型在推理端点上执行分配的任务,并将执行信息和推理结果记录到LLM;
为了提高速度和计算稳定性,HuggingGPT在混合推理端点上运行这些模型。通过将任务参数作为输入,模型计算推理结果,然后将其送回大语言模型。
最后,LLM总结执行过程记录和推理结果,将总结返回给用户。
将前三个阶段(任务规划、模型选择和任务执行)的所有信息整合成一个简明的摘要,包括计划的任务列表、为任务选择的模型以及模型的推理结果。
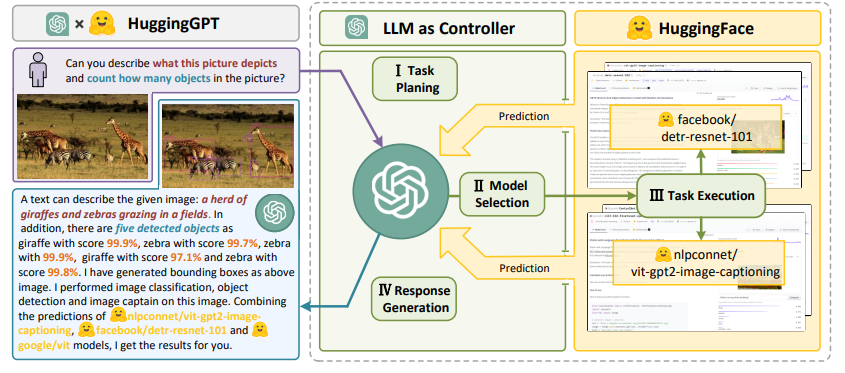
为了处理复杂的人工智能任务,LLM应该能够与外部模型协调,利用它们的力量。因此,关键点在于如何选择合适的中间件来连接LLM和AI模型。为了解决这个问题,我们注意到每个人工智能模型可以通过总结其模型功能来表示为一种语言形式。因此,我们引入一个概念: "语言是LLMs连接AI模型的通用接口"。
即HuggingGPT是一个协作系统,由一个大型语言模型(LLM)作为控制器,众多专家模型作为协作执行者组成。

HuggingGPT中提示设计的详细信息。在提示中,我们设置了一些可注射的插槽,如和{Candidate Models}}。这些槽在被馈送到LLM之前被统一地替换为相应的文本。

限制:
效率。效率的瓶颈在于大型语言模型的推理。对于每一轮的用户请求,HuggingGPT在任务规划、模型选择和响应生成阶段都需要与大型语言模型进行至少一次互动。这些互动大大增加了响应延迟,导致用户体验的下降。
最大上下文长度的限制。受LLM可以接受的最大token数的限制,HuggingGPT也面临着最大上下文长度的限制。我们使用了对话窗口,并且只在任务规划阶段跟踪对话背景,以缓解它。
系统的稳定性,这包括两个方面。一个是大型语言模型推理过程中出现的反叛现象。大型语言模型在推理时偶尔会不符合指令,输出格式也可能违背预期,导致程序工作流程出现异常。其次是Hugging Face推理端点上托管的专家模型的不可控状态。Hugging Face上的专家模型可能受到网络延迟或服务状态的影响,导致任务执行阶段的错误。
# VisualGPT
# Toolformer
# ChatLaw(2023)
# 图像生成
# 应用平台:
Midjourney(收费)
SD: Stable Diffusion超详细教程!从0-1入门到进阶 - 知乎 (zhihu.com) (opens new window)
Deforum
Deforum插件是一种基于stable diffusion的动画生成工具,它可以根据文本描述或参考视频生成连续的图像序列,并将它们拼接成视频。Deforum插件使用了一种叫做image-to-image function的技术,它可以对图像帧进行微小的变换,并用stable diffusion生成下一帧。由于帧之间的变化很小,因此会产生连续视频的感觉。
# 发展:
文本生成图像
DALL·E(2021/1)->CogView(2021/5)->NvWA(2021/11)->GLIDE(2021/12)->ERNIE-ViLG(2021/12)->DALL·E2(2022/4)->CogView2(2022/4)->CogVideo(2022/5)->Imagen(2022/5)
# 参考资料
GAN生成图像综述 - 知乎 (zhihu.com) (opens new window)
# 评价指标
GAN评价指标最全汇总 - 知乎 (zhihu.com) (opens new window)
# 1. 定性评估
该方法主要还是靠人的眼睛来进行判断。一般的做法是将真实图像和生成图像对上传到众包平台上让人来判断图像的真假,并且给出两者的相似程度,最后根据打分的结果统计一个最终的指标。
# 2. IS
# 3. FID
# 文本到图像评估
# Stable Diffusion
High-Resolution Image Synthesis with Latent Diffusion Models(2022 CVPR)
通过将图像形成过程分解为顺序应用 降噪自动编码器、扩散模型(DM)实现最先进的技术 图像数据及其他方面的合成结果。此外,它们的配方 允许使用引导机制来控制图像生成过程,而无需培训。但是,由于这些模型通常直接以像素为单位运行空间,强大的DM的优化通常需要消耗数百天的GPU和 由于顺序评估,推理成本很高。启用DM训练有限的计算资源,同时保持其质量和灵活性, 我们将它们应用于强大的预训练自动编码器的潜在空间中。在与以前的工作相比,在这种表示上训练扩散模型 允许首次达到复杂度之间的接近最佳点减少和细节保留,大大提高视觉保真度。由在模型架构中引入交叉关注层,我们转向将模型扩散到强大而灵活的发生器中,用于一般调节文本或边界框等输入以及高分辨率合成变为可能以卷积方式。我们的潜扩散模型 (LDM) 可实现 图像修复和极具竞争力的性能的新技术水平 各种任务,包括无条件图像生成、语义场景合成和超分辨率,同时显著减少计算 与基于像素的 DM 相比的要求。
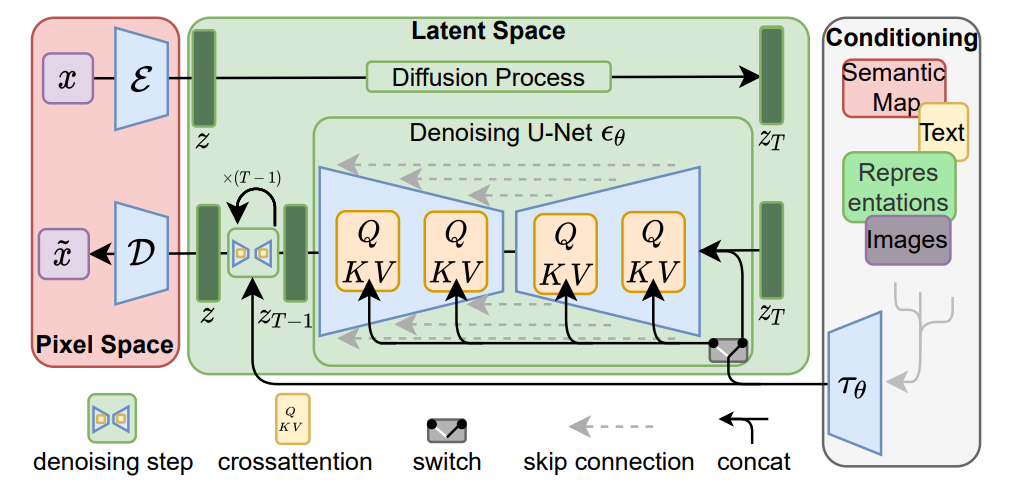
感知压缩(Perceptual Compression):首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器和一个解码器 )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可。(512,512 ,3)->(64 ,64 ,4)
条件机制(Conditioning Mechanisms):除了无条件图片生成外,我们也可以进行条件图片生成,具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现。
# DALL·E系列
Zero-Shot Text-to-Image Generation(2021 ICML) Hierarchical Text-Conditional Image Generation with CLIP Latents
DALL-E 2的工作是训练两个模型。第一个是Prior,接受文本标签并创建CLIP图像嵌入。第二个是Decoder,其接受CLIP图像嵌入并生成图像。模型训练完成之后,推理的流程如下:
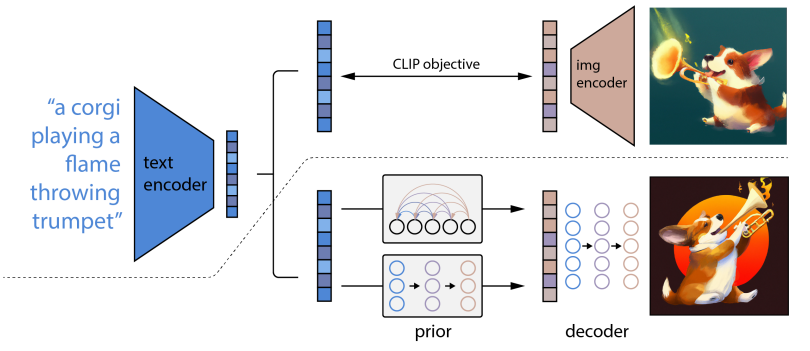
输入的文本被转化为使用神经网络的CLIP文本嵌入。
使用文本嵌入创建图像嵌入。(先验模型,扩散模型效果及效率更优)Transformer/U-Net+attension
进入Decoder步骤后,扩散模型被用来将图像嵌入转化为图像。(GLIDE修改版)
两个Diffusion Model: 网络结构是U-Net。图像被从64×64放大到256×256,最后放大到1024×1024。
我们使用ADMNet体系结构作为上采样器。在第一个上采样阶段,我们使用余弦噪声处理计划,在ADMNet内使用320个通道和每个分辨率3个resblock的深度。我们还应用了高斯模糊(核大小3,西格玛0.6)。在第二个上采样阶段,我们使用线性噪声计划,192个通道,每个分辨率2个resblock的深度,并根据Rombach等人[42]的BSR退化进行训练。两个上采样器都没有使用注意力。 为了减少推理时间,我们使用DDIM并手动调整步数,256×256模型为27步,1024×1024模型为15步。
# Imagen
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
我们展示了Imagen,这是一个文本到图像的扩散模型,具有前所未有的真实感和深入的语言理解。Imagen建立在大型转换语言模型理解文本的能力之上,并取决于高保真图像生成中扩散模型的强度。我们的关键发现是,在纯文本语料库上预训练的通用大型语言模型(例如T5)在编码用于图像合成的文本方面出奇地有效:增加Imagen中语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像文本对齐。 Imagen在COCO数据集上获得了7.27的新的最先进的FID分数,而从未对COCO进行过训练,并且人类评分者发现Imagen样本在图像-文本对齐方面与COCO数据本身不相上下。为了更深入地评估文本到图像模型,我们引入了DrawBench,这是一个全面且具有挑战性的文本到图像建模基准。使用DrawBench,我们将Imagen与最近的方法进行了比较,包括VQ-GAN+CLIP、Latent Diffusion Models,、GLIDE和DALL-E2,并发现在并排比较中,无论是在样本质量还是图像文本对齐方面,人类评分者都更喜欢Imagen而不是其他模型。
# Prompt工程/技巧
Prompting: Prefix-Tuning: Optimizing Continuous Prompts for Generation
《ChatGPT Prompt Engineering for Developers》课程笔记 - 知乎 (zhihu.com) (opens new window)
# 视频生成
# 相关模型
参考资料:
基于Diffusion的精细化可控图片生成【论文+效果分析】 - 知乎 (zhihu.com) (opens new window)
# LoRA(2021)
LoRA: Low-Rank Adaptation of Large Language Models
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码 - 知乎 (zhihu.com) (opens new window)
# ControlNet(2023)
Adding Conditional Control to Text-to-Image Diffusion Models
我们提出了一种神经网络结构ControlNet,用于控制预先训练的大型扩散模型,以支持额外的输入条件。ControlNet以端到端的方式学习特定任务的条件,即使训练数据集很小(<50k),学习也很稳健。此外,训练ControlNet与微调扩散模型一样快,并且可以在个人设备上训练该模型。 或者,如果有强大的计算集群可用,该模型可以扩展到大量(数百万到数十亿)的数据。我们报告说,像stable diffusion这样的大型扩散模型可以用ControlNets来增强,以实现条件输入,如边缘图、分割图、关键点等。这可能会丰富控制大型扩散模型的方法,并进一步促进相关应用。
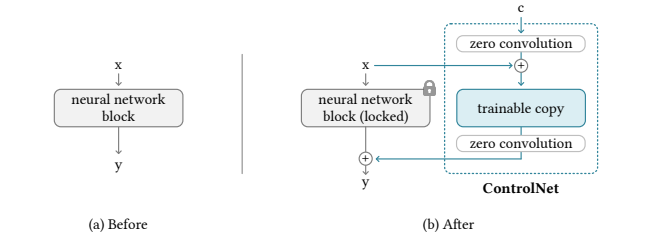
ControlNet in Stable Diffusion

# BLIP
# RePaint(2022 CVPR)
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
RePaint修改了标准去噪过程,以便对给定的图像内容进行调节。在每一步中,我们对输入的已知区域(顶部)和DDPM输出的修复部分(底部)进行采样。
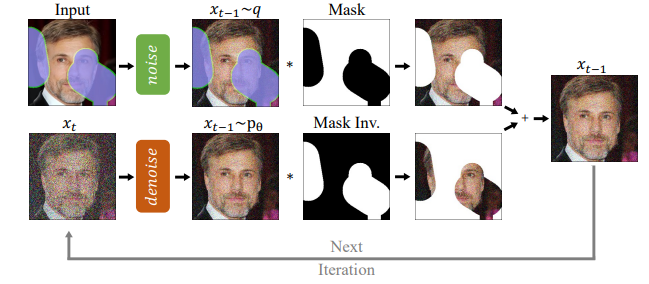
当直接应用描述的方法时,我们观察到只有内容类型与已知区域匹配。例如下图 n=1中,绘制区域是一个与狗的毛发相匹配的毛茸茸的纹理。尽管修复的区域与相邻区域的纹理匹配,但在语义上是不正确的。因此,DDPM利用了已知区域的上下文,但它并没有很好地将其与图像的其余部分协调起来。 该模型使用xt预测xt−1,xt包括DDPM的输出和来自已知区域的样本。然而,对已知像素进行采样是在不考虑图像的生成部分的情况下进行的,这会引入不和谐。尽管模型在每一步都试图再次协调图像,但它永远无法完全收敛,因为下一步会出现同样的问题。此外,在每个反向步骤中,由于βt的变化时间表,图像的最大变化逐渐减少。因此,由于灵活性有限,该方法无法纠正导致后续步骤中不和谐界限的错误。因此,在进入下一个去噪步骤之前,模型需要更多的时间在一个步骤中协调条件信息x已知t−1和生成的信息x未知t−1。
由于DDPM被训练来生成位于数据分布中的图像,因此它自然旨在产生一致的结构。在我们的重采样方法中,我们使用这种DDPM特性通过多次迭代来协调模型的输入。


# SDEdit(2022 ICLR)
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
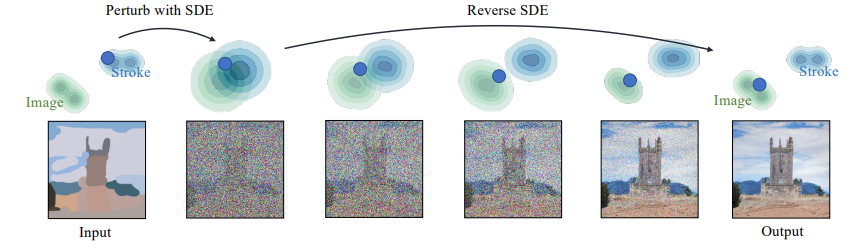
使用SDEdit从笔划合成图像。蓝点说明了我们方法的编辑过程。绿色和蓝色轮廓图分别表示图像和笔划绘画的分布。给定一个笔划绘制,我们首先用高斯噪声对其进行扰动,并通过模拟反向SDE逐渐去除噪声。这个过程逐渐将一幅不切实际的笔触画投射到自然图像的流形上。

# VQGAN
# VQVAE
# Guided Diffusion
# VQ-Diffusion(2022 CVPR)
Vector quantized diffusion model for text-to-image synthesis
# GLIDE
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
扩散模型最近被证明可以生成高质量的合成图像,尤其是当与guidance技术相结合时,以牺牲多样性来换取保真度。我们探索了文本条件图像合成问题的扩散模型,并比较了两种不同的引导策略:CLIP guidance and classifier-free guidance。我们发现,后者在照片真实性和帽子相似性方面都是人类评估者的首选,并且经常产生照片真实性样本。与DALL-E的样本相比,使用classifier-free guidance的35亿参数文本条件扩散模型的样本更受人类评估者的青睐,即使后者使用昂贵的CLIP重新排序。此外,我们发现我们的模型可以进行微调以执行图像修复,从而实现强大的文本驱动图像编辑。
# DragGAN
# 条件控制扩散模型
Classifier-Guidance: Diffusion Models Beat GANs on Image Synthesis(2022 NIPS)
Classifier-Free: Classifier Free Diffusion Guidance(2021 NIPS)
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
浅谈扩散模型的有分类器引导和无分类器引导 - 知乎 (zhihu.com) (opens new window)
生成扩散模型漫谈(九):条件控制生成结果 - 科学空间|Scientific Spaces (opens new window)
扩散模型的引导生成的三种做法的区别。
用显式分类器引导生成的做法
用隐式无分类器引导的做法
用CLIP计算跨模态间的损失来引导生成的做法。
# SR3(2023 TPAMI)
Image Super-Resolution via Iterative Refinement
# Improved DDPM
Improved denoising diffusion probabilistic models
贡献:
损失函数的改进:DDPM中的方差是很难学习的,因此其忽略了方差项,令方差为一个常数,使其方差不是一个可学习的对象。相反,IDDPM引入方差项的学习,损失项加上了一项惩罚。
噪声机制使用cos:DDPM的方差是一个linear schedule,
的值变化如下图所示。可以看到,linear 的方式使得图片加噪的太快。因此为了让扩散过程中能够保证更多的细节,IDDPM改进了schedule,采用cosine schedule。
(线性噪声机制对于高分辨率图像很好,在分辨率小的图像上结果次优。ddpm中的前向加噪过程对采样过程没有太大的贡献。)

# Stable Diffusion、LORA、ControlNet之间的联系与区别?
Stable Diffusion是一种基于扩散模型的图像生成方法,可以通过文本等条件来控制图像的内容和风格¹ (opens new window)。ControlNet是一种神经网络结构,可以通过添加额外的条件来控制扩散模型的空间信息,例如边缘检测或人体姿态检测(参考 (opens new window)、ControlNet v1.1 (opens new window))。LORA是一种轻量级的网络,可以对扩散模型的CLIP模型和Unet的CrossAttention的线性层进行微调,从而提高图像生成的质量和多样性(参考 (opens new window))。
简单来说,stable diffusion可以接受文本等条件去生成图像,controlnet可以让用户更精确地控制图像的布局和结构,LORA可以提升图像生成的效果和效率。这三者都是在扩散模型的基础上进行改进和拓展的方法。
举例说明:
stable diffusion可以根据文本生成图像,例如输入“a bird”就可以生成一只鸟的图像。但是stable diffusion不能控制图像的具体形状和位置,只能随机生成。
controlnet可以在stable diffusion的基础上添加额外的条件,例如一个边缘检测或人体姿态检测的图像,来控制生成图像的空间信息。例如,如果输入“a bird”和一个边缘检测图像,controlnet就可以生成一只鸟的图像,并且让它的形状和位置与边缘检测图像相匹配。
LORA可以在stable diffusion的基础上对CLIP模型和Unet的CrossAttention的线性层进行微调,从而提高图像生成的质量和多样性。例如,如果输入“a bird”,LORA就可以生成一只鸟的图像,并且让它更清晰和逼真。
更具体的说,LORA可以通过使用不同风格的图像微调来改变或控制图像生成的风格,例如“毕加索风格的鸟”¹ (opens new window)。这样可以使得stable diffusion可以生成更多有意思的图像。
其他一些使用LORA进行风格转换的例子:
- 使用水彩风格的LORA生成水彩画效果的图像² (opens new window)
- 使用漫画线稿风格的LORA生成线稿或填色本效果的图像² (opens new window)
- 使用塔罗牌风格的LORA生成复杂细致的塔罗牌插画效果的图像² (opens new window)
- 使用多个不同风格的LORA混合生成自定义风格的图像3 (opens new window)
这些例子只是展示了LORA的一部分功能,还可以尝试使用其他风格或主题的LORA来创造您想要的图像。
# FateZero(2023 ICCV)
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing